还在为数据表太多而烦恼吗?
no, 我要偷懒, 让其自动创建。
了解到 maven 有插件可以生成mapper, 但那不是我想要的,我想要的是 @注解方式
通过数据表实体自动创建 我从中得到了启发,那就是 拼接字符串并生成文件,正好可以获取数据表与字段信息
自动生成流程
菜单
首先选择要添加的表,一个或多个, 右键-scripted extensions 就有一个脚本选择菜单
从中选择 generator mymappers.groovy
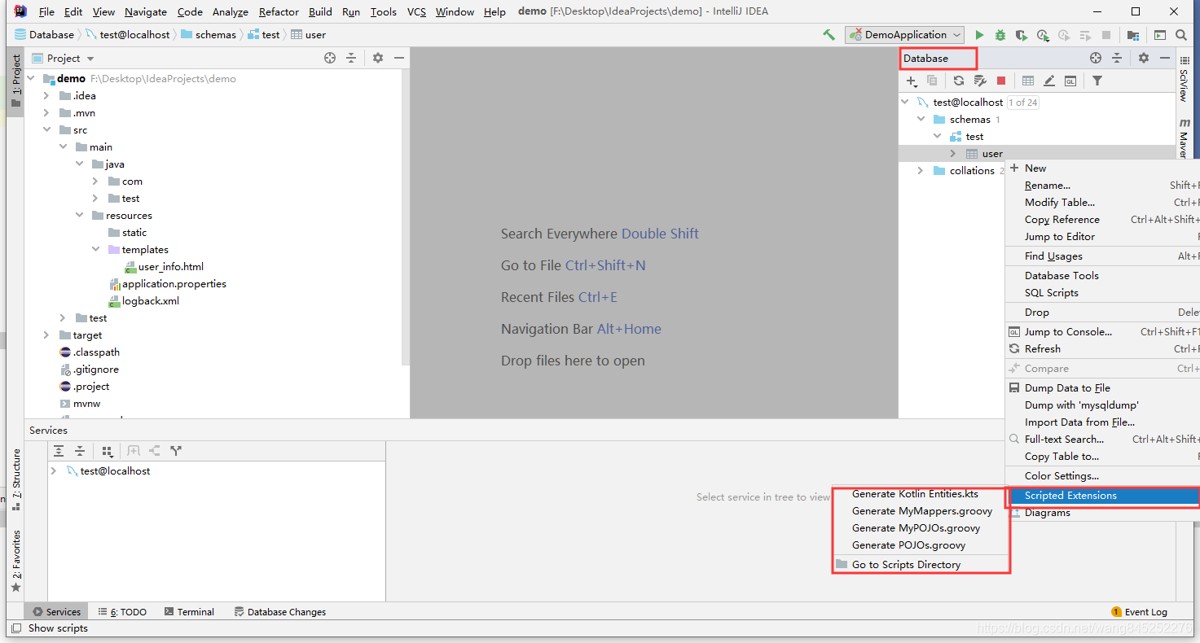
选择实体类的目录
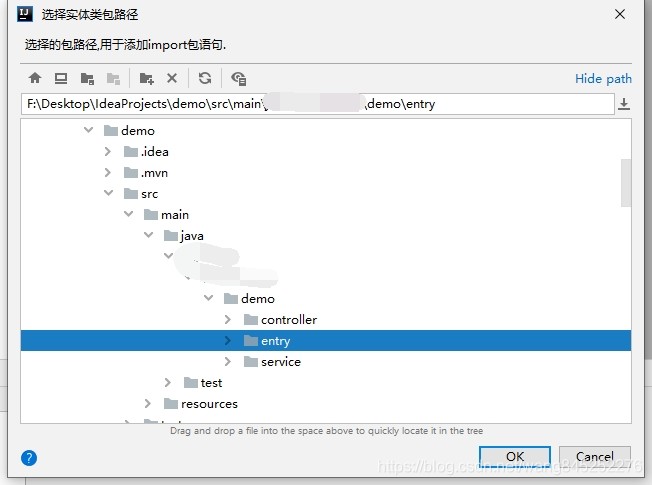
选择存放mapper的目录
代码生成完成
package c.test.demo.mapper;
import org.apache.ibatis.annotations.*;
import java.sql.timestamp;
import c.test.demo.entry.user;
/**
* 由groovy自动生成
* <p>date: 2019/11/28 下午2:03.</p>
* description: null
* @see user
* @author mr.wang
*/
@mapper
@cachenamespace
public interface usermapper {
/**
* 添加记录
* @param user 要插入的对象,包含必要信息
*/
@insert("insert into user(id,username,password,sex,birthday) value (#{id},#{username},#{password},#{sex},#{birthday})")
@options(usegeneratedkeys = true, keyproperty = "id")
void adduser(user user);
/**
* 删除记录
* @param id 【主键】
* @return true/false 是否有记录被修改
*/
@delete("delete from user where id = #{id}")
boolean deleteuserbyid(integer id);
/**
* 修改参数对象中主键字段对应的记录
* @param user 要修改的对象,此对象应该是被查询的对象,并且必须包含主键
* @return true/false 是否有记录被修改
*/
@update("update user set id=#{id},username=#{username},password=#{password},sex=#{sex},birthday=#{birthday} where id = #{id}")
boolean updateuser(user user);
/**
* 修改字段 username
* @param id
* @param username
* @return true/false 是否有记录被修改
*/
@update("update user set username=#{username} where id = #{id}")
boolean updatefieldusername(@param("id") integer id,@param("username") string username);
/**
* 修改字段 password
* @param id
* @param password
* @return true/false 是否有记录被修改
*/
@update("update user set password=#{password} where id = #{id}")
boolean updatefieldpassword(@param("id") integer id,@param("password") string password);
/**
* 修改字段 sex
* @param id
* @param sex
* @return true/false 是否有记录被修改
*/
@update("update user set sex=#{sex} where id = #{id}")
boolean updatefieldsex(@param("id") integer id,@param("sex") boolean sex);
/**
* 修改字段 birthday
* @param id
* @param birthday
* @return true/false 是否有记录被修改
*/
@update("update user set birthday=#{birthday} where id = #{id}")
boolean updatefieldbirthday(@param("id") integer id,@param("birthday") timestamp birthday);
/**
* 通过主键 id查询
* @param id 【主键】
* @return object or null
*/
@select("select * from user where id = #{id}")
user getuser(integer id);
}
阐述
生成的要点:
- 没试过复合主键表
- 有主键或无主键都可
- 无主键的将只有 查找所有和修改所有方法,以及单个字段的修改
- 有主键的将有 增删改查, 以及每个字段的修改方法(以主键为条件)
- 即使添加方法写了主键也无影响
generator mymappers.groovy
参考第一张图, 选择 “go to scripts directory” 跳转到脚本目录, 将文件放入其中就可以选择.
或者在目录 c:\users\用户名.intellijidea~\config\extensions\com.intellij.database\schema 文件夹
import com.intellij.database.model.dastable
import com.intellij.database.util.case
import com.intellij.database.util.dasutil
import java.text.simpledateformat
/*
* available context bindings:
* selection iterable<dasobject>
* project project
* files files helper
*/
packagename = ""
etitypackagename = ""
tablecomment = ""
hasprimarykey = false
typemapping = [
(~/(?i)int/) : "integer",
(~/(?i)float|double|decimal|real/): "double",
(~/(?i)datetime|timestamp/) : "timestamp",
(~/(?i)date/) : "date",
(~/(?i)time/) : "java.sql.time",
(~/(?i)bit/) : "boolean",
(~/(?i)/) : "string"
]
//选择实体类包路径,选择的包路径,用于添加import包语句.
files.choosedirectoryandsave(unicodetostring("\\u9009\\u62e9\\u5b9e\\u4f53\\u7c7b\\u5305\\u8def\\u5f84")
, unicodetostring("\\u9009\\u62e9\\u7684\\u5305\\u8def\\u5f84\\u002c\\u7528\\u4e8e\\u6dfb\\u52a0\\u0069\\u006d\\u0070\\u006f\\u0072\\u0074\\u5305\\u8bed\\u53e5\\u002e")) { dir ->
generate(dir)
}
//选择mapper存放的包路径,选择的目录将生成mapper文件
files.choosedirectoryandsave(unicodetostring("\\u9009\\u62e9\\u004d\\u0061\\u0070\\u0070\\u0065\\u0072\\u5b58\\u653e\\u7684\\u5305\\u8def\\u5f84")
, unicodetostring("\\u9009\\u62e9\\u7684\\u76ee\\u5f55\\u5c06\\u751f\\u6210\\u004d\\u0061\\u0070\\u0070\\u0065\\u0072\\u6587\\u4ef6")) { dir ->
selection.filter { it instanceof dastable }.each { generate(it, dir) }
}
def generate(dir){
etitypackagename = dir.tostring().replaceall("\\\\", ".").replaceall("/", ".").replaceall("^.*src(\\.main\\.java\\.)?", "")
}
def generate(table, dir) {
def classname = javaname(table.getname(), true)
def tablename = table.getname()
def fields = calcfields(table)
packagename = getpackagename(dir)
//文件名的拼接
printwriter printwriter = new printwriter(new outputstreamwriter(new fileoutputstream(new file(dir, classname + "mapper.java")), "utf-8"))
printwriter.withprintwriter {out -> generate(out, classname, tablename, fields)}
}
// 获取包所在文件夹路径
def getpackagename(dir) {
return (dir.tostring().replaceall("\\\\", ".").replaceall("/", ".").replaceall("^.*src(\\.main\\.java\\.)?", "") + ";");//.substring(1)
}
def generate(out, classname, tablename, fields) {
out.println "package $packagename"
out.println "import org.apache.ibatis.annotations.*;"
set types = new hashset()
fields.each() {
types.add(it.type)
}
if (types.contains("timestamp")) {
out.println "import java.sql.timestamp;"
}
if (types.contains("date")) {
out.println "import java.util.date;"
}
out.println "import $etitypackagename.${classname};"
out.println "/**"
locale.setdefault(locale.china)
sdf = new simpledateformat()
//由groovy自动生成
out.println " * ${unicodetostring('\\u7531\\u0047\\u0072\\u006f\\u006f\\u0076\\u0079\\u81ea\\u52a8\\u751f\\u6210')} "
out.println " * <p>date: " + sdf.format(new java.util.date()) + ".</p>"
out.println " * description: $tablecomment"
out.println " * @see $classname"
out.println " * @author mr.wang"
out.println " */"
out.println "@mapper"
out.println "@cachenamespace"
out.println "public interface ${classname}mapper {"
//如果没有主键的表 则
if(!hasprimarykey){
//查找
out.println "\t/**"
//查找所有记录
out.println "\t * " + unicodetostring("\\u67e5\\u627e\\u6240\\u6709\\u8bb0\\u5f55")
out.println "\t * @return object or null"
out.println "\t */"
out.println "\t@select(\"select * from $tablename\")"
out.println "\t$classname find$classname();"
out.println ""
//修改
out.println "\t/**"
//修改对象属性对应的所有字段
out.println "\t * " + unicodetostring("\\u4fee\\u6539\\u5bf9\\u8c61\\u5c5e\\u6027\\u5bf9\\u5e94\\u7684\\u6240\\u6709\\u5b57\\u6bb5")
//要修改的对象,此对象应该是经过查询的对象
out.println "\t * @param ${javaname(classname, false)} " + unicodetostring("\\u8981\\u4fee\\u6539\\u7684\\u5bf9\\u8c61\\uff0c\\u6b64\\u5bf9\\u8c61\\u5e94\\u8be5\\u662f\\u7ecf\\u8fc7\\u67e5\\u8be2\\u7684\\u5bf9\\u8c61")
//是否有记录被修改
out.println "\t * @return true/false " + unicodetostring("\\u662f\\u5426\\u6709\\u8bb0\\u5f55\\u88ab\\u4fee\\u6539")
out.println "\t */"
out.print "\t@update(\"update $tablename "
first = true
fields.each(){
if(first){
out.print "set ${it.colname}=#{${it.name}}"
first = false
} else out.print ",${it.colname}=#{${it.name}}"
}
out.println "\")"
//********此处根据需要而定, 如果修改超过一条记录 因改为 int , 同理 删除的地方也是************//
out.println "\tboolean update$classname($classname ${javaname(classname, false)});"
//单字段修改
out.println ""
fields.each(){
out.println "\t/**"
//修改字段
out.println "\t * ${unicodetostring('\\u4fee\\u6539\\u5b57\\u6bb5')} ${it.name}"
out.println "\t * @param ${it.name} ${it.comment}"
//是否有记录被修改
out.println "\t * @return true/false " + unicodetostring("\\u662f\\u5426\\u6709\\u8bb0\\u5f55\\u88ab\\u4fee\\u6539")
out.println "\t */"
out.println "\t@update(\"update $tablename set ${it.colname}=#{${it.name}}\")"
out.println "\tboolean updatefiled${javaname(it.name,true)}(${it.type} ${it.name});"
out.println ""
}
out.println "}"
return
}
boolean first = false//判断是否为循环第一次,用于控制输出","等
//获取主键信息
def pk = [:]
fields.each() {
if(it.ispk) {
pk.put("name", it.name)
pk.put("colname", it.colname)
pk.put("type", it.type)
pk.put("comment", it.comment)
}
return false
}
//增
out.println "\t/**"
//添加记录
out.println "\t * " + unicodetostring("\\u6dfb\\u52a0\\u8bb0\\u5f55")
//要插入的对象,包含必要信息
out.println "\t * @param ${javaname(classname, false)} " + unicodetostring("\\u8981\\u63d2\\u5165\\u7684\\u5bf9\\u8c61\\u002c\\u5305\\u542b\\u5fc5\\u8981\\u4fe1\\u606f")
out.println "\t */"
out.print "\t@insert(\"insert into $tablename("
first = true
fields.each(){
if(first){
out.print "${it.colname}"
first = false
} else out.print ",${it.colname}"
}
out.print ") values ("
first = true
fields.each(){
if(first){
out.print "#{${it.name}}"
first = false
} else out.print ",#{${it.name}}"
}
out.println ")\")"
//是否需要将自动生成的键设置到对象中
out.println "\t@options(usegeneratedkeys = true, keyproperty = \"${pk.name}\")"
out.println "\tvoid add$classname($classname ${javaname(classname, false)});"
out.println ""
//删 @delete("delete from admin_role where id = #{roleid}")
out.println "\t/**"
//删除记录
out.println "\t * " + unicodetostring("\\u5220\\u9664\\u8bb0\\u5f55")
//【主键】
out.println "\t * @param ${pk.name} ${pk.comment}" + unicodetostring("\\u3010\\u4e3b\\u952e\\u3011")
//是否有记录被修改
out.println "\t * @return true/false " + unicodetostring("\\u662f\\u5426\\u6709\\u8bb0\\u5f55\\u88ab\\u4fee\\u6539")
out.println "\t */"
out.println "\t@delete(\"delete from $tablename where ${pk.colname} = #{${pk.name}}\")"
out.println "\tboolean delete${classname}byid(${pk.type} ${pk.name});"
//改
out.println "\t/**"
//修改参数对象中主键字段对应的记录
out.println "\t * " + unicodetostring("\\u4fee\\u6539\\u53c2\\u6570\\u5bf9\\u8c61\\u4e2d\\u4e3b\\u952e\\u5b57\\u6bb5\\u5bf9\\u5e94\\u7684\\u8bb0\\u5f55")
//要修改的对象,此对象应该是被查询的对象,并且必须包含主键
out.println "\t * @param ${javaname(classname, false)} " + unicodetostring("\\u8981\\u4fee\\u6539\\u7684\\u5bf9\\u8c61\\uff0c\\u6b64\\u5bf9\\u8c61\\u5e94\\u8be5\\u662f\\u88ab\\u67e5\\u8be2\\u7684\\u5bf9\\u8c61\\uff0c\\u5e76\\u4e14\\u5fc5\\u987b\\u5305\\u542b\\u4e3b\\u952e")
//是否有记录被修改
out.println "\t * @return true/false " + unicodetostring("\\u662f\\u5426\\u6709\\u8bb0\\u5f55\\u88ab\\u4fee\\u6539")
out.println "\t */"
out.print "\t@update(\"update $tablename "
first = true
fields.each(){
if(first){
out.print "set ${it.colname}=#{${it.name}}"
first = false
} else out.print ",${it.colname}=#{${it.name}}"
}
out.println " where ${pk.colname} = #{${pk.name}}\")"
out.println "\tboolean update$classname($classname ${javaname(classname, false)});"
out.println ""
//单字段修改
fields.each(){
if(it.ispk) return //主键跳过
out.println "\t/**"
//修改字段
out.println "\t * ${unicodetostring('\\u4fee\\u6539\\u5b57\\u6bb5')} ${it.name}"
out.println "\t * @param ${pk.name} ${pk.comment}"
out.println "\t * @param ${it.name} ${it.comment}"
//是否有记录被修改
out.println "\t * @return true/false " + unicodetostring("\\u662f\\u5426\\u6709\\u8bb0\\u5f55\\u88ab\\u4fee\\u6539")
out.println "\t */"
out.println "\t@update(\"update $tablename set ${it.colname}=#{${it.name}} where ${pk.colname} = #{${pk.name}}\")"
out.println "\tboolean updatefield${javaname(it.name,true)}(@param(\"${pk.name}\") ${pk.type} ${pk.name},@param(\"${it.name}\") ${it.type} ${it.name});"
out.println ""
}
//查
out.println "\t/**"
//通过主键 ${pk.name} 查询
out.println "\t * ${unicodetostring('\\u901a\\u8fc7\\u4e3b\\u952e')} ${pk.name}" + unicodetostring("\\u67e5\\u8be2")
out.println "\t * @param ${pk.name} ${pk.comment}" + unicodetostring("\\u3010\\u4e3b\\u952e\\u3011")
out.println "\t * @return object or null"
out.println "\t */"
out.println "\t@select(\"select * from $tablename where ${pk.colname} = #{${pk.name}}\")"
out.println "\t$classname get$classname(${pk.type} ${pk.name});"
//类结束
out.println "}"
}
def calcfields(table) {
hasprimarykey = dasutil.getprimarykey(table) == null ? false : true
tablecomment = table.getcomment()
dasutil.getcolumns(table).reduce([]) { fields, col ->
def spec = case.lower.apply(col.getdatatype().getspecification())
def typestr = typemapping.find { p, t -> p.matcher(spec).find() }.value
fields += [
colname : col.getname(),
name : javaname(col.getname(), false),
type : typestr,
comment: getcomment(col.getcomment()),
ispk : dasutil.isprimary(col),
isfk : dasutil.isindexcolumn(col)
]
}
}
def javaname(str, capitalize) {
def s = com.intellij.psi.codestyle.nameutil.splitnameintowords(str)
.collect { case.lower.apply(it).capitalize() }
.join("")
.replaceall(/[^\p{javajavaidentifierpart}[_]]/, "_")
capitalize || s.length() == 1? s : case.lower.apply(s[0]) + s[1..-1]
}
def isnotempty(content) {
return content != null && content.tostring().trim().length() > 0
}
//获取注释
def getcomment(comment){
if (isnotempty(comment)) {
return comment.tostring()
}
return ""
}
/**
* unicode转字符串
* 用于 文件注释,由于 groovy 编译器不支持中文
* @param unicode 编码为unicode的字符串
* @return 解码字符串
*/
def string unicodetostring(string unicode) {
stringbuffer sb = new stringbuffer();
string[] hex = unicode.split("\\\\u");
for (int i = 1; i < hex.length; i++) {
int index = integer.parseint(hex[i], 16);
sb.append((char) index);
}
return sb.tostring();
}
至于为何用unicode, 因为用中文乱码! 我也找不到怎么配置groovy编译器编码, 以上
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论