在java开发中,缓存技术是提升系统性能的核心手段。无论是新手还是资深开发者,都会面临一个关键问题:什么时候该用本地缓存?什么时候必须用分布式缓存?
本文将用通俗的语言和实际案例,带你理解两者的区别、适用场景以及如何选择。
一、什么是缓存?为什么要用它?
缓存的本质:将频繁访问但获取速度慢的数据(如数据库查询、远程api调用)存储在访问速度快的介质中,减少对慢速数据源的依赖,从而提升系统性能。
常见的缓存类型:
- 本地缓存:数据存储在应用自己的内存中,速度快但容量有限,受jvm的限制。
- 分布式缓存:数据存储在独立的缓存服务中(如redis),支持多服务共享,容量和性能可扩展。
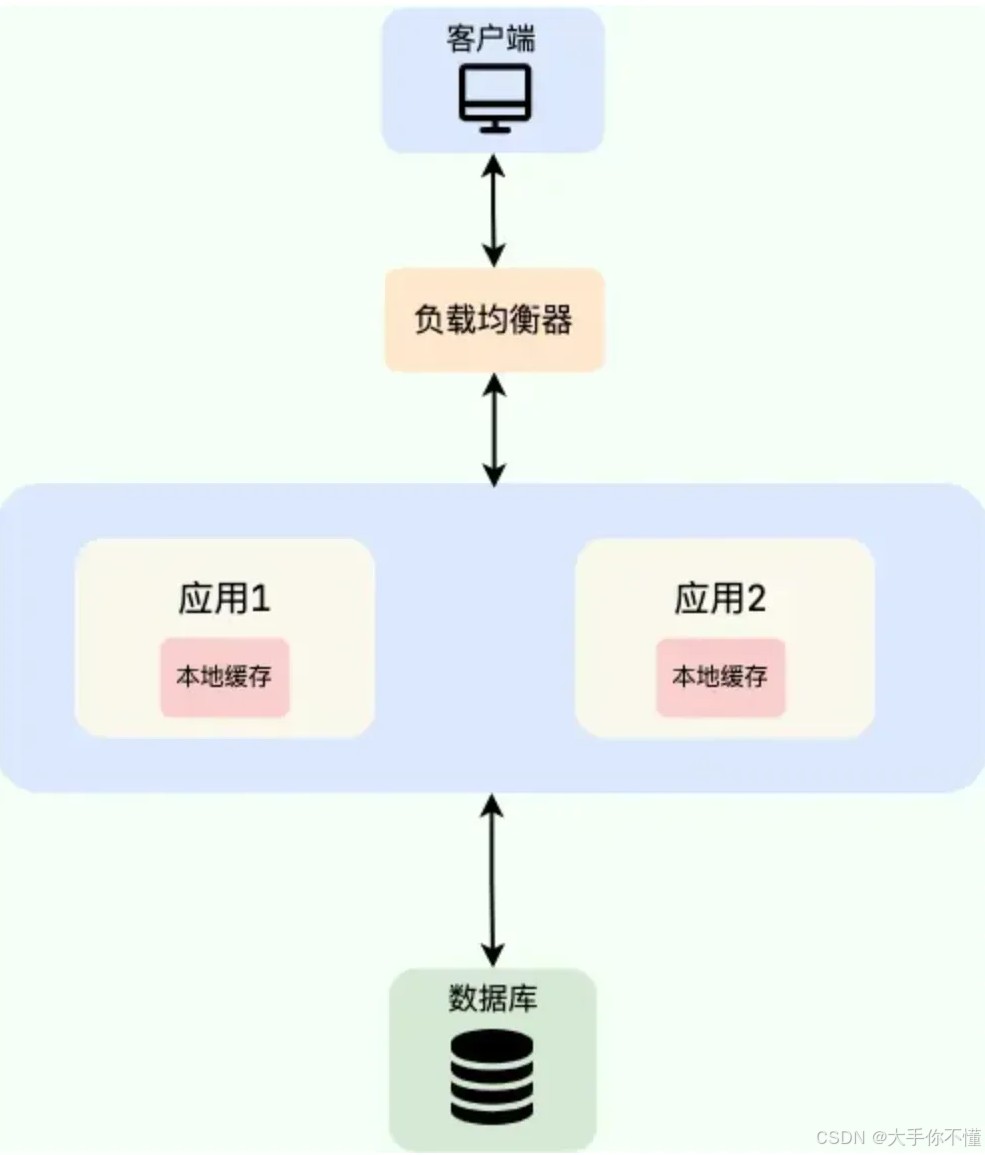
二、本地缓存:速度王者,但“独木难支”
本地缓存(local cache)是存储在单个应用实例内存中的缓存,比如你的电脑里有一个“本地文件夹”,所有数据都直接存在这个文件夹里。
常见的java本地缓存框架包括 caffeine、guava cache、ehcache 等。
1.本地缓存有哪些?各有什么优劣?
(1)concurrenthashmap(java标准库)
优点:
- 线程安全:通过锁分段机制支持高并发访问。
- 简单易用:无需额外依赖,直接使用。
- 性能优越:适用于高并发场景的简单缓存。
缺点:
- 缺少高级功能:没有过期策略、最大容量控制、缓存统计。
- 没有持久化:程序结束后数据丢失。
适用场景:
- 会话缓存、短期数据缓存(如登录态临时存储)。
代码示例:
import java.util.concurrent.concurrenthashmap;
public class simplecache<k, v> {
private final concurrenthashmap<k, v> cache = new concurrenthashmap<>();
public v get(k key) {
return cache.get(key);
}
public void put(k key, v value) {
cache.put(key, value);
}
public void remove(k key) {
cache.remove(key);
}
}
(2)guava cache(google开源库)
优点:
- 简单易用:api设计简洁,支持自动加载、过期策略(按时间或大小)。
- 灵活配置:支持lru(最近最少使用)、lfu(最不经常使用)等淘汰算法。
- 高效:适用于中等规模缓存需求。
缺点:
- 功能有限:不支持持久化和分布式缓存。
- 性能略低于caffeine。
适用场景:
- 读多写少的场景(如静态资源缓存)。
代码示例:
import com.google.common.cache.cachebuilder;
import com.google.common.cache.cache;
public class guavacacheexample {
public static void main(string[] args) {
// 创建缓存:最大容量100,写入后1分钟过期
cache<string, string> cache = cachebuilder.newbuilder()
.maximumsize(100)
.expireafterwrite(1, timeunit.minutes)
.build();
cache.put("key1", "value1");
string value = cache.getifpresent("key1"); // 获取缓存
system.out.println("value: " + value);
}
}
(3)caffeine(高性能本地缓存)
优点:
- 性能顶尖:基于w-tinylfu算法,命中率接近最优值。
- 支持异步清理:避免阻塞查询请求。
- 高度可配置:支持权重控制、异步刷新。
缺点:
- 不支持持久化:数据仅存在于内存中。
- 依赖jdk8及以上版本。
适用场景:
- 高频读取、低一致性要求的场景(如电商商品详情缓存)。
代码示例:
import com.github.benmanes.caffeine.cache.cache; // caffeine缓存接口
import com.github.benmanes.caffeine.cache.caffeine; // caffeine缓存构建器
import java.util.concurrent.timeunit; // 时间单位工具类
public class caffeinedemo {
// 初始化caffeine缓存实例
// 1. 最大缓存条目数:1000条(超过后自动淘汰旧数据)
// 2. 数据写入后10分钟过期(自动失效策略)
private static final cache<string, product> cache = caffeine.newbuilder()
.maximumsize(1000)
.expireafterwrite(10, timeunit.minutes)
.build();
/**
* 获取商品信息方法
* @param productid 商品id
* @return product 商品对象
*/
public product getproduct(string productid) {
// caffeine缓存核心api:get(key, mappingfunction)
// 1. 如果缓存命中,直接返回缓存值
// 2. 如果缓存未命中,执行mappingfunction加载数据到缓存
// 3. mappingfunction参数使用lambda表达式简化代码
return cache.get(productid, id -> fetchproductfromdb(id));
}
/**
* 模拟从数据库加载数据的方法
* @param id 数据标识符
* @return 数据对象
*/
private product fetchproductfromdb(string id) {
// 实际开发中这里会调用数据库查询接口
// 当前示例返回模拟数据
return new product(id, "product-" + id);
}
}
// product类定义(示例)
class product {
private string id;
private string name;
public product(string id, string name) {
this.id = id;
this.name = name;
}
// getter方法省略
}
(4)ehcache(多级缓存支持)
优点:
- 堆内+堆外+磁盘缓存:打破jvm内存限制,适合大数据量场景。
- 支持分布式集群:通过集群策略解决缓存漂移问题。
- 兼容jcache标准(jsr-107)。
缺点:
- 配置复杂:需管理堆外内存和磁盘存储。
- 性能略逊于caffeine。
适用场景:
- 需要持久化的复杂场景(如日志缓存、监控数据)。
代码示例:
import org.ehcache.cache; // ehcache缓存接口
import org.ehcache.cachemanager; // 缓存管理器(管理多个缓存)
import org.ehcache.config.builders.cacheconfigurationbuilder; // 缓存配置构建器
import org.ehcache.config.builders.resourcepoolsbuilder; // 资源池配置构建器
import org.ehcache.config.units.memoryunit; // 内存单位枚举类(mb/gb)
public class ehcachedemo {
public static void main(string[] args) {
// === 第一步:配置资源池 ===
// resourcepoolsbuilder用于定义缓存使用的存储资源类型和大小
resourcepoolsbuilder resourcepools = resourcepoolsbuilder.newresourcepoolsbuilder()
.heap(20, memoryunit.mb) // 堆内缓存:20mb(速度最快,受jvm内存限制)
.offheap(10, memoryunit.mb) // 堆外缓存:10mb(突破jvm内存限制,速度次之)
.disk(5, memoryunit.gb); // 磁盘缓存:5gb(容量最大,速度最慢,适合冷数据)
// === 第二步:创建缓存管理器和缓存实例 ===
// cachemanagerbuilder构建缓存管理器,withcache()添加具体缓存配置
// build(true) 表示立即构建(实际生产环境建议延迟初始化)
cachemanager cachemanager = cachemanagerbuilder.newcachemanagerbuilder()
.withcache("mycache", cacheconfigurationbuilder.newcacheconfigurationbuilder(
string.class, string.class, resourcepools)) // 定义缓存名称和键值类型
.build(true);
// 从缓存管理器中获取具体缓存实例
// 泛型参数指定键值类型为<string, string>
cache<string, string> cache = cachemanager.getcache("mycache", string.class, string.class);
// === 第三步:缓存操作 ===
// 存入数据:key1 -> value1
cache.put("key1", "value1");
// 获取数据:自动从堆内->堆外->磁盘按优先级查找
system.out.println("value: " + cache.get("key1")); // 输出:value: value1
}
}
资源池配置
heap(20, mb)
- 作用:分配20mb堆内内存作为缓存存储
- 特点:速度最快,但受jvm内存限制,适合热点数据
- 适用场景:高频访问的核心数据(如商品库存)
offheap(10, mb)
- 作用:分配10mb堆外内存,突破jvm内存限制
- 特点:速度略慢于堆内,但比磁盘快100倍+
- 适用场景:次热点数据或需要避免oom的场景
disk(5, gb)
- 作用:分配5gb磁盘空间作为冷数据存储
- 特点:容量最大,但访问速度最慢(毫秒级)
- 适用场景:低频访问的冷数据(如历史订单)
性能对比
- 堆内缓存:纳秒级(≈100ns)
- 堆外缓存:微秒级(≈1μs)
- 磁盘缓存:毫秒级(≈1ms)
3.本地缓存的核心优势
- 极低延迟:访问速度接近纳秒级(比分布式缓存快100倍以上)。
- 零网络开销:数据直接存放在应用进程内存中,无需跨网络请求。
- 资源占用少:不需要额外部署中间件(如redis),运维成本低。
2.本地缓存的典型适用场景
- 高频读取、低一致性要求:如静态资源(页面模板、配置文件)。
- 数据量小且更新频率低:如商品分类信息、菜单配置。
- 单体应用或微服务内部缓存:当数据只在单个服务实例内使用时,如用户登录状态的临时缓存。
三、分布式缓存:高可用与共享的“全能选手”
分布式缓存(distributed cache)数据存储在独立的、外部的缓存服务集群中,应用通过网络访问。
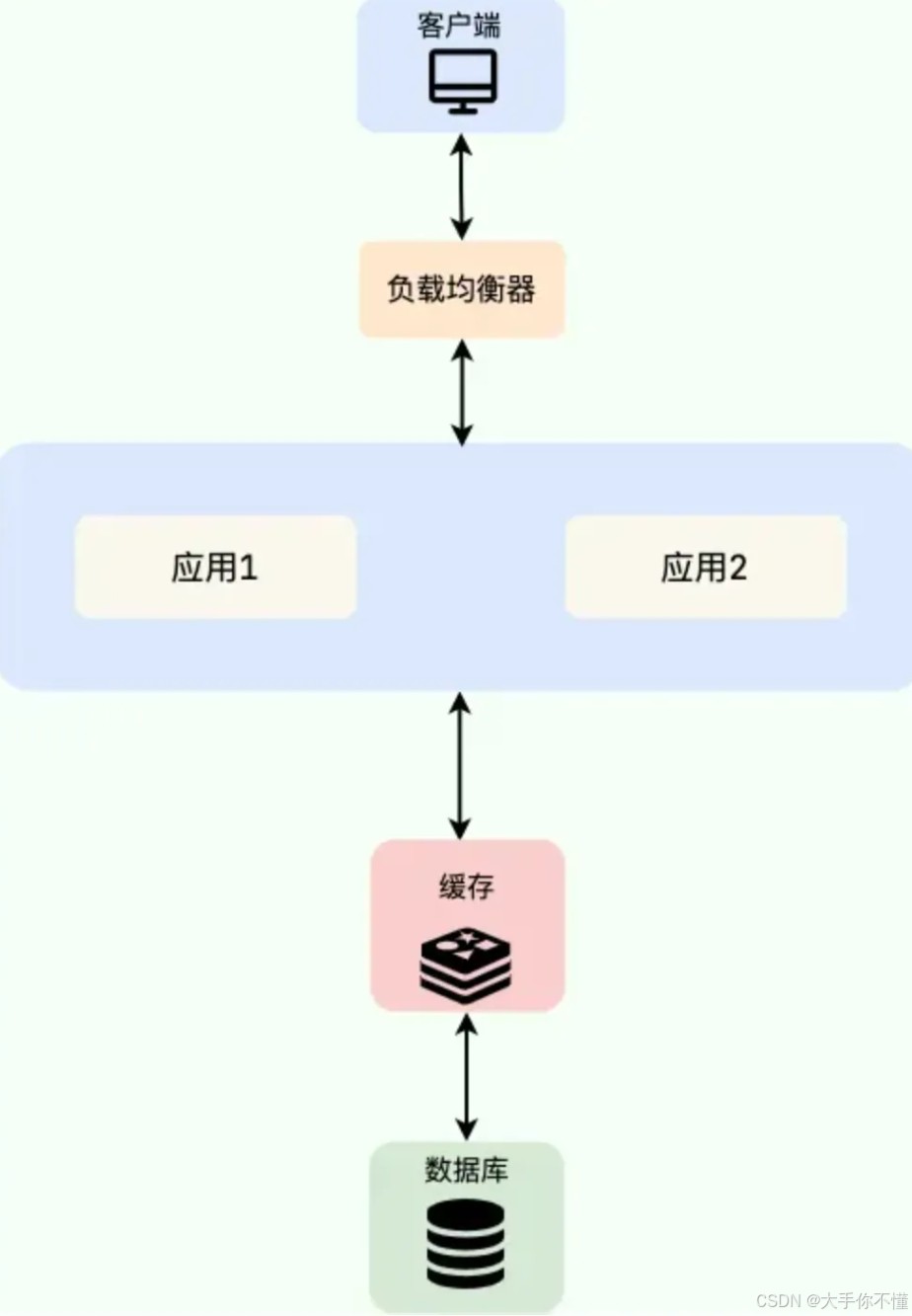
实现方案:
- redis(推荐),memcached,keydb、dragonfly。
优缺点:
- 优点:缓存容量可水平扩展,不受单机限制;所有应用实例共享同一份缓存数据,保证了数据的一致性;服务独立,不随应用重启而丢失数据。
- 缺点:存在网络开销,访问速度低于本地缓存;需要维护独立的缓存集群,增加了系统复杂度和运维成本。
1.典型适用场景
- 高并发场景:高频读写、数据量大。如秒杀活动、抢购场景(redis处理10万+/秒并发请求)。
- 跨服务共享数据:如用户登录态、购物车信息。
- 需要持久化的数据:多个服务实例需要协同工作,共享状态。redis支持rdb和aof持久化,防止数据丢失。
2.实战案例
假设开发一个社交平台,需要缓存“最新评论”以减少数据库压力:
// 使用redis缓存最新100条评论 string rediskey = "latest_comments"; jedis.lpush(rediskey, newcomment); // 添加新评论到列表头部 jedis.ltrim(rediskey, 0, 99); // 保留最近100条评论
四、本地缓存 vs 分布式缓存:如何选择?
| 维度 | 本地缓存 | 分布式缓存 |
|---|---|---|
| 数据一致性 | 多实例间不一致,需额外处理 | 天然保证一致性 |
| 访问速度 | 纳秒级(最快) | 毫秒级(受网络影响) |
| 适用场景 | 单体应用、静态数据、低频更新 | 高并发、跨服务共享、复杂业务 |
| 容量限制 | 受jvm内存限制 | 可横向扩展,支持tb级数据 |
| 运维复杂度 | 低(无需额外部署) | 高(需独立部署和维护) |
五、实战技巧:本地缓存 + 分布式缓存 = 性能翻倍
在实际项目中,本地缓存和分布式缓存可以结合使用,形成“双层缓存架构”:
分级缓存:
- 请求先查本地缓存(caffeine)。
- 未命中则查分布式缓存(redis)。
- 最后才查询数据库。
缓存预热:
- 应用启动时,从数据库加载热点数据到本地缓存和redis,减少首次访问延迟。
数据同步:
- 当redis中的数据更新时,通过redis的发布订阅功能通知所有服务实例更新本地缓存。
六、总结:选对工具,事半功倍
- 本地缓存:适合单机场景,追求极致性能,但需容忍数据不一致。
- 分布式缓存:适合分布式场景,保证数据共享和一致性,但需要权衡性能和成本。
- 混合使用:通过“本地缓存 + 分布式缓存”架构,既能享受本地缓存的速度优势,又能利用分布式缓存的共享能力。
在实际开发中,根据业务需求选择合适的工具。如果你还在纠结“redis还是caffeine”,不妨先问自己:我的数据需要被多少个服务共享?对延迟的要求有多高? 答案会指引你做出正确的选择。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论