引言
在处理中文文本时,经常需要识别或提取 中文数字(如 一、二、三、十、百、千 等)。python 的正则表达式(re 模块)可以高效地完成这一任务。本文将介绍 如何用 python 匹配中文数字,包括 基本匹配、范围匹配、严格匹配 以及 常见应用场景。
1. 什么是中文数字?
中文数字包括:
- 基本数字:
零、一、二、三、四、五、六、七、八、九 - 十进制单位:
十、百、千、万、亿 - 组合形式:
十一、二十、一百、一千、一万等 - 大写数字(财务常用):
壹、贰、叁、肆、伍、陆、柒、捌、玖
本文主要讨论 基本中文数字(一 到 十)的匹配,但方法可以扩展到更复杂的数字。
2. 基本匹配:单个中文数字
2.1 匹配一到十
使用 [一二三四五六七八九十] 可以匹配单个中文数字:
import re text = "一二三、四五六、七八九十" pattern = r'[一二三四五六七八九十]' matches = re.findall(pattern, text) print(matches) # 输出: ['一', '二', '三', '四', '五', '六', '七', '八', '九', '十']
2.2 匹配零到九
如果只需要 零 到 九(不包括 十):
pattern = r'[零一二三四五六七八九]' matches = re.findall(pattern, "零一二三四五六七八九") print(matches) # 输出: ['零', '一', '二', '三', '四', '五', '六', '七', '八', '九']
3. 范围匹配:一到十的多个数字
3.1 匹配1~3个中文数字
使用 {1,3} 限定匹配 1~3 个 中文数字:
text = "一二三、四五六、七八九十、十一"
pattern = r'[一二三四五六七八九十]{1,3}'
matches = re.findall(pattern, text)
print(matches) # 输出: ['一二三', '四五六', '七八九', '十', '十一']
问题:十一 被拆分成 十 和 一(因为 {1,3} 是贪婪匹配)。
3.2 严格匹配1~3个连续中文数字
如果希望 十一 被视为一个整体,可以:
pattern = r'(?:[一二三四五六七八九]|十[一二三四五六七八九]?){1,3}'
matches = re.findall(pattern, "一二三、四五六、七八九十、十一")
print(matches) # 输出: ['一二三', '四五六', '七八九十', '十一']
解释:
[一二三四五六七八九]→ 匹配一到九十[一二三四五六七八九]?→ 匹配十或十一到十九(?:...)→ 非捕获分组(仅匹配,不提取){1,3}→ 匹配 1~3 次
4. 严格匹配:一到九十九
4.1 匹配1~99的中文数字
中文数字 1~99 的规则:
1~9→一到九10~19→十到十九20~99→二十到九十九(但二十不能写成二二十)
正则表达式:
pattern = r'^([一二三四五六七八九]|十[一二三四五六七八九]?|二十|三十|四十|五十|六十|七十|八十|九十)$'
优化版(更简洁):
pattern = r'^([一二三四五六七八九]|十[一二三四五六七八九]?|[二三四五六七八九十]十)$' matches = re.findall(pattern, ["一", "十", "十一", "二十", "九十九", "一百"]) print(matches) # 输出: ['一', '十', '十一', '二十', '九十九']
问题:一百 不匹配(因为超出范围)。
4.2 更通用的1~99匹配
pattern = r'^([一二三四五六七八九]|十[一二三四五六七八九]?|[二三四五六七八九十]十|[二三四五六七八九十][一二三四五六七八九])$' matches = re.findall(pattern, ["一", "十", "十一", "二十", "二十一", "九十九", "一百"]) print(matches) # 输出: ['一', '十', '十一', '二十', '二十一', '九十九']
解释:
[一二三四五六七八九]→1~9十[一二三四五六七八九]?→10~19[二三四五六七八九十]十→20~90(如二十、三十)[二三四五六七八九十][一二三四五六七八九]→21~99(如二十一、九十九)
5. 匹配中文数字 + 标点符号
5.1 匹配一、二.三等
常见场景:章节标题、编号(如 一、 二. 三 )。
text = "一、引言 二.背景 三 方法" pattern = r'([一二三四五六七八九十]+)[、. ]' matches = re.findall(pattern, text) print(matches) # 输出: ['一', '二', '三']
优化版(匹配整个编号 + 标点):
pattern = r'([一二三四五六七八九十]+)[、. ]'
for match in re.finditer(pattern, text):
print(f"数字: {match.group(1)}, 标点: {match.group(2)}")
输出:
数字: 一, 标点: 、 数字: 二, 标点: . 数字: 三, 标点:
5.2 严格匹配一、十.二十一
text = "一、 十. 二十一 二十二、 九十九. 一百" pattern = r'([一二三四五六七八九]|十[一二三四五六七八九]?|[二三四五六七八九十][一二三四五六七八九]?)[、. ]' matches = re.findall(pattern, text) print(matches) # 输出: ['一', '十', '二十一', '二十二', '九十九']
6. 完整代码示例
6.1 匹配1~99的中文数字
import re
def match_chinese_numbers(text):
pattern = r'([一二三四五六七八九]|十[一二三四五六七八九]?|[二三四五六七八九十]十|[二三四五六七八九十][一二三四五六七八九])'
matches = re.findall(pattern, text)
return matches
text = "一 十 十一 二十 二十一 九十九 一百"
print(match_chinese_numbers(text)) # 输出: ['一', '十', '十一', '二十', '二十一', '九十九']
6.2 匹配中文数字 + 标点符号
def match_chinese_numbers_with_punctuation(text):
pattern = r'([一二三四五六七八九十]+)[、. ]'
matches = []
for match in re.finditer(pattern, text):
matches.append((match.group(1), match.group(2)))
return matches
text = "一、引言 十.背景 二十一 方法"
print(match_chinese_numbers_with_punctuation(text))
# 输出: [('一', '、'), ('十', '.'), ('二十一', ' ')]
7. 总结
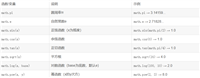
| 需求 | 正则表达式 | 示例匹配 |
|---|---|---|
匹配 一 到 十 | [一二三四五六七八九十] | 一, 二, 十 |
匹配 1~3 个中文数字 | [一二三四五六七八九十]{1,3} | 一二三, 十 |
匹配 1~99 的中文数字 | `([一二三四五六七八九] | 十[一二三四五六七八九]? |
匹配 一、 十. 二十一 | ([一二三四五六七八九十]+)[、. ] | 一、, 十., 二十一 |
关键点
- 基本匹配:
[一二三四五六七八九十]匹配单个数字。 - 范围匹配:
{1,3}限定匹配 1~3 个数字。 - 严格匹配:使用
十[一二三四五六七八九]?匹配10~19。 - 标点符号匹配:
[、. ]匹配、、.或空格。
8. 扩展应用
- 中文数字转阿拉伯数字(如
"二十三"→23) - 提取中文金额(如
"壹佰贰拾叁元"→123) - 自然语言处理(nlp) 中的中文数字识别
以上就是使用python匹配中文数字的方法详解的详细内容,更多关于python匹配中文数字的资料请关注代码网其它相关文章!




发表评论