频繁gc背景
处理过线上问题的同学基本上都会遇到系统突然运行缓慢,cpu 100%,以及full gc次数过多的问题。当然,这些问题的最终导致的直观现象就是系统运行缓慢,并且有大量的报警。
本文主要记一次针对系统频繁gc这一问题,提供该问题的排查思路,从而定位出问题的代码点,进而提供解决该问题的思路。
不再重复赘述网上大部分排查gc命令,工具使用或者gc本身定义等
问题描述
发现商品应用product-dubbo频繁gc告警
规则名称: 【性能告警】应用gc次数大于20次/分钟(且新生代gc时间大于50ms) 触发时值: 74 监控指标: [alarmname=gc次数 application=product-dubbo ...] 持续时长: 0s 触发时间: 2025-06-21 11:44:06
同时有慢接口告警
规则名称: 【严重性能告警】应用接口平均响应时间大于1s 触发时值: 2.4098 规则备注: 过去十分钟内的平均响应时间 监控指标: [alarmname=接口rt application=product-client uri=/api/product/client/list] 持续时长: 0s 触发时间: 2025-06-21 11:03:39
问题排查思路
对于线上系统突然出现频繁gc问题,这种情况可能的原因主要有:代码中某个位置读取数据量较大,导致系统内存耗尽,从而导致full gc次数过多,那么首先需要做的就是,导出dump堆栈文件,分析其具体的内存信息
使用线程转储(thread dump)分析工具:
链接: link
其中等待线程数558,超时等待线程数49,运行线程数44

未发现消耗cpu的线程和阻塞线程
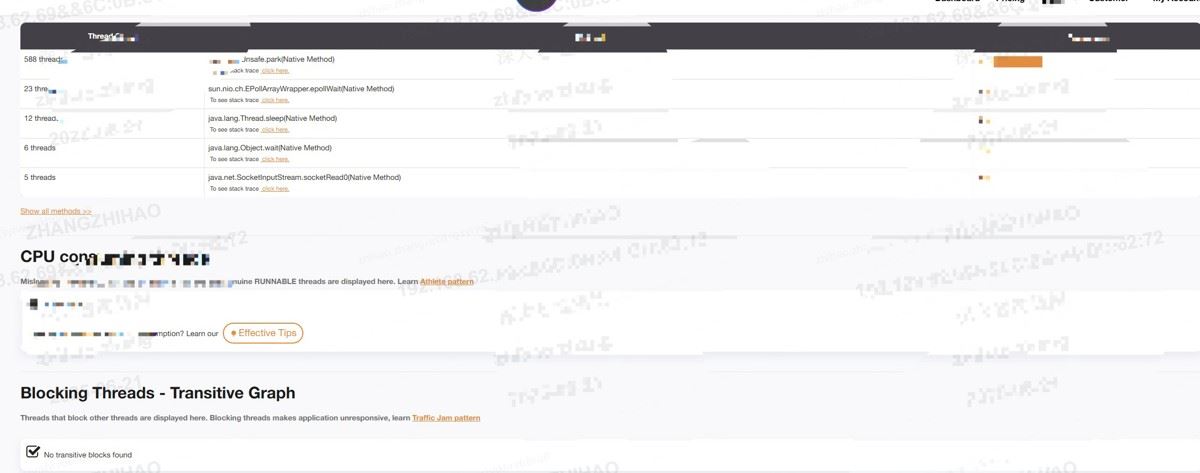
同时也没有死锁线程
排除掉异常线程导致频繁gc问题
进一步分析线程池里包含的线程
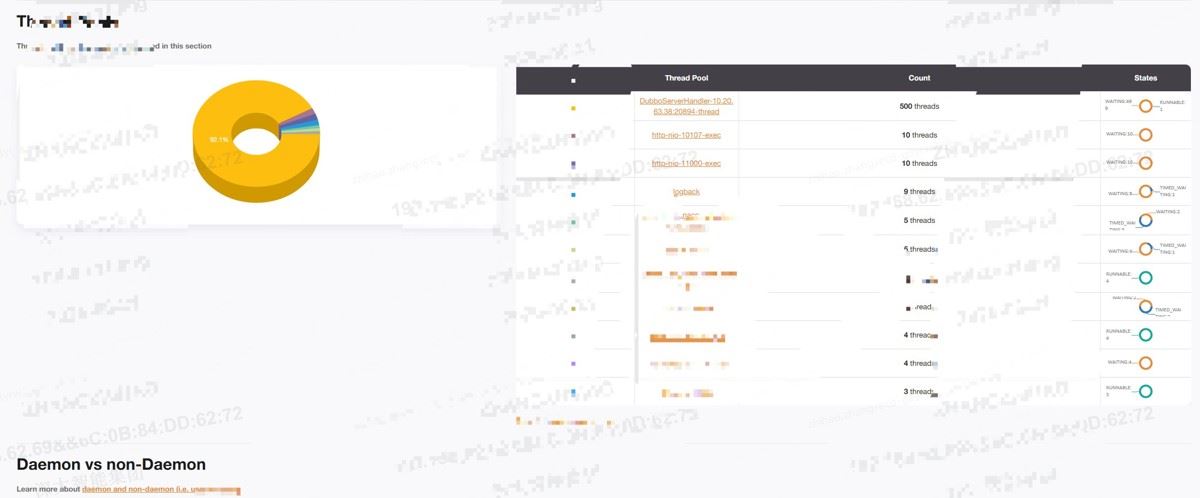
其中dubbo线程占据90%,其余线程比如tomcat线程,logback线程,自定义线程池线程等只占一小部分
排查dubbo线程堆栈发现问题
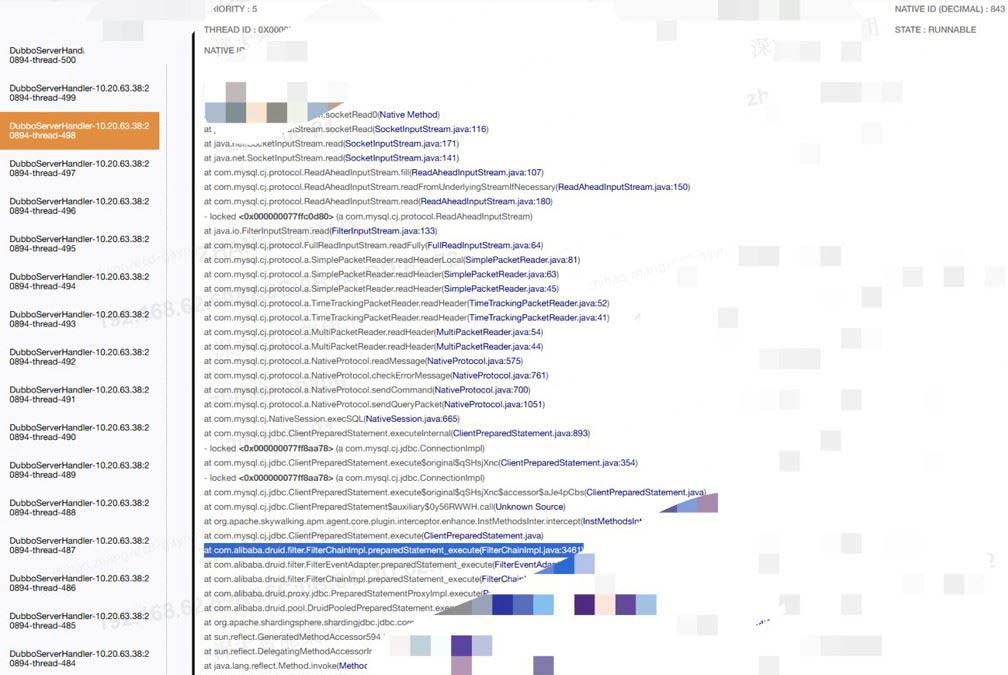
出现mysql存在异常
同时存在druid超时线程
综合分析
dubbo线程调用方法里面出现mysql异常,结合告警的慢接口是同一处,怀疑是否是慢sql导致的数据库连接池druid打满,进而导致dubbo大部分线程处于等待状态
通过arthas分析本次告警的慢接口
trace com.biz.prooduct querylist '#cost > 100'
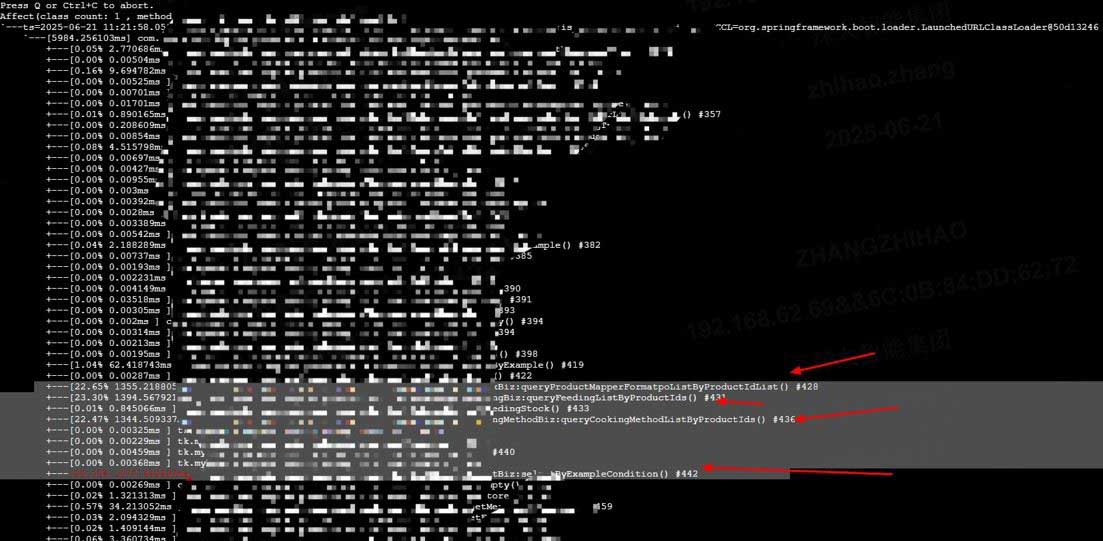
进一步验证上述分析结论
通过arthas分析内存对象
dumpheap --live /tmp/dump.hprof'
打开本地jvm分析工具分析hprof文件如下:
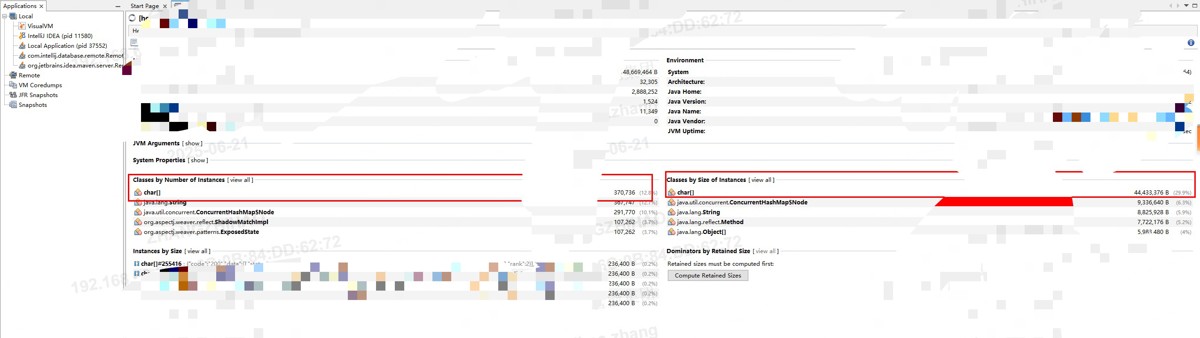
发现堆中占内存前三位的分别是char[]、string 和 concurrenthashmap$node三个类其中char[]占用绝大部分空间,进一步分析char[]数据:

上述char[]中存放的基本都是/api/product/client/list返回的数据
综合分析
由于/api/product/client/list是客户端获取商品列表接口,客户端每次查询商品都会去掉用,存在大量并发的场景,并且接口方法内部是拉取全量商品数据。
同时该接口有数次慢sql的代码,慢sql进一步导致数据库连接池耗尽,进而阻塞dubbo线程的典型故障链,从而引发频繁gc。
解决方案
1.慢sql优化(通过执行计划按量优化索引等)
2.方法优化(异步处理非核心代码)
3.业务优化(监听商品变动方法,客户端拉取全量商品存在本地,商品发生变动通知客户端重新拉取商品)
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论