pandas 分层索引
到目前为止,我们主要关注的是一维和二维数据,分别存储在 pandas 的 series 和 dataframe 对象中。但很多时候,存储更高维度的数据——即由多个键索引的数据——是很有用的。
早期的 pandas 版本提供了 panel 和 panel4d 对象,可以被视为二维 dataframe 的三维或四维类似物,但在实际使用中它们有些笨重。处理高维数据更常见的模式是利用分层索引(也称为多重索引),在单个索引中包含多个索引层级。通过这种方式,更高维度的数据可以紧凑地表示在熟悉的一维 series 和二维 dataframe 对象中。
(如果你对具有 pandas 风格灵活索引的真正n维数组感兴趣,可以了解优秀的 xarray 包。)
在本章中,我们将探讨 multiindex 对象的直接创建;在多重索引数据上进行索引、切片和统计计算时的注意事项;以及在简单和分层索引数据表示之间转换的实用方法。
我们从标准导入开始:
import pandas as pd import numpy as np
多重索引的 series
让我们从思考如何在一维 series 中表示二维数据开始。
为了具体说明,我们将考虑一个数据序列,其中每个数据点都有一个字符和一个数字键。
糟糕的方式
假设你想跟踪两个不同年份的各州数据。利用我们已经介绍过的 pandas 工具,你可能会倾向于直接使用 python 元组作为键:
index = [('california', 2010), ('california', 2020),
('new york', 2010), ('new york', 2020),
('texas', 2010), ('texas', 2020)]
populations = [37253956, 39538223,
19378102, 20201249,
25145561, 29145505]
pop = pd.series(populations, index=index)
pop
(california, 2010) 37253956 (california, 2020) 39538223 (new york, 2010) 19378102 (new york, 2020) 20201249 (texas, 2010) 25145561 (texas, 2020) 29145505 dtype: int64
使用这种索引方案,你可以直接根据元组索引对 series 进行索引或切片:
pop[('california', 2020):('texas', 2010)]
(california, 2020) 39538223 (new york, 2010) 19378102 (new york, 2020) 20201249 (texas, 2010) 25145561 dtype: int64
但便利也仅止于此。例如,如果你需要选择所有 2010 年的数据,你就需要进行一些繁琐(而且可能很慢)的数据处理才能实现:
pop[[i for i in pop.index if i[1] == 2010]]
(california, 2010) 37253956 (new york, 2010) 19378102 (texas, 2010) 25145561 dtype: int64
这确实得到了想要的结果,但相比我们已经习惯的 pandas 切片语法,这种方式不够简洁(对于大型数据集来说也不够高效)。
更好的方式:pandas 的 multiindex
幸运的是,pandas 提供了更好的方法。
我们基于元组的索引本质上就是一种初级的多重索引,而 pandas 的 multiindex 类型为我们提供了所需的各种操作。
我们可以如下通过元组创建一个多重索引:
index = pd.multiindex.from_tuples(index)
multiindex 表示多个索引层级——在本例中为州名和年份——以及为每个数据点编码这些层级的多个标签。
如果我们用这个 multiindex 重新索引我们的 series,就可以看到数据的分层表示:
pop = pop.reindex(index) pop
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
在 series 的表示中,前两列显示了多重索引的值,第三列显示了数据。
请注意,第一列中有些条目是空白的:在这种多重索引的表示中,任何空白条目都表示与上一行相同的值。
现在,如果我们想访问第二层索引为 2020 的所有数据,可以使用 pandas 的切片语法:
pop[:, 2020]
california 39538223 new york 20201249 texas 29145505 dtype: int64
结果是一个只包含我们感兴趣键的单层索引 series。
这种语法比我们一开始用元组实现的多重索引方案要方便得多(操作效率也高得多)。
接下来我们将进一步讨论这种针对分层索引数据的索引操作。
多重索引作为额外的维度
你可能还注意到:我们其实可以用带有索引和列标签的普通 dataframe 来存储相同的数据。
事实上,pandas 的设计正是基于这种等价性。unstack 方法可以迅速将一个多重索引的 series 转换为常规索引的 dataframe:
pop_df = pop.unstack() pop_df
| 2010 | 2020 | |
|---|---|---|
| california | 37253956 | 39538223 |
| new york | 19378102 | 20201249 |
| texas | 25145561 | 29145505 |
自然而然,stack 方法则提供了相反的操作:
pop_df.stack()
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
看到这里,你可能会想,为什么我们还要费心使用分层索引呢?
原因很简单:正如我们能够利用多重索引在一维的 series 中操作二维数据一样,我们也可以用它在 series 或 dataframe 中操作三维或更多维度的数据。
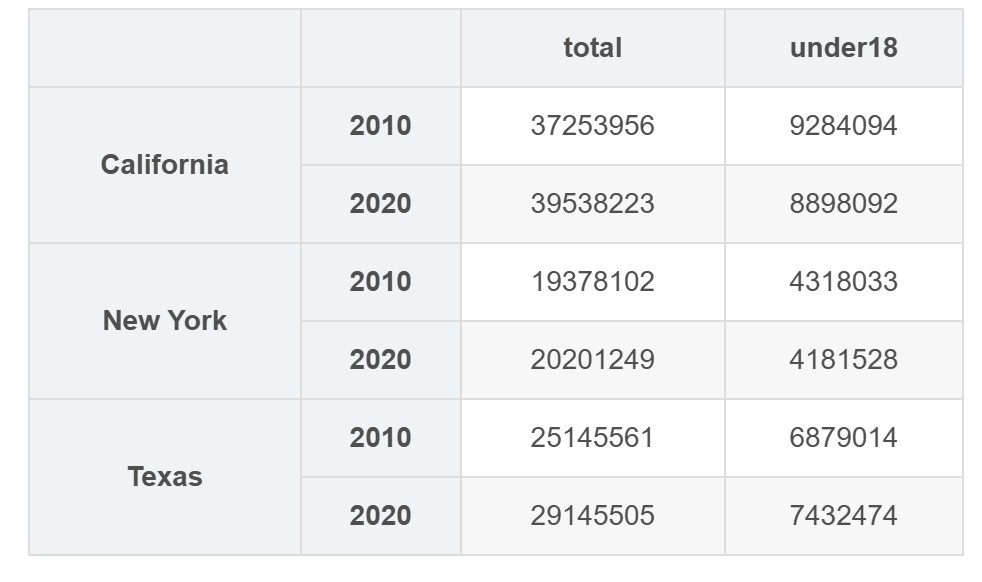
多重索引中的每增加一个层级,就代表数据的一个额外维度;利用这一特性,我们可以更灵活地表示各种类型的数据。具体来说,我们可能希望为每个州的每一年添加另一列人口统计数据(比如 18 岁以下人口);有了 multiindex,只需在 dataframe 中添加一列即可轻松实现:
pop_df = pd.dataframe({'total': pop,
'under18': [9284094, 8898092,
4318033, 4181528,
6879014, 7432474]})
pop_df
| total | under18 | ||
|---|---|---|---|
| california | 2010 | 37253956 | 9284094 |
| 2020 | 39538223 | 8898092 | |
| new york | 2010 | 19378102 | 4318033 |
| 2020 | 20201249 | 4181528 | |
| texas | 2010 | 25145561 | 6879014 |
| 2020 | 29145505 | 7432474 |
此外,pandas中的数据操作中讨论的所有 ufuncs 和其他功能同样适用于分层索引。
下面我们根据上述数据,按年份计算 18 岁以下人口所占比例:
f_u18 = pop_df['under18'] / pop_df['total'] f_u18.unstack()
| 2010 | 2020 | |
|---|---|---|
| california | 0.249211 | 0.225050 |
| new york | 0.222831 | 0.206994 |
| texas | 0.273568 | 0.255013 |
这使我们能够轻松快速地操作和探索高维数据。
多重索引的创建方法
构建多重索引的 series 或 dataframe 最直接的方法,就是将两个或更多索引数组的列表直接传递给构造函数。例如:
df = pd.dataframe(np.random.rand(4, 2),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=['data1', 'data2'])
df
| data1 | data2 | ||
|---|---|---|---|
| a | 1 | 0.626833 | 0.939326 |
| 2 | 0.824948 | 0.823318 | |
| b | 1 | 0.953831 | 0.173091 |
| 2 | 0.371334 | 0.779618 |
创建 multiindex 的工作是在后台完成的。
类似地,如果你传递一个以合适元组为键的字典,pandas 会自动识别并默认使用 multiindex:
data = {('california', 2010): 37253956,
('california', 2020): 39538223,
('new york', 2010): 19378102,
('new york', 2020): 20201249,
('texas', 2010): 25145561,
('texas', 2020): 29145505}
pd.series(data)
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
尽管如此,有时显式创建一个 multiindex 也是很有用的;接下来我们将介绍几种实现这一目标的方法。
显式 multiindex 构造器
为了更灵活地构建索引,你可以使用 pd.multiindex 类中提供的构造方法。
例如,正如我们之前所做的,可以通过简单的数组列表(每个层级的索引值)来构造一个 multiindex:
pd.multiindex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]])
multiindex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
)
或者,你可以通过一个元组列表(每个元组给出每个数据点的多重索引值)来构造它:
pd.multiindex.from_tuples([('a', 1), ('a', 2), ('b', 1), ('b', 2)])
multiindex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
)
你甚至可以通过单个索引的笛卡尔积来构造它:
pd.multiindex.from_product([['a', 'b'], [1, 2]])
multiindex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
)
类似地,你可以通过直接传递 levels(每个层级可用索引值的列表)和 codes(引用这些标签的编码列表)来使用其内部编码方式构造一个 multiindex:
pd.multiindex(levels=[['a', 'b'], [1, 2]],
codes=[[0, 0, 1, 1], [0, 1, 0, 1]])
multiindex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
)
这些对象中的任何一个都可以作为 index 参数传递给 series 或 dataframe 的构造函数,或者传递给已有 series 或 dataframe 的 reindex 方法。
multiindex 层级命名
有时候,为 multiindex 的各层级命名会很方便。
这可以通过向前面讨论过的任意一个 multiindex 构造器传递 names 参数来实现,或者事后设置索引的 names 属性也可以:
pop.index.names = ['state', 'year'] pop
state year
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
对于更复杂的数据集,这是一种有助于追踪各索引值含义的实用方法。
列的 multiindex
在 dataframe 中,行和列是完全对称的,正如行可以有多级索引,列同样也可以有多级索引。
请看下面这个例子,它模拟了一些(较为真实的)医疗数据:
# 分层索引和分层列
index = pd.multiindex.from_product([[2013, 2014], [1, 2]],
names=['year', 'visit'])
columns = pd.multiindex.from_product([['bob', 'guido', 'sue'], ['hr', 'temp']],
names=['subject', 'type'])
# 数据模拟
data = np.round(np.random.randn(4, 6), 1)
data[:, ::2] *= 10
data += 37
# 创建 dataframe
health_data = pd.dataframe(data, index=index, columns=columns)
health_data
| subject | bob | guido | sue | ||||
|---|---|---|---|---|---|---|---|
| type | hr | temp | hr | temp | hr | temp | |
| year | visit | ||||||
| 2013 | 1 | 39.0 | 36.1 | 36.0 | 37.3 | 25.0 | 37.4 |
| 2 | 43.0 | 36.1 | 33.0 | 38.3 | 37.0 | 37.7 | |
| 2014 | 1 | 60.0 | 36.6 | 9.0 | 36.9 | 37.0 | 37.5 |
| 2 | 43.0 | 37.3 | 24.0 | 37.6 | 41.0 | 34.8 | |
这本质上是一个四维数据,其中维度分别是受试者、测量类型、年份和访问次数。
有了这样的结构,我们可以按人的名字索引顶层列,从而获得只包含该人信息的完整 dataframe:
health_data['guido']
| type | hr | temp | |
|---|---|---|---|
| year | visit | ||
| 2013 | 1 | 36.0 | 37.3 |
| 2 | 33.0 | 38.3 | |
| 2014 | 1 | 9.0 | 36.9 |
| 2 | 24.0 | 37.6 |
多重索引的索引与切片
对 multiindex 进行索引和切片的设计非常直观,如果你将索引看作是增加的维度会更容易理解。
我们将首先介绍对多重索引的 series 进行索引的方法,然后再介绍对多重索引的 dataframe 对象进行索引的方法。
多重索引的 series
来看我们之前见过的州人口多重索引 series 示例:
pop
state year
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
我们可以通过使用多个索引项来访问单个元素:
pop['california', 2010]
np.int64(37253956)
multiindex 还支持部分索引,即只索引索引中的某一层级。
结果是另一个 series,并保留低层级的索引:
pop['california']
year 2010 37253956 2020 39538223 dtype: int64
只要 multiindex 已排序,也可以进行部分切片:
pop.loc['california':'new york']
state year
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
dtype: int64
对于已排序的索引,可以通过在第一个索引位置传递一个空切片,实现对低层级的部分索引:
pop[:, 2010]
state california 37253956 new york 19378102 texas 25145561 dtype: int64
其他类型的索引和选择(详见数据索引与选择)同样适用;例如,可以使用布尔掩码进行选择:
pop[pop > 22000000]
state year
california 2010 37253956
2020 39538223
texas 2010 25145561
2020 29145505
dtype: int64
花式索引(fancy indexing)同样适用:
pop[['california', 'texas']]
state year
california 2010 37253956
2020 39538223
texas 2010 25145561
2020 29145505
dtype: int64
多重索引的 dataframe
多重索引的 dataframe 具有类似的行为。
来看我们之前的医疗数据玩具 dataframe 示例:
health_data
| subject | bob | guido | sue | ||||
|---|---|---|---|---|---|---|---|
| type | hr | temp | hr | temp | hr | temp | |
| year | visit | ||||||
| 2013 | 1 | 39.0 | 36.1 | 36.0 | 37.3 | 25.0 | 37.4 |
| 2 | 43.0 | 36.1 | 33.0 | 38.3 | 37.0 | 37.7 | |
| 2014 | 1 | 60.0 | 36.6 | 9.0 | 36.9 | 37.0 | 37.5 |
| 2 | 43.0 | 37.3 | 24.0 | 37.6 | 41.0 | 34.8 | |
请记住,在 dataframe 中列是主要的索引轴,对于多重索引的 series,所用的语法同样适用于列。
例如,我们可以通过一个简单的操作获取 guido 的心率数据:
health_data['guido', 'hr']
year visit
2013 1 36.0
2 33.0
2014 1 9.0
2 24.0
name: (guido, hr), dtype: float64
同样地,和单层索引的情况一样,我们可以使用在数据索引与选择中介绍的 loc、iloc 和 ix 索引器。例如:
health_data.iloc[:2, :2]
| subject | bob | ||
|---|---|---|---|
| type | hr | temp | |
| year | visit | ||
| 2013 | 1 | 39.0 | 36.1 |
| 2 | 43.0 | 36.1 | |
这些索引器为底层的二维数据提供了类似数组的视图,但在 loc 或 iloc 中,每个单独的索引都可以传递一个包含多个索引的元组。例如:
health_data.loc[:, ('bob', 'hr')]
year visit
2013 1 39.0
2 43.0
2014 1 60.0
2 43.0
name: (bob, hr), dtype: float64
在这些索引元组中使用切片并不是特别方便;尝试在元组中创建切片会导致语法错误:
health_data.loc[(:, 1), (:, 'hr')]
cell in[32], line 1
health_data.loc[(:, 1), (:, 'hr')]
^
syntaxerror: invalid syntax
你可以通过显式构建所需的切片(使用 python 内置的 slice 函数)来实现这一点,但在这种情况下,更好的方法是使用 pandas 专门为此场景提供的 indexslice 对象。
例如:
idx = pd.indexslice health_data.loc[idx[:, 1], idx[:, 'hr']]
| subject | bob | guido | sue | |
|---|---|---|---|---|
| type | hr | hr | hr | |
| year | visit | |||
| 2013 | 1 | 39.0 | 36.0 | 25.0 |
| 2014 | 1 | 60.0 | 9.0 | 37.0 |
如你所见,有许多方法可以与多重索引的 series 和 dataframe 数据进行交互。正如本书中的许多工具一样,最好的熟悉方式就是亲自尝试!
重排多重索引
处理多重索引数据的关键之一是学会如何有效地转换数据。
有许多操作可以在不丢失任何信息的前提下,重新排列数据集,以便进行各种计算。
我们在 stack 和 unstack 方法中已经简单见过这种操作,但实际上还有更多方法可以精细地控制分层索引与列之间的数据重排,下面我们将进行详细探讨。
已排序与未排序的索引
前面我曾简要提到一个注意事项,这里需要特别强调:
许多 multiindex 的切片操作如果索引未排序会失败。
让我们仔细看看这个问题。
我们先创建一些简单的多重索引数据,其中索引不是按字典序排序的:
index = pd.multiindex.from_product([['a', 'c', 'b'], [1, 2]]) data = pd.series(np.random.rand(6), index=index) data.index.names = ['char', 'int'] data
char int
a 1 0.252857
2 0.342139
c 1 0.732484
2 0.740275
b 1 0.478320
2 0.624116
dtype: float64
如果我们尝试对这个索引进行部分切片,将会导致错误:
try:
data['a':'b']
except keyerror as e:
print("keyerror", e)
keyerror 'key length (1) was greater than multiindex lexsort depth (0)'
虽然从错误信息中并不十分清楚,但这实际上是由于 multiindex 没有排序造成的。
出于多种原因,部分切片和其他类似操作要求 multiindex 的各层级必须是有序(即字典序)的。
pandas 提供了许多便捷方法来进行这种排序,比如 dataframe 的 sort_index 和 sortlevel 方法。
这里我们将使用最简单的 sort_index 方法:
data = data.sort_index() data
char int
a 1 0.252857
2 0.342139
b 1 0.478320
2 0.624116
c 1 0.732484
2 0.740275
dtype: float64
通过这种方式对索引进行排序后,部分切片将如预期般工作:
data['a':'b']
char int
a 1 0.252857
2 0.342139
b 1 0.478320
2 0.624116
dtype: float64
索引的堆叠与反堆叠
如前所述,我们可以将数据集从堆叠的多重索引转换为简单的二维表示,并可选指定要使用的层级:
pop.unstack(level=0)
| state | california | new york | texas |
|---|---|---|---|
| year | |||
| 2010 | 37253956 | 19378102 | 25145561 |
| 2020 | 39538223 | 20201249 | 29145505 |
pop.unstack(level=1)
| year | 2010 | 2020 |
|---|---|---|
| state | ||
| california | 37253956 | 39538223 |
| new york | 19378102 | 20201249 |
| texas | 25145561 | 29145505 |
unstack 的反操作是 stack,在这里可以用来恢复原始的 series:
pop.unstack().stack()
state year
california 2010 37253956
2020 39538223
new york 2010 19378102
2020 20201249
texas 2010 25145561
2020 29145505
dtype: int64
索引的设置与重置
重排分层数据的另一种方式是将索引标签转换为列,这可以通过 reset_index 方法实现。
对人口字典调用该方法会得到一个包含 state 和 year 列的 dataframe,这些信息原本存储在索引中。
为了更清晰,我们还可以为数据列指定名称,使其在列表示中更易理解:
pop_flat = pop.reset_index(name='population') pop_flat
| state | year | population | |
|---|---|---|---|
| 0 | california | 2010 | 37253956 |
| 1 | california | 2020 | 39538223 |
| 2 | new york | 2010 | 19378102 |
| 3 | new york | 2020 | 20201249 |
| 4 | texas | 2010 | 25145561 |
| 5 | texas | 2020 | 29145505 |
一种常见的模式是根据列的值构建 multiindex(多重索引)。
这可以通过 dataframe 的 set_index 方法实现,该方法会返回一个具有多级索引的 dataframe:
pop_flat.set_index(['state', 'year'])
| population | ||
|---|---|---|
| state | year | |
| california | 2010 | 37253956 |
| 2020 | 39538223 | |
| new york | 2010 | 19378102 |
| 2020 | 20201249 | |
| texas | 2010 | 25145561 |
| 2020 | 29145505 |
在实际操作中,这种类型的重新索引是探索真实世界数据集时最有用的模式之一。
总结
本笔记系统介绍了 pandas 的分层索引(multiindex)及其在 series 和 dataframe 中的应用。内容涵盖了分层索引的创建方法(如 from_tuples、from_arrays、from_product 等)、索引和切片操作、索引排序、堆叠与反堆叠(stack/unstack)、索引与列之间的转换(reset_index/set_index),以及多重索引在实际数据分析中的优势。通过丰富的代码示例,展示了如何灵活、高效地处理高维数据,并强调了分层索引在数据探索和处理中的重要作用。
到此这篇关于pandas 分层索引的具体实践的文章就介绍到这了,更多相关pandas 分层索引内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论