在编程世界中,变量是构建一切逻辑的基石。想象一下,你正在整理一个杂乱的书架——变量就像一个个标签,帮助你快速找到并管理书籍的位置。python作为一门以简洁和可读性著称的语言,其变量系统既直观又充满智慧。今天,我们将深入探索变量的赋值与重新赋值操作,揭开它们背后的秘密。无论你是刚踏入编程大门的新手,还是想巩固基础的老手,这篇指南都将为你提供清晰、实用的洞见。🚀 准备好了吗?让我们一起踏上这段旅程!
🌟 什么是变量?为什么它如此重要?
变量本质上是内存中的一块“命名存储区域”。当你创建一个变量时,python会为你分配一块内存空间,并赋予它一个名字。这样,你无需记住复杂的内存地址,只需通过名字就能访问和操作数据。变量让代码变得动态、灵活且易于维护。
在python中,变量不需要显式声明类型(这称为动态类型),解释器会根据赋值自动推断。例如:
age = 25 # python 知道 age 是整数 name = "alice" # python 知道 name 是字符串
这种灵活性是python的魅力所在,但也带来了理解赋值机制的必要性。变量不是简单的“容器”,而是对象的引用。这是python与c/java等语言的关键区别。
变量命名的黄金法则
python对变量命名有明确规则:
- 只能包含字母、数字和下划线(
a-z,a-z,0-9,_) - 不能以数字开头(如
1var无效) - 区分大小写(
myvar和myvar不同) - 避免使用python关键字(如
if,for,class)
良好的命名习惯能大幅提升代码可读性。例如:
# 坏例子:含义模糊 a = 100 b = "data" # 好例子:清晰表达意图 user_age = 30 user_profile = "active"
记住:代码是写给人看的,机器只是顺便执行它。💡 想深入了解python命名规范,可以参考pep 8官方指南,这是python社区的编码圣经。
✨ 变量的赋值操作:创建与初始化
赋值操作是变量的起点,使用单等号 = 完成。它告诉python:“把右边的值存储到左边的变量名下”。这个过程包含两个关键步骤:
- 创建对象:右边的值被实例化为一个对象(在内存中生成)
- 建立引用:变量名指向该对象的内存地址
基础赋值语法与示例
最简单的赋值形式:
x = 10 # 将整数 10 赋值给变量 x print(x) # 输出: 10
这里,10 是一个不可变的整数对象,x 是指向它的引用。让我们通过 id() 函数验证内存地址:
x = 10 print(id(x)) # 输出类似 140735678912345 的内存地址
每次运行结果不同,但同一对象的地址在程序生命周期内不变(除非重新赋值)。
多变量赋值:效率与优雅
python支持多种赋值技巧,让代码更简洁:
# 同时赋值多个变量 a, b, c = 1, 2, 3 print(a, b, c) # 输出: 1 2 3 # 交换变量值(无需临时变量!) x = 5 y = 10 x, y = y, x # 魔法时刻! print(x, y) # 输出: 10 5 # 链式赋值(所有变量指向同一对象) p = q = r = "shared" print(p, q, r) # 输出: shared shared shared
在链式赋值中,p、q、r 都指向同一个字符串对象。这引出了一个重要概念:引用共享。
不同数据类型的赋值行为
python有可变(mutable)和不可变(immutable)对象,赋值行为截然不同:
不可变对象:整数、字符串、元组
一旦创建,内容无法修改。重新赋值会创建新对象:
s = "hello" print(id(s)) # 地址1 s = s + " world" # 创建新字符串对象 print(id(s)) # 地址2(与地址1不同!)
字符串 "hello" 本身没变,但 s 现在指向新对象 "hello world"。
可变对象:列表、字典、集合
内容可以原地修改,不影响引用:
my_list = [1, 2, 3] print(id(my_list)) # 地址a my_list.append(4) # 原地修改列表 print(id(my_list)) # 地址a(与之前相同!)
这里,列表对象本身被修改,但 my_list 的引用没变。
赋值陷阱:可变默认参数
新手常犯的错误涉及函数默认参数:
def add_item(item, my_list=[]): # 危险!默认列表是同一个对象
my_list.append(item)
return my_list
print(add_item(1)) # 输出: [1]
print(add_item(2)) # 输出: [1, 2] (不是 [2]!)问题在于 my_list=[] 只在函数定义时创建一次。正确做法:
def add_item(item, my_list=none):
if my_list is none:
my_list = []
my_list.append(item)
return my_list
这个陷阱凸显了理解对象引用的重要性。想系统学习函数参数,推荐real python的深入教程。
🔁 变量的重新赋值操作:动态改变的魔法
重新赋值是变量的核心特性——它让程序能动态响应变化。语法与初始赋值相同:变量 = 新值。但背后机制更微妙:
- 新对象创建:右边的表达式生成新对象
- 引用更新:变量名断开旧对象连接,指向新对象
- 旧对象处理:如果无其他引用,python的垃圾回收器会清理它
重新赋值的直观示例
counter = 0
print(f"初始值: {counter}, 地址: {id(counter)}") # 地址x
counter = counter + 1 # 重新赋值
print(f"新值: {counter}, 地址: {id(counter)}") # 地址y(与x不同!)输出可能类似:
初始值: 0, 地址: 140735678912345
新值: 1, 地址: 140735678912368
整数 0 和 1 是不同对象,所以地址改变。
可变对象的特殊性
对可变对象重新赋值会切断原有连接:
data = [10, 20] ref = data # ref 指向同一列表 data = [30, 40] # 重新赋值 data print(data) # [30, 40] print(ref) # [10, 20] (ref 仍指向旧列表!)
注意:ref 没受影响,因为重新赋值只改变了 data 的引用,未修改原列表。
重新赋值 vs 原地修改
这是新手最易混淆的点!看对比:
# 案例1:重新赋值(创建新对象) a = [1, 2] b = a a = [3, 4] # a 指向新列表 print(a, b) # [3, 4] [1, 2] # 案例2:原地修改(修改对象内容) a = [1, 2] b = a a.append(3) # 修改原列表 print(a, b) # [1, 2, 3] [1, 2, 3]
关键区别:
=操作符总是更新引用- 方法如
.append()、.extend()修改对象本身
重新赋值的实用场景
1. 状态管理
user_status = "inactive" # 模拟用户登录 user_status = "active" # 状态更新
2. 循环中的值累积
total = 0
for num in [5, 10, 15]:
total = total + num # 逐步重新赋值
print(total) # 30
3. 条件逻辑切换
theme = "light"
if is_night_mode:
theme = "dark" # 根据条件重新赋值
重新赋值的陷阱:引用丢失
original_list = [1, 2, 3] temp = original_list temp = temp + [4] # 创建新列表并重新赋值给 temp print(original_list) # 仍是 [1, 2, 3]!
本意可能是修改原列表,但 temp = temp + [4] 创建了新对象。正确做法:
original_list = [1, 2, 3] temp = original_list temp.append(4) # 原地修改 print(original_list) # [1, 2, 3, 4]
这个错误在调试时很隐蔽,务必区分 = 和方法调用!
💡 深入内存管理:理解引用与对象生命周期
python的内存管理是自动的,但理解它能避免性能问题和诡异bug。核心概念:变量是引用,不是容器。
id() 和 is:探索对象身份
id(obj):返回对象的唯一内存地址is运算符:检查两个变量是否指向同一对象
x = 1000 y = 1000 print(x is y) # 可能 false(大整数不缓存) x = 10 y = 10 print(x is y) # true(小整数缓存优化)
为什么?cpython对小整数(-5到256)做缓存,但大整数每次新建对象。这解释了为什么:
a = [1, 2] b = [1, 2] print(a == b) # true(值相等) print(a is b) # false(不同对象)
可变 vs 不可变:内存行为对比
让我们用mermaid图表直观展示赋值过程:
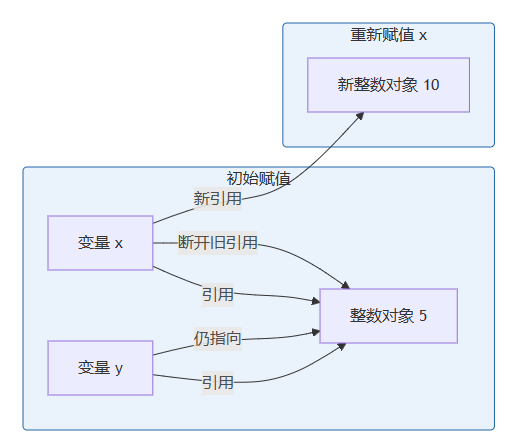
这个图表说明:
- 初始时
x = y = 5,两者共享同一对象 - 当
x = 10时,x指向新对象,y保持不变 - 旧对象
5若无引用,将被垃圾回收
不可变对象的重新赋值
s1 = "python" s2 = s1 s1 = s1 + " is fun" # 创建新字符串 print(s1) # "python is fun" print(s2) # "python" (未改变)
内存变化:
- 初始:
s1和s2→"python" - 重新赋值后:
s1→"python is fun",s2仍 →"python"
可变对象的原地修改
list1 = [1, 2] list2 = list1 list1.append(3) # 原地修改 print(list1) # [1, 2, 3] print(list2) # [1, 2, 3] (同步改变!)
内存变化:
- 始终只有一个列表对象
- 两个变量共享修改
垃圾回收机制:自动清理无用对象
python使用引用计数 + 垃圾回收器:
- 每个对象有引用计数(被变量/容器引用的次数)
- 当计数归零,内存立即释放
- 循环引用由周期性gc处理
import sys a = [1, 2, 3] print(sys.getrefcount(a)) # 输出 2(a + getrefcount的临时引用) b = a print(sys.getrefcount(a)) # 输出 3 b = none # 移除一个引用 print(sys.getrefcount(a)) # 输出 2
注意:getrefcount 本身会增加临时引用,实际计数需减1。
深拷贝 vs 浅拷贝:控制引用行为
当需要独立副本时:
import copy original = [1, [2, 3]] shallow = copy.copy(original) # 浅拷贝 deep = copy.deepcopy(original) # 深拷贝 # 修改嵌套列表 original[1][0] = "x" print(shallow) # [1, ['x', 3]] (嵌套对象共享) print(deep) # [1, [2, 3]] (完全独立)
浅拷贝只复制顶层引用,深拷贝递归复制所有层级。官方文档有详细说明。
⚠️ 常见错误与最佳实践
1. 未初始化变量
print(count) # nameerror: name 'count' is not defined count = 0
修复:始终先赋值再使用。ide通常会标记此类错误。
2. 混淆赋值与相等比较
if x = 5: # 语法错误!应为 if x == 5
...
修复:记住 = 是赋值,== 是比较。多练习避免手误。
3. 可变对象的意外共享
matrix = [[0] * 3] * 3 # 三行共享同一列表! matrix[0][0] = 1 print(matrix) # [[1, 0, 0], [1, 0, 0], [1, 0, 0]] (不是预期!)
修复:用列表推导创建独立子列表:
matrix = [[0 for _ in range(3)] for _ in range(3)]
4. 在循环中错误重新赋值
result = []
for i in range(3):
result = [i] # 每次覆盖,只保留最后一次
print(result) # [2]
修复:用 .append() 累积:
result = []
for i in range(3):
result.append(i)
最佳实践清单
✅ 明确意图命名:用 user_count 代替 uc
✅ 避免全局变量:函数内优先用局部变量
✅ 可变对象小心共享:需要副本时用 copy.deepcopy()
✅ 小整数/字符串缓存意识:不要依赖 is 比较值
✅ 及时解除引用:大对象不再用时设为 none,促垃圾回收
想避免常见陷阱,w3schools的python错误指南提供实用案例。
🌈 高级技巧:赋值在真实场景的应用
1. 解包赋值:优雅处理序列
# 元组解包
coordinates = (40.7128, -74.0060)
latitude, longitude = coordinates
# 忽略部分值
_, _, city = ("usa", "ny", "new york") # _ 是惯用占位符
# 扩展解包(python 3.0+)
first, *middle, last = [1, 2, 3, 4, 5]
print(middle) # [2, 3, 4]2. 条件表达式赋值
status = "active" if user_logged_in else "inactive"
比传统if-else更简洁,但避免过度嵌套。
3. 模拟常量(通过约定)
python无真正常量,但可用全大写命名约定:
max_users = 100 # 开发者约定为常量 # 实际仍可重新赋值,但团队应遵守规则
4. 动态变量名(谨慎使用)
for i in range(3):
globals()[f"var_{i}"] = i * 10
print(var_1) # 10
警告:这破坏可读性,优先用字典:
data = {f"var_{i}": i * 10 for i in range(3)}
🔍 深入探索:赋值操作符的底层机制
python的赋值由解释器在编译时处理。当你写 x = 10:
- 解析器识别赋值语句
- 计算右侧表达式(生成对象)
- 将左侧名称绑定到该对象
名称绑定 vs 对象复制
关键认知:赋值总是绑定名称,永不隐式复制对象。
a = [1, 2] b = a # b 绑定到 a 指向的对象 b.append(3) print(a) # [1, 2, 3] (a 和 b 共享对象)
这解释了为什么 b = a 不是“复制列表”,而是“创建新引用”。
函数参数传递:引用传递的真相
python是传递对象引用(call by object reference):
def modify(lst):
lst.append(100) # 修改可变对象
my_list = [1, 2]
modify(my_list)
print(my_list) # [1, 2, 100] (被修改)
def reassign(lst):
lst = [3, 4] # 重新绑定局部变量
my_list = [1, 2]
reassign(my_list)
print(my_list) # [1, 2] (未改变!)在 reassign 中,lst = [3,4] 只改变函数内的局部引用,不影响外部。
自定义类的赋值行为
通过 __setattr__ 控制赋值:
class safebox:
def __init__(self):
self._value = none
def __setattr__(self, name, value):
if name == "password" and len(value) < 8:
raise valueerror("密码至少8字符!")
super().__setattr__(name, value)
box = safebox()
box.password = "1234567" # 触发 valueerror这展示了赋值操作的可扩展性。
📊 实战演练:用赋值构建小型应用
让我们用赋值知识实现一个用户管理系统片段:
# 初始化用户数据库(字典存储)
users = {
"alice": {"age": 25, "status": "active"},
"bob": {"age": 30, "status": "inactive"}
}
def update_user(username, **kwargs):
"""安全更新用户信息(避免直接修改)"""
if username not in users:
print(f"⚠️ 用户 {username} 不存在!")
return
# 创建新配置(深拷贝避免污染原数据)
new_data = copy.deepcopy(users[username])
new_data.update(kwargs)
# 验证年龄
if "age" in new_data and new_data["age"] < 18:
print("❌ 未成年人无法注册!")
return
# 原子化重新赋值
users[username] = new_data
print(f"✅ {username} 已更新: {new_data}")
# 测试用例
update_user("alice", status="premium", age=26)
update_user("bob", age=17) # 触发验证失败
print(users["alice"]["status"]) # premium关键点:
- 使用深拷贝确保数据安全
- 通过重新赋值
users[username] = new_data原子更新 - 验证逻辑在重新赋值前执行
💎 总结:掌握赋值,掌控python
变量的赋值与重新赋值是python的呼吸节奏——简单却蕴含深意。通过本文,我们:
- 🌱 理解了本质:变量是对象的引用,不是存储容器
- 🧪 实践了操作:从基础赋值到高级解包技巧
- 🔍 洞察了内存:用
id()和is探索对象生命周期 - ⚠️ 避开了陷阱:可变对象共享、重新赋值误区等
记住黄金法则:
赋值改变引用,方法改变对象。
当你下次写 x = 10 时,想象python在内存中建立了一条隐形纽带。这种思维将让你写出更健壮、高效的代码。编程不是魔法,而是对细节的精确掌控。正如计算机科学家alan kay所言:“简单事情不应复杂化,复杂事情不应简单化。”
继续探索吧!python的赋值机制只是冰山一角。动手修改本文示例,观察内存变化,你会获得更深领悟。官方python数据模型文档是进阶的绝佳资源。保持好奇,保持实践,你终将成为python大师!🌟
到此这篇关于python变量的赋值与重新赋值操作流程的文章就介绍到这了,更多相关python变量的赋值与重新赋值内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论