1. 入口类及关键类关系
1.1 入口类
spring cloud gateway webflux 模式的入口类是 gatewayautoconfiguration,这是整个 webflux 模式的"总指挥"。它负责配置所有 gateway 需要的组件。
@configuration(proxybeanmethods = false)
@conditionalonproperty(name = "spring.cloud.gateway.server.webflux.enabled", matchifmissing = true)
@enableconfigurationproperties
@autoconfigurebefore({ httphandlerautoconfiguration.class, webfluxautoconfiguration.class })
@autoconfigureafter({ gatewayreactiveloadbalancerclientautoconfiguration.class,
gatewayclasspathwarningautoconfiguration.class })
@conditionalonclass(dispatcherhandler.class)
public class gatewayautoconfiguration {
// 核心 bean 定义
}关键特性说明:
@autoconfigurebefore({ httphandlerautoconfiguration.class, webfluxautoconfiguration.class })- 这个很关键!gateway 必须在 webflux 的默认配置之前加载
- 为什么?因为 gateway 需要注册自己的
handlermapping(routepredicatehandlermapping) - 如果 webflux 的默认配置先加载,可能会注册其他的 handlermapping,导致路由冲突
- gateway 的 handlermapping 优先级更高,会优先处理请求
@conditionalonclass(dispatcherhandler.class)- 这个注解确保只有在 webflux 存在时才加载 gateway
dispatcherhandler是 webflux 的核心组件,类似于 webmvc 的dispatcherservlet- 如果没有 webflux,gateway webflux 模式就无法工作
@conditionalonproperty
# 可以通过配置控制是否启用
spring:
cloud:
gateway:
server:
webflux:
enabled: true # 默认启用,可以设置为 false 禁用配置的核心组件:
routelocator:路由定位器,负责提供路由列表filteringwebhandler:过滤器处理器,负责执行过滤器链routepredicatehandlermapping:路由匹配器,负责匹配请求到路由gatewayproperties:gateway 配置属性
1.2 关键类关系图
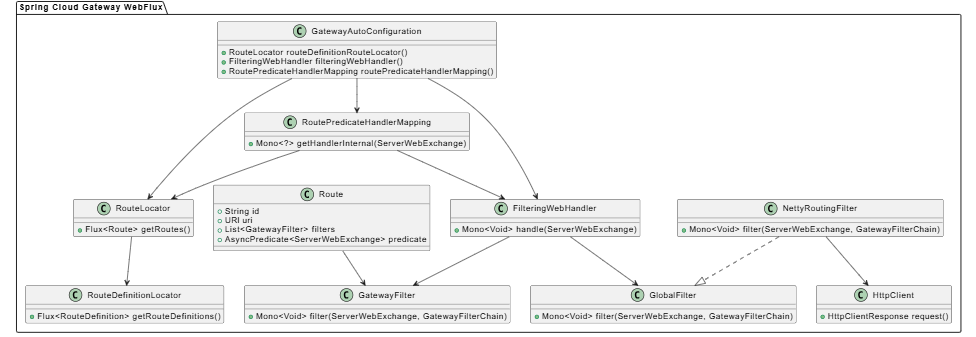
1.3 核心组件说明
routepredicatehandlermapping
这是 gateway 的路由匹配器,负责找到匹配的路由。它继承自 spring webflux 的 abstracthandlermapping。
工作原理:
@override
protected mono<?> gethandlerinternal(serverwebexchange exchange) {
// 1. 查找匹配的路由(异步操作)
return lookuproute(exchange)
.map(route -> {
// 2. 把路由信息存储到 exchange 的属性中
exchange.getattributes().put(gateway_route_attr, route);
// 3. 返回 filteringwebhandler 作为处理器
return webhandler;
});
}实际例子:
// 假设有这些路由配置
routes = [
{ id: "user-service", path: "/api/users/**", uri: "http://user-service" },
{ id: "order-service", path: "/api/orders/**", uri: "http://order-service" }
]
// 请求:get /api/users/123
// lookuproute() 会:
// 1. 遍历所有路由
// 2. 使用 asyncpredicate 异步匹配
// 3. 找到匹配的路由:user-service
// 4. 返回 filteringwebhandler关键点:
lookuproute()返回mono<route>,是异步的- 路由匹配使用
asyncpredicate,支持异步条件判断 - 匹配成功后,路由信息存储在
serverwebexchange的属性中
filteringwebhandler
这是 gateway 的核心请求处理器,负责执行过滤器链。它实现了 spring webflux 的 webhandler 接口。
工作原理:
@override
public mono<void> handle(serverwebexchange exchange) {
// 1. 从 exchange 中获取路由信息(路由匹配时设置的)
route route = exchange.getrequiredattribute(gateway_route_attr);
// 2. 获取合并后的过滤器列表(全局过滤器 + 路由过滤器)
list<gatewayfilter> combined = getcombinedfilters(route);
// 3. 创建过滤器链并执行
return new defaultgatewayfilterchain(combined).filter(exchange);
}实际例子:
// 假设路由配置了这些过滤器
route.filters = [
addrequestheaderfilter,
ratelimitfilter,
nettyroutingfilter // 最后一个,负责实际转发请求
]
// filteringwebhandler 会:
// 1. 合并全局过滤器和路由过滤器
// 2. 按 order 排序
// 3. 创建过滤器链
// 4. 依次执行过滤器过滤器链执行:
// 过滤器链的实现(责任链模式)
private static class defaultgatewayfilterchain implements gatewayfilterchain {
@override
public mono<void> filter(serverwebexchange exchange) {
return mono.defer(() -> {
if (this.index < filters.size()) {
gatewayfilter filter = filters.get(this.index);
// 创建下一个链节点
defaultgatewayfilterchain chain = new defaultgatewayfilterchain(this, this.index + 1);
// 执行当前过滤器,传入下一个链节点
return filter.filter(exchange, chain);
}
return mono.empty(); // 所有过滤器执行完毕
});
}
}routelocator
路由定位器,负责提供路由列表。gateway 支持多个 routelocator,可以组合使用。
工作原理:
@bean
@primary
public routelocator cachedcompositeroutelocator(list<routelocator> routelocators) {
// 1. 组合多个 routelocator
compositeroutelocator composite = new compositeroutelocator(
flux.fromiterable(routelocators)
);
// 2. 添加缓存(提高性能)
return new cachingroutelocator(composite);
}实际例子:
// 可以有多个 routelocator
routelocator[] locators = [
propertiesroutedefinitionlocator, // 从配置文件读取路由
discoveryclientroutedefinitionlocator, // 从服务发现读取路由
inmemoryroutedefinitionrepository // 从内存(api)读取路由
]
// compositeroutelocator 会合并所有路由
// 返回 flux<route>,包含所有路由路由来源:
配置文件:propertiesroutedefinitionlocator
spring:
cloud:
gateway:
routes:
- id: user-service
uri: http://localhost:8081服务发现:discoveryclientroutedefinitionlocator
// 自动从 eureka/consul 等服务注册中心发现服务 // 为每个服务自动创建路由
api 动态配置:inmemoryroutedefinitionrepository
// 通过 api 动态添加/删除路由 routedefinitionrepository.save(routedefinition);
2. 关键流程描述
2.1 请求处理流程时序图
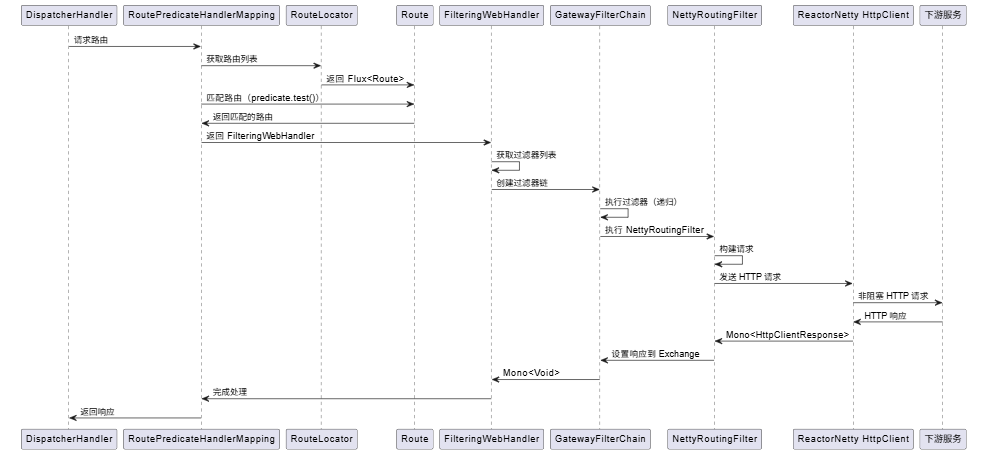
2.2 路由匹配流程
路由匹配是 gateway 的核心功能。让我们用一个实际例子来说明整个流程:
场景:客户端请求 get /api/users/123
详细流程:
dispatcherhandler 接收 http 请求
客户端 → dispatcherhandler → gateway
dispatcherhandler 是 webflux 的请求分发器,类似于 webmvc 的 dispatcherservlet
它会把请求交给合适的 handlermapping 处理
gateway 的 routepredicatehandlermapping 优先级很高,会优先处理
routepredicatehandlermapping 从 routelocator 获取所有路由
// 获取所有路由(返回 flux<route>,是响应式的)
flux<route> routes = routelocator.getroutes();
// 实际的路由列表可能是:
// [
// { id: "user-service", path: "/api/users/**", uri: "http://user-service" },
// { id: "order-service", path: "/api/orders/**", uri: "http://order-service" }
// ]routelocator 可能从多个来源获取路由(配置文件、服务发现、api)
返回的是 flux<route>,是响应式的流
使用 asyncpredicate 异步匹配路由
// 异步匹配路由
return routes
.filterwhen(route -> {
// 使用 asyncpredicate 异步匹配
return route.getpredicate().test(exchange);
})
.next(); // 返回第一个匹配的路由匹配过程:
// 路由1:user-service
asyncpredicate predicate1 = exchange -> {
string path = exchange.getrequest().getpath().value();
return mono.just(path.startswith("/api/users/")); // 异步返回 true/false
};
// 路径 "/api/users/123" 匹配 "/api/users/**" ✓
// 路由2:order-service
asyncpredicate predicate2 = exchange -> {
string path = exchange.getrequest().getpath().value();
return mono.just(path.startswith("/api/orders/")); // 异步返回 false
};
// 路径 "/api/users/123" 不匹配 "/api/orders/**" ✗- 使用
asyncpredicate异步匹配,支持异步条件判断 - 可以在这里做异步操作(比如查询 redis、数据库等)
- 返回
mono<boolean>,不会阻塞线程
找到匹配的路由后,将路由信息存储到 serverwebexchange 的属性中
// 匹配成功后 route matchedroute = ...; // user-service 路由 // 存储路由信息到 exchange 的属性中 exchange.getattributes().put(gateway_route_attr, matchedroute); exchange.getattributes().put(gateway_request_url_attr, matchedroute.geturi());
- 路由信息存储在
serverwebexchange的属性中 - 后续的过滤器可以从这里获取路由信息
- 比如
nettyroutingfilter会从这里获取目标 uri
返回 filteringwebhandler 作为处理器
// 返回 filteringwebhandler return mono.just(webhandler);
filteringwebhandler会负责执行过滤器链- 最终会调用
nettyroutingfilter转发请求到下游服务
完整示例:
# 配置文件
spring:
cloud:
gateway:
routes:
- id: user-service
uri: http://user-service:8081
predicates:
- path=/api/users/**
- method=get匹配过程:
- 请求
get /api/users/123到达 - 路径
/api/users/123匹配/api/users/**✓ - 方法
get匹配get✓ - 找到匹配的路由
user-service - 返回
filteringwebhandler,目标 uri 是http://user-service:8081
2.3 过滤器链执行流程
过滤器链是 gateway 的核心机制。让我们用一个实际例子来说明:
场景:请求已经匹配到路由,现在需要执行过滤器链
详细流程:
filteringwebhandler 从路由中获取过滤器列表
route route = exchange.getrequiredattribute(gateway_route_attr); list<gatewayfilter> routefilters = route.getfilters(); // 假设路由配置了这些过滤器: // [addrequestheaderfilter, ratelimitfilter]
- 从路由中获取路由级别的过滤器
- 这些过滤器只应用于当前路由
合并全局过滤器和路由过滤器,按 order 排序
// 全局过滤器(应用于所有路由)
list<globalfilter> globalfilters = [
loadbalancerclientfilter, // order: 10100
nettyroutingfilter, // order: ordered.lowest_precedence
nettywriteresponsefilter // order: ordered.lowest_precedence - 1
];
// 路由过滤器
list<gatewayfilter> routefilters = [
addrequestheaderfilter, // order: 1000
ratelimitfilter // order: -100
];
// 合并并排序
list<gatewayfilter> combined = [
ratelimitfilter, // -100 (最高优先级)
addrequestheaderfilter, // 1000
loadbalancerclientfilter, // 10100
nettyroutingfilter, // lowest_precedence
nettywriteresponsefilter // lowest_precedence - 1
];- 全局过滤器 + 路由过滤器 = 合并后的过滤器列表
- 按
order排序,数字越小优先级越高 ordered.lowest_precedence是最大整数,优先级最低
创建 defaultgatewayfilterchain,实现责任链模式
// 创建过滤器链
defaultgatewayfilterchain chain = new defaultgatewayfilterchain(combined);
// 过滤器链的内部实现
private static class defaultgatewayfilterchain implements gatewayfilterchain {
private final int index; // 当前执行的过滤器索引
private final list<gatewayfilter> filters;
@override
public mono<void> filter(serverwebexchange exchange) {
return mono.defer(() -> {
if (this.index < filters.size()) {
gatewayfilter filter = filters.get(this.index);
// 创建下一个链节点
defaultgatewayfilterchain nextchain =
new defaultgatewayfilterchain(this, this.index + 1);
// 执行当前过滤器,传入下一个链节点
return filter.filter(exchange, nextchain);
}
return mono.empty(); // 所有过滤器执行完毕
});
}
}- 使用责任链模式,每个过滤器都可以决定是否继续执行下一个过滤器
- 通过递归创建链节点来实现
递归执行过滤器
// 执行流程(简化版)
ratelimitfilter.filter(exchange, chain1)
-> 检查限流
-> chain1.filter(exchange) // 调用下一个过滤器
-> addrequestheaderfilter.filter(exchange, chain2)
-> 添加请求头
-> chain2.filter(exchange) // 调用下一个过滤器
-> loadbalancerclientfilter.filter(exchange, chain3)
-> 负载均衡选择实例
-> chain3.filter(exchange)
-> nettyroutingfilter.filter(exchange, chain4)
-> 转发请求到下游服务
-> chain4.filter(exchange)
-> nettywriteresponsefilter.filter(exchange, chain5)
-> 写入响应
-> chain5.filter(exchange)
-> mono.empty() // 所有过滤器执行完毕- 每个过滤器调用
chain.filter(exchange)来执行下一个过滤器 - 如果某个过滤器不想继续执行,可以不调用
chain.filter() - 比如限流过滤器,如果限流了,就直接返回错误,不继续执行
nettyroutingfilter 作为最后一个过滤器,执行实际的 http 请求
// nettyroutingfilter 的实现(简化版)
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
uri requesturl = exchange.getrequiredattribute(gateway_request_url_attr);
// 使用 reactor netty httpclient 发送请求(非阻塞)
return httpclient.get()
.uri(requesturl)
.send((req, nettyoutbound) -> nettyoutbound.send(request.getbody()))
.responseconnection((res, connection) -> {
// 设置响应到 exchange
exchange.getattributes().put(client_response_attr, res);
return mono.just(res);
})
.then(chain.filter(exchange)); // 继续执行下一个过滤器
}nettyroutingfilter使用 reactor netty 的httpclient发送请求- 这是非阻塞的,线程不会在这里等待
- 响应到达后,会继续执行下一个过滤器(
nettywriteresponsefilter)
响应通过 mono 链式返回
// 响应返回流程
nettywriteresponsefilter.filter(exchange, chain)
-> 写入响应到客户端
-> mono.empty() // 完成
-> 返回给 nettyroutingfilter
-> 返回给 loadbalancerclientfilter
-> 返回给 addrequestheaderfilter
-> 返回给 ratelimitfilter
-> 返回给 filteringwebhandler
-> 返回给 routepredicatehandlermapping
-> 返回给 dispatcherhandler
-> 返回给客户端- 响应通过 mono 链式返回
- 每个过滤器都可以修改响应
- 最终返回给客户端
关键点:
- 过滤器链是响应式的,不会阻塞线程
- 每个过滤器都可以修改请求或响应
- 过滤器可以决定是否继续执行下一个过滤器
nettyroutingfilter是最后一个过滤器,负责实际转发请求
2.4 响应式 http 请求
flux<httpclientresponse> responseflux = httpclient
.headers(headers -> headers.add(httpheaders))
.request(method)
.uri(url)
.send((req, nettyoutbound) -> nettyoutbound.send(request.getbody()))
.responseconnection((res, connection) -> {
// 处理响应
return mono.just(res);
});关键点:
- 使用 reactor netty 的非阻塞 http 客户端
- 基于 reactive streams 的响应式编程模型
- 支持背压(backpressure)控制
3. 实现关键点说明
3.1 响应式编程模型
webflux 模式完全基于响应式编程,使用 project reactor 的 mono 和 flux。这是 webflux 和 webmvc 最根本的区别。
基本概念:
public interface globalfilter {
mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain);
}mono 和 flux 是什么?
mono:表示 0 或 1 个元素的异步序列
mono<string> name = mono.just("spring"); // 一个值
mono<string> empty = mono.empty(); // 0 个值
mono<string> async = mono.fromcallable(() -> {
// 异步操作
return fetchnamefromdatabase();
});flux:表示 0 到 n 个元素的异步序列
flux<string> names = flux.just("spring", "cloud", "gateway"); // 多个值
flux<string> stream = flux.interval(duration.ofseconds(1))
.map(i -> "event " + i); // 无限流实际例子:
// webmvc 方式(阻塞)
public serverresponse handle(serverrequest request) {
user user = userservice.getuser(userid); // 阻塞等待
return serverresponse.ok().body(user);
}
// webflux 方式(非阻塞)
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
return userservice.getuser(userid) // 返回 mono<user>,不阻塞
.flatmap(user -> {
// 用户数据到达后才执行这里
exchange.getattributes().put("user", user);
return chain.filter(exchange);
});
}优势说明:
非阻塞 i/o,提高并发性能
// 非阻塞调用下游服务
return httpclient.get()
.uri("http://backend-service/api/data")
.retrieve()
.bodytomono(string.class) // 返回 mono,不阻塞线程
.flatmap(data -> {
// 数据到达后才执行这里
return processdata(data);
});
// 在等待响应的这段时间,线程可以处理其他请求- 线程不会阻塞,可以处理其他请求
- 一个线程可以处理多个请求
- 并发性能大幅提升
支持背压,防止内存溢出
// 背压示例
flux<string> datastream = getdatastream(); // 数据流
datastream
.limitrate(100) // 限制速率,防止内存溢出
.subscribe(data -> {
// 处理数据
processdata(data);
});- 如果生产者生产数据太快,消费者可以告诉生产者慢一点
- 防止内存溢出
- 这是 reactive streams 规范的核心特性
资源利用率高,少量线程处理大量请求
场景:处理 10000 并发请求 webmvc: 需要 500 线程,内存 ~500mb webflux: 只需要 16 线程,内存 ~100mb 资源利用率提升 5 倍!
3.2 过滤器链模式
gateway 使用责任链模式实现过滤器链。这是 gateway 的核心设计模式之一。
责任链模式:
private static class defaultgatewayfilterchain implements gatewayfilterchain {
private final int index; // 当前过滤器索引
private final list<gatewayfilter> filters;
@override
public mono<void> filter(serverwebexchange exchange) {
return mono.defer(() -> {
if (this.index < filters.size()) {
gatewayfilter filter = filters.get(this.index);
// 创建下一个链节点
defaultgatewayfilterchain chain =
new defaultgatewayfilterchain(this, this.index + 1);
// 执行当前过滤器,传入下一个链节点
return filter.filter(exchange, chain);
}
return mono.empty(); // 所有过滤器执行完毕
});
}
}实际例子:
// 假设有这些过滤器
list<gatewayfilter> filters = [
ratelimitfilter, // index 0
addrequestheaderfilter, // index 1
nettyroutingfilter // index 2
];
// 执行流程
chain0.filter(exchange) // index = 0
-> ratelimitfilter.filter(exchange, chain1) // index = 1
-> 检查限流
-> chain1.filter(exchange)
-> addrequestheaderfilter.filter(exchange, chain2) // index = 2
-> 添加请求头
-> chain2.filter(exchange)
-> nettyroutingfilter.filter(exchange, chain3) // index = 3
-> 转发请求
-> chain3.filter(exchange)
-> index (3) >= filters.size(),返回 mono.empty()过滤器类型:
globalfilter - 全局过滤器
@component
public class customglobalfilter implements globalfilter, ordered {
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
// 这个过滤器会应用于所有路由
return chain.filter(exchange);
}
@override
public int getorder() {
return -1; // 高优先级
}
}- 应用于所有路由
- 比如认证、日志、监控等
gatewayfilter - 路由过滤器
// 通过配置定义的路由过滤器
spring:
cloud:
gateway:
routes:
- id: user-service
filters:
- addrequestheader=x-user-id, 123 # 路由过滤器- 只应用于特定路由
- 通过配置文件或 api 定义
ordered - 控制执行顺序
// 通过 order 接口控制执行顺序
public class ratelimitfilter implements globalfilter, ordered {
@override
public int getorder() {
return -100; // 数字越小,优先级越高
}
}
public class loggingfilter implements globalfilter, ordered {
@override
public int getorder() {
return 1000; // 优先级较低
}
}
// 执行顺序:ratelimitfilter (-100) -> loggingfilter (1000)过滤器可以做什么?
修改请求
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
serverhttprequest request = exchange.getrequest();
serverhttprequest modifiedrequest = request.mutate()
.header("x-request-id", uuid.randomuuid().tostring())
.build();
return chain.filter(exchange.mutate().request(modifiedrequest).build());
}
修改响应
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
return chain.filter(exchange).then(mono.fromrunnable(() -> {
serverhttpresponse response = exchange.getresponse();
response.getheaders().add("x-response-time",
string.valueof(system.currenttimemillis()));
}));
}
中断执行
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
if (isratelimited(exchange)) {
// 限流了,直接返回错误,不继续执行
exchange.getresponse().setstatuscode(httpstatus.too_many_requests);
return exchange.getresponse().setcomplete();
}
return chain.filter(exchange); // 继续执行
}
3.3 异步谓词(asyncpredicate)
路由匹配使用异步谓词,支持异步条件判断:
public interface asyncpredicate<t> {
mono<boolean> test(t t);
}
支持的谓词:
- path route predicate
- method route predicate
- header route predicate
- host route predicate
- query route predicate
- remoteaddr route predicate
- weight route predicate
3.4 netty 集成
使用 reactor netty 作为底层 http 客户端,提供高性能的非阻塞 i/o:
public class nettyroutingfilter implements globalfilter {
private final httpclient httpclient;
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
// 使用 reactor netty httpclient 发送请求
flux<httpclientresponse> responseflux = httpclient
.request(method)
.uri(url)
.send(...)
.responseconnection(...);
}
}特性:
- 基于 netty 的事件驱动模型
- 支持 http/1.1 和 http/2
- 支持 websocket
- 连接池管理
3.5 路由缓存
支持路由过滤器缓存,提高性能:
private final concurrenthashmap<route, list<gatewayfilter>> routefiltermap = new concurrenthashmap();
protected list<gatewayfilter> getcombinedfilters(route route) {
if (this.routefiltercacheenabled) {
return routefiltermap.computeifabsent(route, this::getallfilters);
}
return getallfilters(route);
}4. 总结说明
4.1 架构特点
- 响应式编程: 完全基于 project reactor 的响应式编程模型
- 非阻塞 i/o: 使用 reactor netty 实现非阻塞 http 通信
- 高并发性能: 少量线程处理大量并发请求
- 背压支持: 支持 reactive streams 的背压机制
4.2 适用场景
- 高并发、高吞吐量的 api 网关场景
- 需要处理大量长连接(如 websocket)
- 微服务架构中的统一入口
- 需要流式处理(streaming)的场景
4.3 关键优势
- 高性能: 非阻塞 i/o 提供更高的吞吐量
- 资源高效: 少量线程处理大量请求,资源利用率高
- 可扩展性: 响应式模型支持更好的水平扩展
- 功能丰富: 支持 http/2、websocket、grpc 等协议
4.4 局限性
- 学习曲线: 需要理解响应式编程模型
- 调试困难: 异步调用栈较难调试
- 阻塞风险: 如果在响应式链中执行阻塞操作,会降低性能
- 内存管理: 需要理解背压机制,避免内存问题
4.5 最佳实践
- 避免阻塞操作: 不要在响应式链中执行阻塞 i/o
- 合理使用背压: 理解背压机制,合理配置缓冲区
- 监控和指标: 使用 spring boot actuator 监控 gateway 性能
- 过滤器顺序: 合理设置过滤器顺序,避免不必要的处理
到此这篇关于spring cloud gateway webflux 模式架构分析的文章就介绍到这了,更多相关spring cloud gateway webflux 模式架构分析内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论