无论是需要将零散的业务报告汇总,还是将多份合同扫描件整合成一个文件,掌握合并 pdf 的技巧都是提升办公效率的必备技能。本文将介绍如何在 java 中使用 spire.pdf 库高效合并 pdf 文件。我们从基础的文件合并出发,进阶到特定页面的提取合并,并针对合并过程中涉及的加密处理、体积压缩等问题提供有效的解决方案。
环境准备
在开始代码实现之前,我们需要先搭建好开发环境。由于我们要处理复杂的 pdf 结构,spire.pdf 作为一个稳定且功能齐全的第三方库可以极大提高效率。
你可以通过 maven 仓库轻松引入 spire.pdf。在你的 pom.xml 文件中添加以下配置:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupid>e-iceblue</groupid>
<artifactid>spire.pdf</artifactid>
<version>12.4.4</version>
</dependency>
</dependencies>也可以下载安装包,手动将 spire.pdf 添加到项目中。此外该组件还提供免费版,适合用于小型项目。
在 java 中合并 pdf 的两种常见情景
在处理 pdf 合并时,我们通常面临两种场景:一种是直接将几个文档头尾相接;另一种则是像拼图一样,只提取每个文档中的特定页面进行组合。下面我们针对两种不同的情况分别来讲解如何借助 spire.pdf 来完成 pdf 组合。
快速合并多个完整 pdf 文档
如果你手头有几个完整的 pdf 文件需要按顺序连在一起,spire.pdf 提供了一个非常高效的方法,只需一行核心代码即可完成。
import com.spire.pdf.fileformat;
import com.spire.pdf.pdfdocument;
import com.spire.pdf.pdfdocumentbase;
public class mergepdfs {
public static void main(string[] args) {
// 获取待合并的pdf文档路径
string[] files = new string[] {"/示例文档1.pdf", "/示例文档2.pdf", "/示例文档3.pdf"};
// 合并这些pdf文档
pdfdocumentbase pdf = pdfdocument.mergefiles(files);
// 保存合并后的pdf文件
pdf.save("/output/合并pdf文档.pdf", fileformat.pdf);
}
}
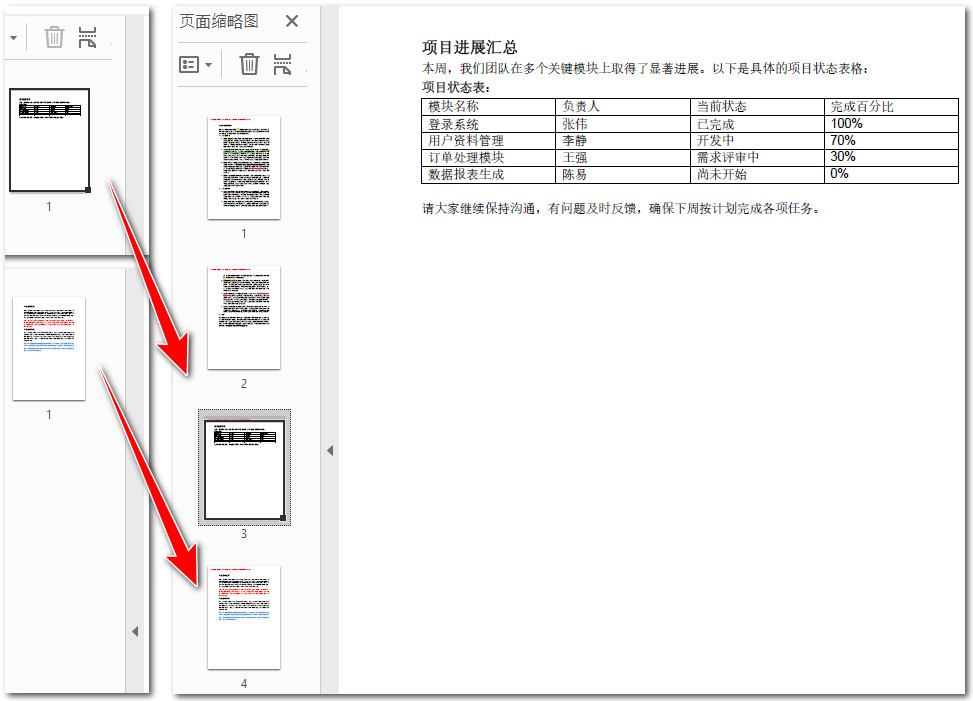
代码步骤解析:
- 准备数据源: 定义一个字符串数组,按顺序存放所有需要合并的源文件路径。
- 合并 pdf: 调用
pdfdocument.mergefiles(files)方法。该方法会自动按数组索引顺序读取文件并合并。 - 持久化保存: 调用
save()方法保存合并结果,并指定输出格式为 pdf。
精确合并不同 pdf 文档的指定页面
在实际工作中,我们可能不需要整份文档。例如,只需要 a 文档的封面、b 文档的正文以及 c 文档的盖章页。这时候,我们需要通过页面插入的方式来控制合并结果。
import com.spire.pdf.pdfdocument;
public class mergeselectedpages {
public static void main(string[] args) {
// 获取待合并的pdf文档路径
string[] files = new string[] {"sample1.pdf", "sample2.pdf", "sample3.pdf"};
// 创建pdfdocument类型的数组
pdfdocument[] pdfs = new pdfdocument[files.length];
// 遍历并加载文档
for (int i = 0; i < files.length; i++) {
pdfs[i] = new pdfdocument(files[i]);
}
// 创建一个新的pdf文档容器
pdfdocument pdf = new pdfdocument();
// 将不同pdf中的指定页面插入到新pdf中
pdf.insertpage(pdfs[0], 0); // 插入第一个文件的第1页
pdf.insertpagerange(pdfs[1], 1, 3); // 插入第二个文件的第2到4页
pdf.insertpage(pdfs[2], 0); // 插入第三个文件的第1页
// 保存合并后的pdf文件
pdf.savetofile("合并指定页面.pdf");
}
}
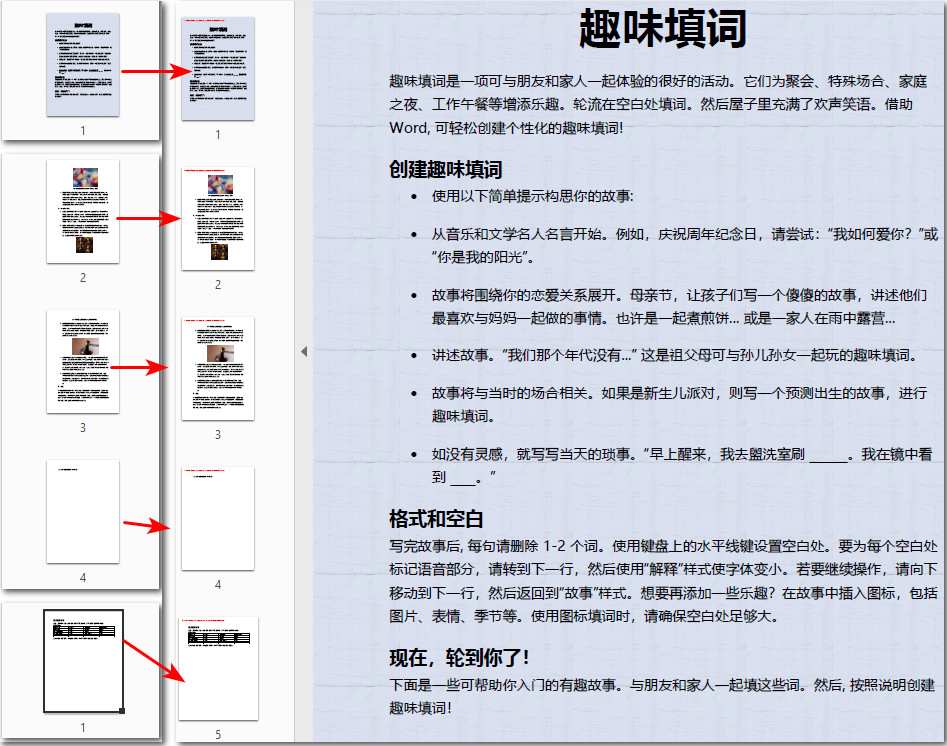
代码步骤解析:
- 加载源文件: 通过循环遍历数组,为每一个源文件创建一个
pdfdocument实例。 - 初始化容器: 创建一个新的
pdfdocument对象pdf,用来存放合并结果。 - 按需提取:
insertpage(sourcedoc, index):用于提取单页(注意索引从 0 开始)。insertpagerange(sourcedoc, start, end):用于批量提取一个范围内的页面,避免了写循环的麻烦。
- 输出结果: 最后调用
savetofile()将合并后的结果保存为 pdf 文档。
进阶实战与避坑指南
学会了基础合并逻辑后,你可能会在实际运用时遇到一些棘手问题:比如文件加密了怎么办?合并后的文件太大发不出去怎么办?如何给合并后的文件统一标识?本章将逐一攻克这些难点。
合并前的安全处理
如果源文档受到密码保护,直接尝试读取会触发异常。在合并这类文件前,必须先进行解锁操作。
// 使用密码载入加密的pdf文档
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("加密.pdf", "password");
// 解密文档,确保后续合并操作不会因权限限制失败
pdf.decrypt();
合并过程中的文件压缩
多个 pdf 合并后,体积往往会成倍增长。为了节省存储空间和传输带宽,我们可以利用 pdfcompressor 开启内容压缩模式,这能显著减小生成文件的体积。
import com.spire.pdf.conversion.compression.pdfcompressor;
// 针对合并后的成品进行压缩
pdfcompressor compressor = new pdfcompressor("示例.pdf");
// 启用文档内容压缩,移除不必要的元数据并优化资源
compressor.getoptions().setcompresscontents(true);
// 压缩并保存
compressor.compresstofile("内容压缩.pdf");
为合并后的文档添加统一水印
为了确保文档的版权或合规性,合并后的文件通常需要覆盖一层水印。我们可以遍历最终文档的所有页面,统一绘制图片水印。
// 循环遍历所有页面以插入水印
for (int i = 0; i < pdf.getpages().getcount(); i++) {
pdfpagebase page = pdf.getpages().get(i);
// 获取页面尺寸用于计算水印居中坐标
float pagewidth = (float)page.getactualsize().getwidth();
float pageheight = (float)page.getactualsize().getheight();
// 设置水印图片的透明度(0.0完全透明 - 1.0不透明)
page.getcanvas().settransparency(0.3f);
// 在页面中心位置绘制水印
page.getcanvas().drawimage(image, pagewidth/2 - imagewidth/2, pageheight/2 - imageheight/2, imagewidth, imageheight);
}
结语
通过本文的介绍,我们可以看到,在 java 中合并 pdf 不仅仅是简单的页面叠加,更涉及到权限管理、体积优化和内容二次加工等实际需求。借助 spire.pdf 等成熟的工具库,开发者可以用极少的代码量实现复杂的文档处理逻辑,显著提升工作效率。
以上就是java使用 spire.pdf实现合并pdf文档并进行加密与压缩处理的详细内容,更多关于java合并pdf的资料请关注代码网其它相关文章!

发表评论