引言
在现代分布式系统架构中,高可用性(high availability, ha)是保障服务持续在线、抵御单点故障的核心能力。无论是电商平台、金融交易系统,还是企业内部的关键业务应用,一旦服务中断,轻则影响用户体验,重则造成经济损失甚至法律风险。因此,构建具备自动故障转移能力的系统架构,已成为每一位后端工程师和运维人员的必修课。
在 linux 环境下,keepalived 是实现虚拟 ip(virtual ip, vip)漂移、完成主备切换的经典开源工具。它基于 vrrp 协议(virtual router redundancy protocol),通过心跳检测机制,在主节点宕机时,自动将 vip 迁移到备用节点,从而实现“无缝”故障转移。
本文将从零开始,带你一步步配置 keepalived,结合 java 应用演示真实场景下的高可用部署,并深入剖析其工作原理、常见问题及优化策略。无论你是刚接触运维的新手,还是希望提升系统稳定性的资深开发者,都能从中获得实用价值。
什么是 keepalived?
keepalived 最初设计用于 lvs(linux virtual server)负载均衡器的高可用方案,但因其轻量、高效、配置简单,迅速被广泛应用于各类需要 vip 漂移的场景,如数据库主从切换、nginx 高可用、自定义服务冗余等。
核心特性:
- 基于 vrrp 协议实现主备选举与 vip 切换
- 支持多播/单播通信模式
- 可自定义健康检查脚本(check script)
- 支持权重动态调整,实现“抢占”或“非抢占”模式
- 轻量级守护进程,资源占用低
vrrp 协议小科普:
vrrp 是一种容错协议,允许多台路由器组成一个“虚拟路由器”,对外表现为一个统一的网关 ip(即 vip)。当主路由器故障,备份路由器自动接管 vip,继续提供服务。keepalived 将这一思想扩展到任意 tcp/ip 服务上。
实验环境准备
为了便于演示,我们搭建一个最小化的双节点环境:
| 节点角色 | 主机名 | ip 地址 | 操作系统 |
|---|---|---|---|
| master | node-master | 192.168.1.100 | ubuntu 22.04 lts |
| backup | node-backup | 192.168.1.101 | ubuntu 22.04 lts |
虚拟 ip(vip):192.168.1.200
注意:两台机器需在同一局域网内,且能互相 ping 通。防火墙需放行 vrrp 协议(协议号 112)或关闭防火墙进行测试。
安装 keepalived
在两台机器上分别执行以下命令安装 keepalived:
sudo apt update sudo apt install -y keepalived
安装完成后,配置文件位于 /etc/keepalived/keepalived.conf。默认可能不存在,需手动创建。
配置 keepalived(master 节点)
编辑 master 节点的配置文件:
sudo vim /etc/keepalived/keepalived.conf
内容如下:
vrrp_instance vi_1 {
state master # 角色:主节点
interface eth0 # 绑定网卡,根据实际修改(可用 ip a 查看)
virtual_router_id 51 # 虚拟路由id,主备必须一致
priority 100 # 优先级,数值越大越优先成为主节点
advert_int 1 # 心跳检测间隔(秒)
authentication { # 认证配置,主备需一致
auth_type pass
auth_pass 123456
}
virtual_ipaddress {
192.168.1.200/24 dev eth0 # 虚拟ip及其子网掩码、绑定网卡
}
}
提示:interface 需替换为你机器的实际网卡名称,如 ens33、enp0s3 等。
配置 keepalived(backup 节点)
在 backup 节点上创建相同的配置文件,仅修改三处:
vrrp_instance vi_1 {
state backup # 角色改为 backup
interface eth0
virtual_router_id 51
priority 90 # 优先级低于 master
advert_int 1
authentication {
auth_type pass
auth_pass 123456
}
virtual_ipaddress {
192.168.1.200/24 dev eth0
}
}启动 keepalived 服务
在两台机器上分别启动并设置开机自启:
sudo systemctl enable keepalived sudo systemctl start keepalived sudo systemctl status keepalived
正常情况下,你应该看到服务处于 active (running) 状态。
验证 vip 是否生效
在 master 节点上执行:
ip addr show eth0
你应该能看到类似输出:
inet 192.168.1.100/24 ... inet 192.168.1.200/24 scope global secondary eth0
说明 vip 已成功绑定!
此时从局域网其他机器 ping 192.168.1.200,应能通:
ping 192.168.1.200
模拟故障转移
现在我们手动停止 master 节点的 keepalived:
sudo systemctl stop keepalived
等待几秒后,在 backup 节点上再次执行:
ip addr show eth0
你会发现 vip 192.168.1.200 已经出现在 backup 节点上!
同时,ping 测试依然畅通,证明故障转移成功
重启 master 节点的 keepalived,若配置为抢占模式(默认),vip 会自动切回 master。
结合 java 应用:构建高可用 http 服务
光有 vip 漂移还不够,我们需要让真正的业务服务——比如一个 java web 应用——也能随 vip 自动切换访问目标。
为此,我们在两台机器上各部署一个简单的 spring boot 应用,监听本地端口(如 8080),并通过 vip + nginx 反向代理对外提供统一入口。
编写 java 示例程序
使用 spring boot 创建一个返回主机名和当前时间的服务:
// 文件:hellocontroller.java
package com.example.ha;
import org.springframework.web.bind.annotation.getmapping;
import org.springframework.web.bind.annotation.restcontroller;
import java.net.inetaddress;
import java.net.unknownhostexception;
import java.time.localdatetime;
@restcontroller
public class hellocontroller {
@getmapping("/hello")
public string hello() {
try {
string hostname = inetaddress.getlocalhost().gethostname();
return "hello from " + hostname + " at " + localdatetime.now();
} catch (unknownhostexception e) {
return "hello from unknown host at " + localdatetime.now();
}
}
}// 文件:haapplication.java
package com.example.ha;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
@springbootapplication
public class haapplication {
public static void main(string[] args) {
springapplication.run(haapplication.class, args);
}
}打包成可执行 jar:
./mvnw clean package
在两台机器上分别运行:
java -jar ha-demo.jar --server.port=8080
访问各自 ip 的 http://<ip>:8080/hello,应能看到不同主机名。
配置 nginx 作为前端代理
为了让外部用户通过 vip 访问服务,我们在两台机器上都安装 nginx,并配置反向代理到本地 java 应用。
安装 nginx:
sudo apt install -y nginx
编辑配置文件:
sudo vim /etc/nginx/sites-available/default
替换为:
server {
listen 80;
server_name _;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header host $host;
proxy_set_header x-real-ip $remote_addr;
proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for;
}
}重启 nginx:
sudo systemctl restart nginx
现在,访问 http://192.168.1.200/hello,你将看到来自 master 节点的响应。
停掉 master 的 keepalived,刷新页面,你会看到响应来源自动切换到了 backup 节点!
恭喜!你已实现 java 应用的高可用架构!
故障转移流程图解(mermaid)
下面用 mermaid 图表直观展示整个故障转移过程:
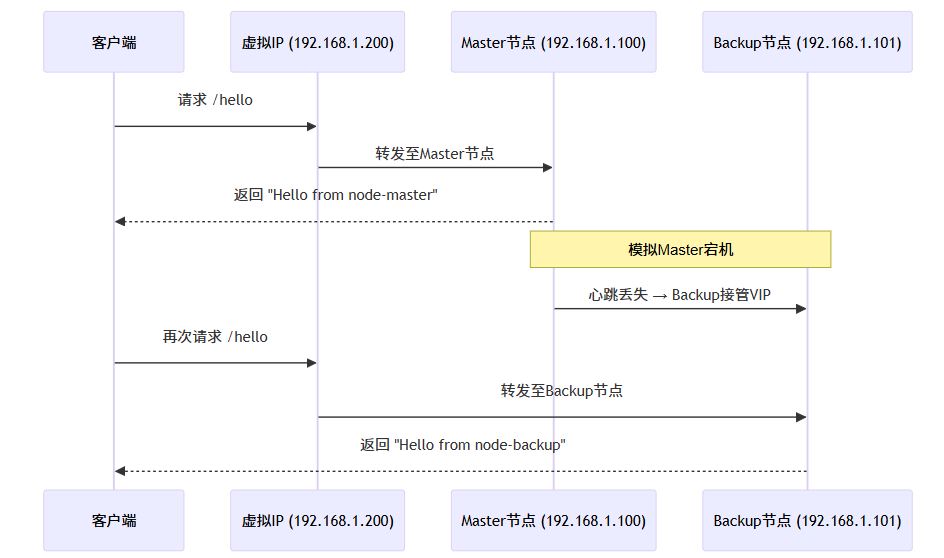
该图表清晰展示了客户端始终通过 vip 访问服务,而底层节点故障对用户透明无感知。
高级配置技巧
1. 非抢占模式(nopreempt)
默认情况下,当原 master 恢复后,会重新抢占 vip。如果你希望“谁先启动谁为主”,可在 master 和 backup 配置中加入:
nopreempt
并确保 master 的 priority 仍高于 backup。
注意:nopreempt 只在 state backup 时有效,所以即使配置在 master 上,也建议统一设为 backup + priority 控制主从。
2. 自定义健康检查脚本
有时我们希望在 java 应用崩溃时,即使 keepalived 还活着,也触发 vip 转移。这就需要“服务级健康检查”。
编辑 master 配置,加入:
vrrp_script chk_java {
script "/usr/local/bin/check_java.sh"
interval 2
weight -20 # 如果脚本失败,降低20分优先级
}
vrrp_instance vi_1 {
...
track_script {
chk_java
}
}创建检查脚本:
sudo vim /usr/local/bin/check_java.sh
内容:
#!/bin/bash curl -f http://localhost:8080/hello > /dev/null 2>&1 exit $?
赋予执行权限:
sudo chmod +x /usr/local/bin/check_java.sh
重启 keepalived:
sudo systemctl restart keepalived
现在,如果 java 应用挂掉,vip 会自动漂移到 backup!
3. 多播 vs 单播
默认 keepalived 使用多播通信(224.0.0.18),某些云环境或容器网络不支持多播,需改用单播。
在 vrrp_instance 中添加:
unicast_peer {
192.168.1.101 # backup ip
}
backup 节点则填写 master ip:
unicast_peer {
192.168.1.100 # master ip
}
java 端主动感知 vip 切换(可选进阶)
虽然 vip 对客户端透明,但在某些场景下,java 应用可能需要知道自己是否“当前活跃节点”,以便执行特定逻辑(如定时任务只在主节点运行)。
我们可以编写一个线程,定期检查本机是否持有 vip:
@component
public class vipmonitor {
private static final string vip = "192.168.1.200";
private volatile boolean ismaster = false;
@postconstruct
public void startmonitoring() {
new thread(() -> {
while (!thread.currentthread().isinterrupted()) {
try {
boolean hasvip = checklocalhasvip();
if (hasvip != ismaster) {
ismaster = hasvip;
system.out.println("vip 状态变更: " + (ismaster ? "成为主节点" : "降为备节点"));
onrolechange(ismaster);
}
thread.sleep(3000);
} catch (exception e) {
e.printstacktrace();
}
}
}, "vipmonitor").start();
}
private boolean checklocalhasvip() {
try {
enumeration<networkinterface> interfaces = networkinterface.getnetworkinterfaces();
while (interfaces.hasmoreelements()) {
networkinterface iface = interfaces.nextelement();
enumeration<inetaddress> addresses = iface.getinetaddresses();
while (addresses.hasmoreelements()) {
inetaddress addr = addresses.nextelement();
if (addr.gethostaddress().equals(vip)) {
return true;
}
}
}
} catch (socketexception e) {
e.printstacktrace();
}
return false;
}
private void onrolechange(boolean isnowmaster) {
if (isnowmaster) {
// 启动主节点专属任务,如:数据同步、报表生成等
schedulemasteronlytasks();
} else {
// 停止主节点任务
cancelmasteronlytasks();
}
}
private void schedulemasteronlytasks() {
system.out.println("启动主节点专属定时任务...");
// 示例:每分钟执行一次
// yourscheduler.scheduleatfixedrate(...);
}
private void cancelmasteronlytasks() {
system.out.println("取消主节点专属定时任务...");
// yourscheduler.shutdown();
}
public boolean ismaster() {
return ismaster;
}
}这样,你的 java 应用不仅能被动接受流量,还能主动参与高可用决策!
安全加固建议
虽然 keepalived 本身轻量高效,但在生产环境中仍需注意安全:
- 认证密码复杂化:避免使用
123456这类弱密码。 - 限制 vrrp 通信源 ip:通过防火墙规则,只允许备机 ip 发送 vrrp 包。
- 启用 unicast 替代 multicast:避免广播风暴或被中间人监听。
- 监控日志:定期查看
/var/log/syslog或journalctl -u keepalived,及时发现异常切换。
生产环境最佳实践
- 至少三节点部署:避免“脑裂”(split brain)问题。可通过第三方仲裁(如 zookeeper、redis)或脚本检测决定最终主节点。
- vip 与服务强绑定:确保 vip 漂移时,对应服务确实可用(通过健康检查脚本)。
- 优雅关闭:在系统 shutdown 前,主动降低 keepalived 权重,让 vip 提前漂移,减少服务中断时间。
- 配合 consul/zookeeper:对于微服务架构,可结合服务注册中心,实现更智能的流量调度。
常见问题排查
q1: vip 无法绑定?
- 检查网卡名称是否正确
- 检查子网掩码是否匹配
- 检查是否有其他进程占用了 vip
- 查看系统日志:
journalctl -u keepalived -f
q2: 主备同时持有 vip(脑裂)?
- 检查网络是否互通,vrrp 包能否正常收发
- 检查
virtual_router_id是否一致 - 检查防火墙是否放行协议 112
- 启用
unicast_peer避免多播干扰
q3: 健康检查脚本不生效?
- 确保脚本有执行权限
- 确保脚本路径正确
- 手动执行脚本,确认退出码为 0(成功)或非 0(失败)
- 检查
weight设置是否合理(负值表示失败时降权)
性能与扩展性考量
keepalived 本身性能极高,单实例可支撑数千个 vip 和数十万次状态检测。但在超大规模集群中,仍需考虑:
- 分组管理:按业务划分多个
vrrp_instance,避免单点压力过大。 - 权重动态调整:根据 cpu、内存、连接数等指标动态调整节点权重,实现“智能主备”。
- 与 kubernetes 集成:在容器化环境中,可使用 metallb 替代 keepalived,专为 k8s 设计。
与其他高可用方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| keepalived | 轻量、配置简单、成熟稳定 | 功能较单一,依赖 vip | lvs/nginx/自定义服务 |
| pacemaker + corosync | 功能强大,支持资源组、约束 | 配置复杂,学习成本高 | 数据库集群、企业级 ha |
| consul | 服务发现+健康检查+kv存储一体 | 资源占用高,需维护集群 | 微服务架构 |
| etcd + 自研脚本 | 灵活可控 | 开发维护成本高 | 定制化需求强的场景 |
对于大多数中小规模 java 应用,keepalived + nginx + 健康检查脚本的组合,是最具性价比的选择。
总结
通过本文,我们完成了从零配置 keepalived,实现 vip 故障自动转移,并将其与 java spring boot 应用结合,构建了一个真正意义上的高可用服务架构。整个过程涵盖了:
✅ keepalived 安装与基础配置
✅ vip 漂移验证与故障模拟
✅ java 应用部署与 nginx 反向代理整合
✅ 自定义健康检查脚本增强可靠性
✅ java 端主动感知角色变化(进阶)
✅ 生产环境最佳实践与安全建议
高可用不是“加个工具”就能解决的问题,而是贯穿架构设计、服务部署、监控告警、故障演练的系统工程。keepalived 是其中重要一环,帮助我们在基础设施层面屏蔽单点故障,为上层业务保驾护航。
下一步你可以尝试:
- 在三台机器上部署 keepalived,实现“一主两备”。
- 编写更复杂的健康检查脚本,如检测 jvm 内存、线程池状态。
- 将 vip 信息写入 redis 或 mysql,供其他服务读取当前主节点。
- 结合 prometheus + grafana,监控 vip 切换次数与耗时。
- 在 docker 容器中运行 keepalived,探索容器化高可用方案。
结语
技术之路,贵在实践。希望本文不仅教会你如何配置 keepalived,更能启发你思考系统稳定性背后的本质——冗余、检测、切换、恢复。每一次故障转移的背后,都是无数工程师对“永不宕机”的执着追求。
以上就是linux keepalived配置虚拟ip实现故障转移的全过程的详细内容,更多关于linux keepalived虚拟ip故障转移的资料请关注代码网其它相关文章!



发表评论