一、csv文件
逗号分隔值(comma-separated values,csv)是一种以纯文本格式存储表格数据的文件格式。每一行代表一条数据记录,每条记录由一个或多个字段组成。字段分隔符默认使用逗号分隔,实际使用中也可以采用其他字符作为分隔符,如分号 ;或制表符 \t等。
1. 基本结构
- 每一行:表示一条数据记录。
- 字段:记录中的每个数据项,用字段分隔符分隔。
- 字段值:文本或数字,可以包含特殊字符。
姓名,年龄,城市
张三,30,北京
李四,25,上海
2. 特殊情况
字段中若包含回车换行符、双引号或者逗号,该字段需要用双引号括起来。如果用双引号括字段,那么出现在字段内的双引号前必须加一个双引号进行转义。
"aaa","b bb","ccc" "aaa","b""bb","ccc"
二、python解析
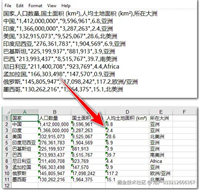
1. 数据文件(data.csv)
id,name,age,city 1,alice,30,new york 2,bob,25,los angeles 3,charlie,35,chicago 4,david,40,houston
2. 原生python
导入csv包之后对文件进行解析。
import csv
# 1. 读取 csv 文件
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
data = list(reader)
# 2. 取行/列数据
# 取第二行数据
print("\n第二行数据:", data[1])
# 取第三列数据
column_index = 2
column_data = [row[column_index] for row in data]
print("\n第三列数据:", column_data)
# 3. 遍历数据
print("\n遍历数据:")
for row in data:
print(row)
# 4. 批量修改某行/列数据
# 批量修改第二行数据
new_row_data = ['5', 'eva', '28', 'san francisco']
data[1] = new_row_data
# 批量修改第三列数据
new_column_data = ['31', '26', '36', '41']
for i, row in enumerate(data[1:], start=1): # skip header row
row[column_index] = new_column_data[i - 1]
# 5. 修改某个具体的值
# 修改第一行第二列的具体值
data[0][1] = 'alicia'
# 6. 增加某行/列数据
# 增加新行
new_row = ['5', 'eva', '28', 'san francisco']
data.append(new_row)
# 增加新列
new_column_data = ['usa'] * len(data) # new column data
for row, value in zip(data, new_column_data):
row.append(value)
# 7. 删除某行/列数据
# 删除第二行
del data[1]
# 删除第三列
for row in data:
del row[2]
# 8. 存储数据
# 保存修改后的数据
with open(file_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(data)
print("\n修改后的数据:")
for row in data:
print(row)3. pandas
导入pandas包之后对文件进行解析。
import pandas as pd
# 1. 读取 csv 文件
df = pd.read_csv('data.csv')
# 2. 取行/列数据
# 取第一行数据
print("\n第一行数据:")
print(df.iloc[0])
# 取 'name' 列的数据
print("\n'name' 列的数据:")
print(df['name'])
# 3. 遍历数据
print("\n遍历数据:")
for index, row in df.iterrows():
print(f"id: {row['id']}, name: {row['name']}, age: {row['age']}, city: {row['city']}")
# 4. 批量修改某行/列数据
# 修改 'age' 列中所有人的年龄,加5岁
df['age'] = df['age'] + 5
# 修改 'city' 列中 'new york' 的值为 'nyc'
df.loc[df['city'] == 'new york', 'city'] = 'nyc'
# 5. 修改某个具体的值
# 修改 id 为 2 的人的 'age' 为 28
df.loc[df['id'] == 2, 'age'] = 28
# 删除 'city' 列
df = df.drop(columns=['city'])
# 6. 增加行/列,并填充数据
# 增加一列 'email' 并填充默认值 'unknown'
df['email'] = 'unknown'
# 增加一行数据
new_row = {'id': 5, 'name': 'eve', 'age': 22, 'email': 'eve@example.com'}
df.loc[len(df)] = new_row
# 7. 删除某行/列数据
# 删除 id 为 4 的行
df = df[df['id'] != 4]
# 删除 'city' 列
df = df.drop(columns=['city'])
# 8. 存储数据
df.to_csv('modified_data.csv', index=false)
print("\n修改后的数据:")
print(df)to_csv函数详解:
dataframe.to_csv(path_or_buf=none, sep=', ', na_rep='', float_format=none,
columns=none, header=true, index=true, index_label=none, mode='w',
encoding=none, compression=none, quoting=none, quotechar='"',
line_terminator='\n', chunksize=none, tupleize_cols=none,
date_format=none, doublequote=true,escapechar=none, decimal='.')重要参数:
columns: 列名sep: 字段分隔符,默认为 ,index: 是否保存索引,默认为 trueheader: 是否保存列名,默认为 truena_rep: 替换空数据的字符串,默认为 ‘’float_format: 设置浮点数的格式(保留位数)path_or_buf: 文件路径,如果没有指定则将会直接返回字符串的 json
为了快速上手,对于csv文件数据取出来之后的数据操作从各个方面给了简单的demo。以取列值和行值为例(特别是pandas),根据数据情况有很多种方式,其中不乏简单便捷的,可以找具体的教程进行学习。
到此这篇关于一文带你搞懂python如何解析csv文件的文章就介绍到这了,更多相关python解析csv文件内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论