是什么
spring循环依赖指两个或多个 bean 相互依赖,形成闭环。
spring 通过巧妙的机制(如三级缓存)默认支持 setter 注入的循环依赖,但不支持 constructor 注入的循环依赖(会抛异常)。
两种注入方式
a、构造器注入(如 @autowired 在 constructor 上):容易造成无法解决的循环依赖,不推荐使用【现象:无法new对象,因为互相是构造函数的入参,编译报错】,会抛 beancurrentlyincreationexception。
/**
* 通过构造器的方式注入依赖,构造器的方式注入依赖的bean,下面两个bean循环依赖
* 测试后发现,构造器循环依赖是无法解决的
*/
public class clientconstructor {
public static void main(string[] args) {
new servicea(new serviceb(new servicea(new serviceb())));
}
}b、setter 注入:通过 setter 方法或字段注入(如 @autowired 在字段上),spring 默认支持
@component
public class a {
@autowired
private b b; // setter 注入
}
@component
public class b {
@autowired
private a a; // setter 注入
}循环依赖的解决办法【重点】
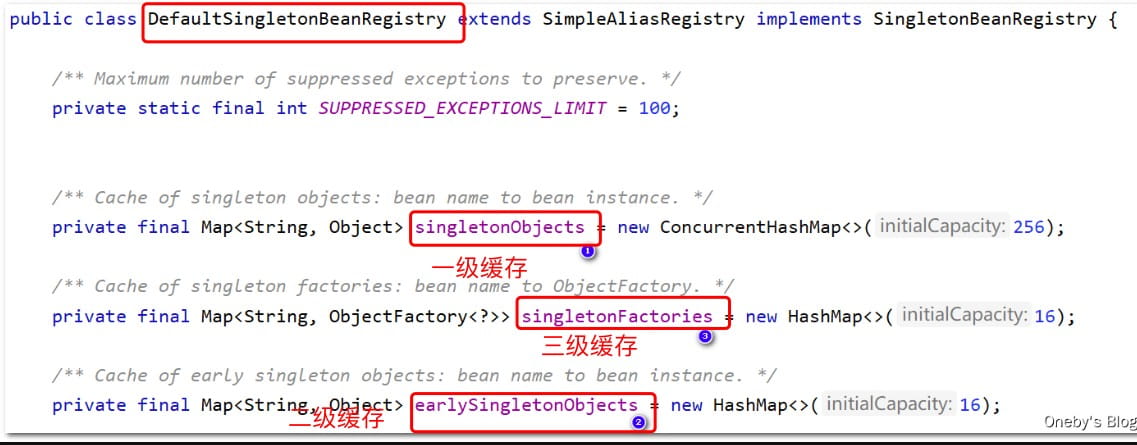
重要结论:spring 内部通过3级缓存来解决循环依赖,核心是“提前暴露”半成品 bean(aop 代理前),允许其他 bean 先引用。所谓的三级缓存其实就是 spring 容器内部用来解决循环依赖问题的三个 map,这三个 map 在 defaultsingletonbeanregistry 类中。
三级缓存详解:
- singletonobjects(一级缓存):我愿称之为单例池,常说的 spring 容器就是指它(因为默认的bean生命周期是singleton),我们获取单例 bean 就是在这里面获取的,存放已经经历了完整生命周期的bean对象【存放完全初始化的 bean】
- earlysingletonobjects(二级缓存):存放早期暴露出来的bean对象,bean的生命周期未结束【存放已经实例化,但属性还未填充完整的半成品 bean】
- singletonfactories(三级缓存):存放可以生成bean的工厂,用于生产(创建)对象【存放factorybean工厂池】
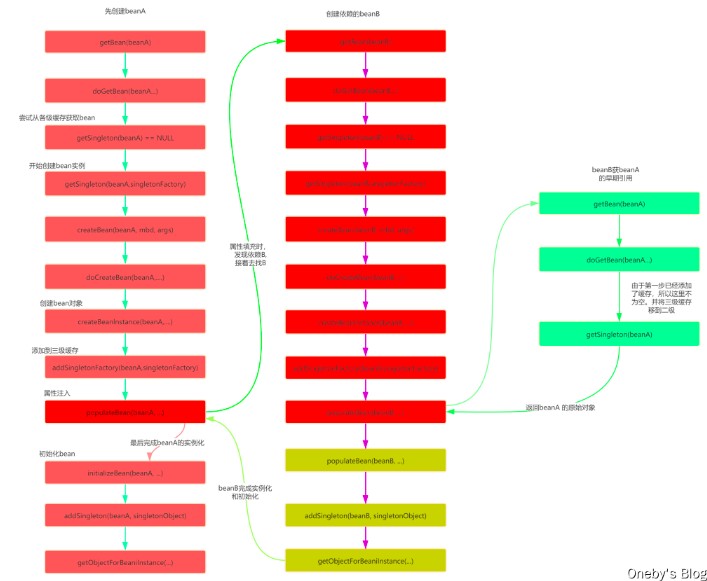
创建过程(以 a 依赖 b,b 依赖 a 为例):
- 实例化 a:spring 调用 getbean(a),创建 a 实例(无属性),放入三级缓存(singletonfactories,作为 lambda:() -> getearlybeanreference(a))。
- 注入 a 的属性:发现依赖 b,调用 getbean(b)。
- 实例化 b:类似,创建 b 实例,放入三级缓存。
- 注入 b 的属性:发现依赖 a,从三级缓存获取 a 的工厂,生成早期 a(半成品),放入二级缓存,并注入到 b。
- 完成 b:b 初始化完毕,移到一级缓存。
- 返回到 a:a 继续注入 b(已完成),完成初始化,移到一级缓存。
- 如果涉及 aop:三级缓存的工厂会生成代理对象,确保循环中代理一致。
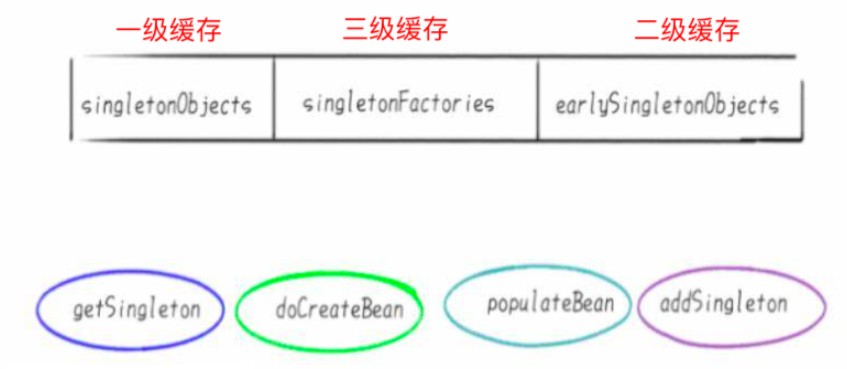
getsingleton(): 从容器里面获得单例的bean,没有的话则会创建 bean
docreatebean(): 执行创建 bean 的操作(在 spring 中以 do 开头的方法都是干实事的方法)
populatebean(): 创建完 bean 之后,对 bean 的属性进行填充
addsingleton(): bean 初始化完成之后,添加到单例容器池中,下次执行 getsingleton() 方法时就能获取到
bean的创建顺序
bean的创建顺序是由beandefinition的注册顺序来决定的, 当然依赖关系也会影响bean创建顺序,比如a依赖b,那肯定b先创建,a后创建。
那beandefinition的注册顺序由什么来决定的?
主要是由注解(配置)的解析顺序来决定,顺序如下:
@configuration @component @import-类 @bean @import—importbeandefinitionregistrar
总结
- 调用dogetbean()方法,想要获取beana,于是调用getsingleton()方法从缓存中查找beana
- 在getsingleton()方法中,从一级缓存中查找,没有,返回null
- dogetbean()方法中获取到的beana为null,于是走对应的处理逻辑,调用getsingleton()的重载方法(参数为objectfactory的)
- 在getsingleton()方法中,先将beana_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatbean()方法
- 进入abstractautowirecapablebeanfactory#docreatebean(),先反射调用构造器创建出beana的实例,然后判断。是否为单例、是否允许提前暴露引用(对于单例一般为true)、是否正在创建中〈即是否在第四步的集合中)。判断为true则将beana添加到【三级缓存】中
- 对beana进行属性填充,此时检测到beana依赖于beanb,于是开始查找beanb
- 调用dogetbean()方法,和上面beana的过程一样,到缓存中查找beanb,没有则创建,然后给beanb填充属性
- 此时beanb依赖于beana,调用getsingleton()获取beana,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beana的创建工厂,通过创建工厂获取到singletonobject,此时这个singletonobject指向的就是上面在docreatebean()方法中实例化的bean
- 这样beanb就获取到了beana的依赖,于是beanb顺利完成实例化,并将beana从三级缓存移动到二级缓存中
- 随后beana继续他的属性填充工作,此时也获取到了beanb,beana也随之完成了创建,回到getsingleton()方法中继续向下执行,将beana从二级缓存移动到一级缓存中
到此这篇关于spring循环依赖详解的文章就介绍到这了,更多相关spring循环依赖内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论