我刚学 java 的时候,以为 jvm 就是个"黑盒",代码写完往里一扔就能跑。
后来才知道,jvm 里面学问大了去了。
今天这篇文章,就是我复习 jvm 时整理的笔记。面试问到 jvm 结构,如果你只能说出"堆和栈",那大概率要被追问到怀疑人生。
一、先画个整体框架
在说每个组件之前,先把 jvm 的结构捋清楚。
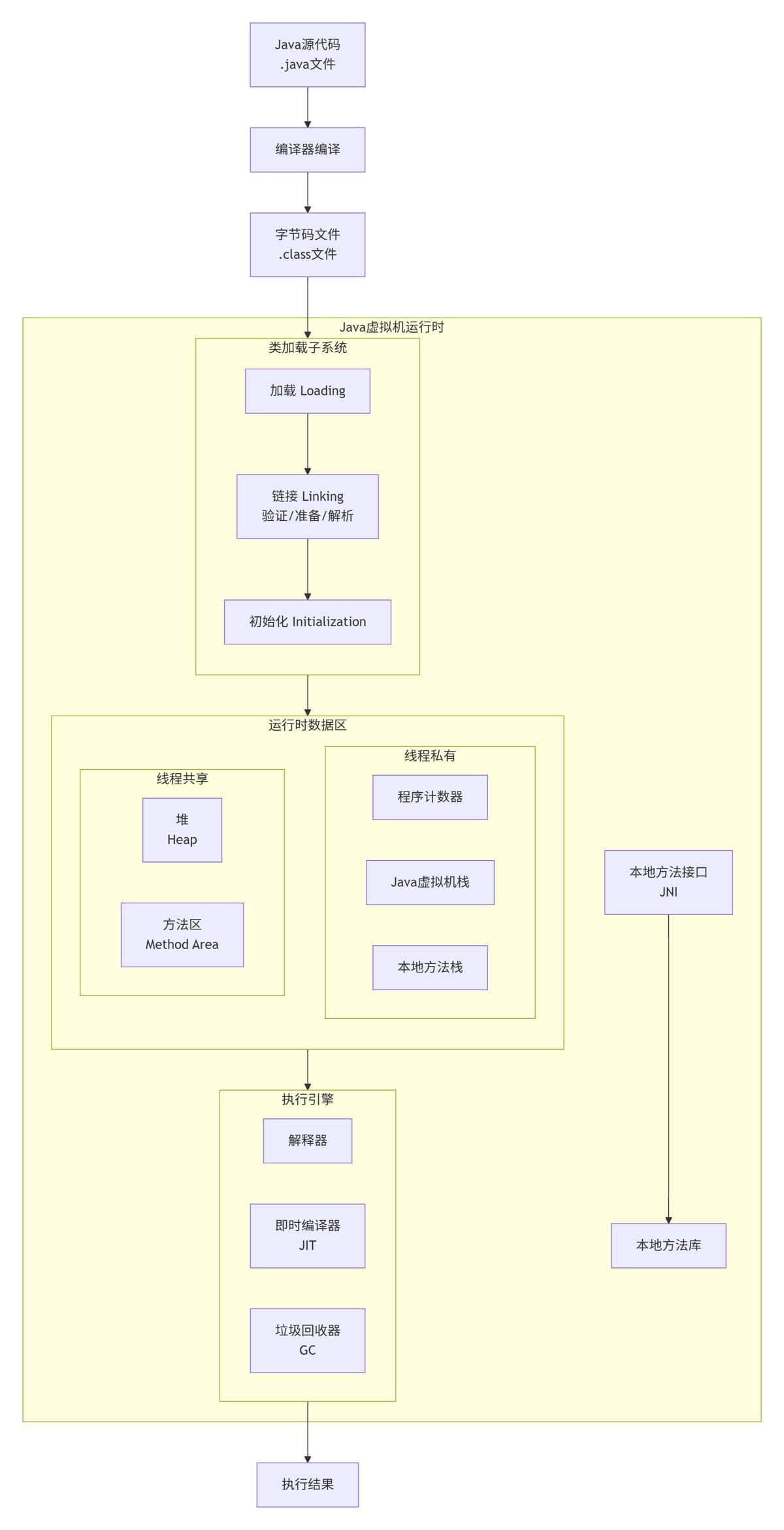
记住这个图,这是整个 jvm 的骨架。
三个核心模块:
- 类加载器(classloader)—— 把 class 文件加载进来
- 运行时数据区(runtime data area)—— 分配内存,存数据
- 执行引擎(execution engine)—— 执行字节码指令
二、类加载器 classloader
它干什么的?
classloader 负责把 .class 文件(字节码)加载到内存中,转换成 jvm 能认识的数据结构。
加载流程:
.java 源文件 ↓ 编译 .class 字节码文件 ↓ classloader 内存中的 class 对象(java.lang.class)
三个阶段
1. 加载(loading)
- 通过类的全限定名找到 class 文件
- 把字节流转换成方法区的数据结构
- 在堆里生成一个 class 对象,作为访问入口
2. 链接(linking)
- 验证:检查字节码格式是否正确(安全检查)
- 准备:给静态变量分配内存,设置默认值
- 解析:把符号引用替换成直接引用(比如把"方法名"变成内存地址)
3. 初始化(initialization)
- 执行静态代码块和静态变量的赋值
- 这是真正执行代码的地方
双亲委派模型
这块是面试高频追问。
三层类加载器:
| 加载器 | 负责加载 | 例子 |
|---|---|---|
| bootstrap classloader | jdk 核心类 | string, object |
| extension classloader | jdk 扩展类 | javax.* |
| application classloader | 用户 classpath | 自己写的类 |
双亲委派流程:
加载请求 ↓ applicationclassloader ↓ 问爸 extensionclassloader ↓ 问爸 bootstrapclassloader ↓ 找不到 extensionclassloader 尝试加载 ↓ 找不到 applicationclassloader 尝试加载 ↓ 成功 返回 class
为什么这样设计?
我当初也被问懵了,后来想明白了一个例子:
如果你自己写一个
java.lang.string,没有双亲委派的话,jvm 就会加载你自己写的 string,安全性全没了。
双亲委派保证:核心类库优先被 bootstrap 加载,防止用户代码覆盖 jdk。
三、运行时数据区 runtime data area
这是 jvm 里最重要的部分,也是面试追问的重灾区。
1. 程序计数器(program counter register)
特点:
- 很小,只存一个指针
- 指向下一条要执行的字节码指令
- 线程私有:每个线程都有自己的 pc
为什么不会 oom?
因为它只存一个指令地址,大小固定,不会动态增长。
唯一没有 gc 的区域。
2. 虚拟机栈(vm stack)
特点:
- 线程私有
- 存储方法调用的数据
- 每个方法叫一个栈帧(stack frame)
一个栈帧包含:
- 局部变量表(方法参数 + 局部变量)
- 操作数栈(计算时的临时空间)
- 动态链接(指向常量池的引用)
- 返回地址
会 oom 吗?
会。如果递归没写好,栈深度超过限制,就会 stackoverflowerror。
我之前写递归算法就踩过这个坑:
// 死递归,栈溢出
public int sum(int n) {
return sum(n) + 1; // 没有终止条件
}3. 本地方法栈(native method stack)
和虚拟机栈一样,只不过服务的是本地方法(native keyword 修饰的方法)。
jni 调用(c/c++ 写的代码)会用到这里。
4. 堆(heap)
jvm 里最大的内存区域。
- 存储对象实例和数组
- 线程共享:所有线程都能访问
- gc 的主要战场
为什么要分代?
因为对象的生命周期不同:
- 新生代:刚创建的对象(朝生夕死)
- 老年代:存活时间长的对象
- 分代后,gc 更有针对性,效率更高
5. 方法区(method area)
存储:
- 类的元信息(类名、修饰符、父类)
- 类的结构(字段、方法)
- 运行时常量池(字面量和符号引用)
- jit 编译后的代码缓存
jdk 1.8 的变化:
之前方法区在堆里,叫 permanent generation(永久代)。
jdk 1.8 改成了 metaspace,放在本地内存里。
| 版本 | 方法区实现 | 位置 |
|---|---|---|
| jdk 1.7 | permgen | 堆内 |
| jdk 1.8 | metaspace | 本地内存 |
为什么要改?
因为 permgen 容易 oom。你要是项目中依赖了一堆 jar 包,permgen 分分钟爆掉。
四、执行引擎 execution engine
它干什么的?
把字节码翻译成机器码,让 cpu 执行。
解释器 vs jit 编译器
| 组件 | 特点 | 适用场景 |
|---|---|---|
| 解释器 | 逐行翻译,立即执行 | 启动阶段,一次性执行 |
| jit 编译器 | 编译成机器码,缓存起来 | 热点代码,多次执行 |
jit 的热点探测:
jvm 会监控方法的执行频率,热点代码会被 jit 编译成机器码。
两个计数器:
- 方法调用计数器
- 回边计数器(循环体)
超过阈值就触发编译。
垃圾回收器
gc 是 jvm 里最复杂也最常问的部分。
常见 gc 算法:
| 算法 | 原理 | 缺点 |
|---|---|---|
| 标记-清除 | 标记存活对象,清理未标记的 | 产生内存碎片 |
| 复制 | 把活对象复制到另一半空间 | 浪费一半内存 |
| 标记-整理 | 标记后整理内存 | 整理耗时 |
常见垃圾回收器:
- serial(单线程)
- parallel(多线程,吞吐量优先)
- cms(并发标记清除,低停顿)
- g1(region划分,可预测停顿)
- zgc / shenandoah(超低停顿,jdk 11+)
五、本地接口 jni
java 不是万能的,有些场景需要调用本地代码(c/c++)。
jni 就是 java 和 native 代码之间的桥梁。
典型场景:
- 调用操作系统 api
- 追求极致性能(数学计算)
- 访问硬件
public native string hello(); // native 方法,调用 c 实现
六、记忆口诀
jvm 三大部分: ┌─────────────────────────────────┐ │ 类加载器 ──── 加载字节码 │ │ 运行时数据区 ── 分配内存 │ │ 执行引擎 ──── 执行字节码 │ └─────────────────────────────────┘ 运行时数据区五块: 计数器(无gc) 虚拟机栈(存方法调用,会oom) 本地方法栈(native方法) 堆(对象,会gc) 方法区(类信息) 双亲委派: bootstrap → extension → application
写在最后
jvm 这块知识,面试基本必问。
我踩过的坑是:只背概念,不画图。
后来我把 jvm 的结构画了 5 遍,把每个区域的作用、特点、常见问题都写上,面试时直接画给面试官看。
面试官当时眼睛一亮,说:"这个理解方式不错。"
技术表达很重要。能画出来、讲清楚,比背出来强 100 倍。
到此这篇关于jvm 有哪些组成部分:面试必问的 java 运行时架构的文章就介绍到这了,更多相关java运行时架构jvm内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论