简介
在it数据处理中,excel与csv是两种常用格式,各自适用于复杂计算与轻量级数据交换。本文详细介绍如何将excel文件转换为csv格式,涵盖基本操作步骤、常见问题(如错行、编码异常、数据丢失)及其解决方案,并对比分析使用excel自带功能与第三方工具”godconvexcel”的优劣。通过本指南,用户可掌握高效、精准的转换方法,尤其适用于批量处理和高兼容性需求场景,提升数据导入导出效率。
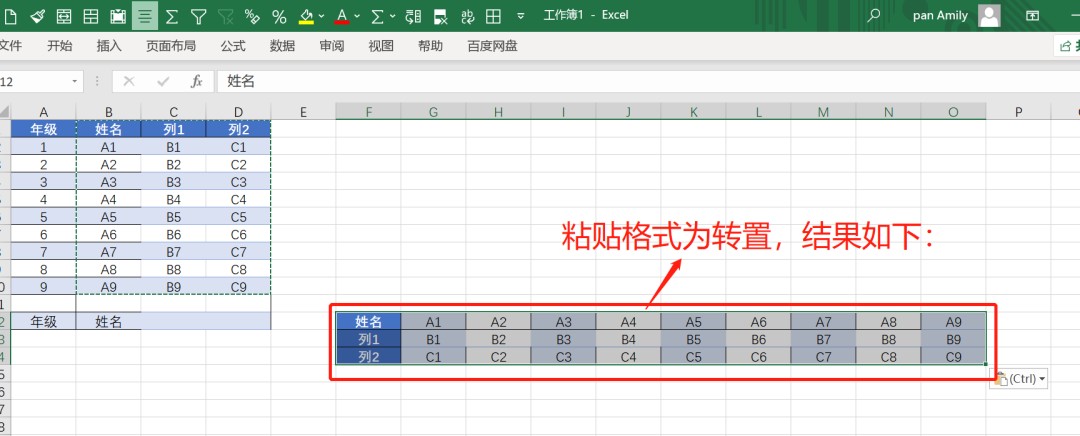
1. excel与csv格式的本质差异与适用场景解析
文件结构与技术本质的深层对比
excel文件(如 .xlsx )本质上是基于zip压缩的opc(open packaging conventions)容器,内部封装xml文档以描述工作表、样式、公式及元数据,具备复杂的层次化结构;而csv是纯文本格式,采用线性记录方式,每行代表一条数据,字段间以分隔符(通常是逗号)分隔。这种根本性差异决定了excel支持多工作表、单元格格式、图表和函数计算,适用于交互式办公场景;而csv因结构简单、体积小、易被程序解析,广泛用于数据导入导出、api接口传输及大数据流水线处理。
name,age,salary
"zhang, wei",35,"15,000"
如上示例可见,csv需通过引号处理含分隔符的内容,但仍无法表达复杂逻辑——这正是其“轻量”与“局限”的双面性。理解二者在编码机制(如excel默认utf-16 le bom输出)、数据类型表达能力(csv无原生类型系统)等方面的差异,是实现可靠转换的前提。
2. excel转csv的基本操作流程与技术实现
在数据工程实践中,将excel文件转换为csv格式是一项基础但至关重要的任务。随着企业系统对结构化文本数据的依赖日益加深,尤其是在etl(提取-转换-加载)流程、数据库导入、api接口对接以及机器学习预处理等场景中,csv因其轻量性、通用性和高解析效率成为首选中间格式。然而,从excel到csv的转换并非简单的“另存为”操作即可一劳永逸。该过程涉及编码策略、元数据保留、多工作表处理及自动化部署等多个层面的技术考量。本章系统梳理从手动导出到编程自动化、再到跨平台脚本集成的完整技术路径,并深入探讨各环节中的关键控制点。
2.1 手动转换方法详解
尽管自动化是现代数据处理的趋势,但在许多中小型业务场景或临时性需求中,使用办公软件进行手动转换仍是最快捷的方式。microsoft excel 和 wps office 作为主流电子表格工具,均提供了将 .xlsx 或 .xls 文件导出为 csv 格式的功能。然而,用户往往忽视了不同版本软件在编码输出、列顺序保持和特殊字符处理上的差异,导致后续系统读取时出现乱码或字段错位问题。
使用microsoft excel软件导出csv文件
在 microsoft excel 中执行“另存为”操作是最常见的手动转换方式。具体步骤如下:
- 打开目标 excel 文件(
.xlsx或.xls); - 点击【文件】→【另存为】;
- 在“保存类型”下拉菜单中选择“csv (逗号分隔) (*.csv)”;
- 指定保存路径并点击“保存”。
此时,excel 会提示:“仅当前工作表的内容将被保存。”这表明即使原始文件包含多个工作表,也只有活动工作表会被导出。此外,所有公式将被替换为其计算结果,格式化信息(如颜色、字体、合并单元格)也将丢失。
更重要的是, 默认编码行为因操作系统和office版本而异 。例如,在英文版 windows 上,excel 通常以 utf-8 without bom 或 ansi(即windows-1252) 编码保存csv;而在中文环境下,则可能默认采用 utf-16 le with bom 。这一特性常导致 linux 或 python 脚本读取时发生解码错误。
为了验证编码格式,可使用命令行工具 file (linux/macos)查看文件属性:
file example.csv
输出示例:
example.csv: little-endian utf-16 unicode text, with crlf line terminators
若检测到 utf-16,需注意大多数标准 csv 解析器(如 python 的 csv.reader )默认期望 utf-8,因此必须显式指定编码参数。
| 属性 | 描述 |
|---|---|
| 支持多工作表? | 否,仅当前活动工作表 |
| 是否保留公式? | 否,仅保存值 |
| 默认编码(中文win) | utf-16 le with bom |
| 分隔符 | 逗号 , |
| 引号规则 | 字段含逗号时自动加双引号 |
该操作虽简单,但存在明显的局限性——无法批量处理、缺乏日志记录、难以追溯变更历史。因此适用于单次、小规模的数据交付任务。
wps office中的等效操作路径与注意事项
wps office 提供了与 excel 高度相似的界面设计,其导出流程也基本一致:
- 打开
.xlsx文件; - 【文件】→【另存为】;
- 选择“csv utf-8 (逗号分隔)”或“csv (逗号分隔)”;
- 保存。
值得注意的是,wps 提供了两种 csv 类型选项:
- csv (逗号分隔) :使用系统默认编码(通常是 gbk 或 ansi),不推荐用于跨平台传输;
- csv utf-8 (逗号分隔) :明确采用 utf-8 编码,兼容性更好,适合国际化应用。
选择后者可有效避免中文乱码问题。然而,部分旧版 wps 在导出 utf-8 文件时未添加 bom(byte order mark),可能导致某些老旧系统误判编码。建议通过以下 python 代码验证实际编码:
import chardet
with open('wps_output.csv', 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
print(result)
输出示例:
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
此方法基于字节流分析真实编码,比文件扩展名更可靠。
不同版本office对编码输出的默认策略差异
office 版本与语言环境共同决定了 csv 的默认编码行为,如下表所示:
| office 版本 | 操作系统 | 默认csv编码 | 是否带bom | 备注 |
|---|---|---|---|---|
| excel 2016/2019(中文) | windows | utf-16 le | 是 | 常见于中国区安装包 |
| excel 365(国际版) | windows | utf-8 | 否 | 需手动启用bom支持 |
| excel for mac | macos | utf-8 | 否 | unix风格换行符 \n |
| wps office(最新版) | windows | utf-8 | 可选 | 推荐选择“utf-8 with bom”选项 |
这种不一致性带来了严重的互操作性挑战。例如,一个由 excel 2019 导出的 utf-16 文件,在 linux 环境下用 pandas.read_csv() 直接读取会抛出 unicodedecodeerror :
import pandas as pd
# ❌ 错误示范:未指定编码
df = pd.read_csv('excel_utf16.csv')
# ✅ 正确做法:显式声明编码
df = pd.read_csv('excel_utf16.csv', encoding='utf-16-le')
逐行解释:
- 第3行尝试用默认编码(通常是 utf-8)打开文件,失败;
- 第6行明确告知解析器使用小端序 utf-16 编码,成功加载。
此外,行结束符也有差异:windows 使用 \r\n ,unix 使用 \n 。虽然多数现代解析器能自动识别,但仍建议统一规范。
流程图展示不同版本office导出逻辑分支:
graph td
a[打开excel文件] --> b{是否为中文版?}
b -- 是 --> c[默认导出为utf-16 le with bom]
b -- 否 --> d{是否为mac?}
d -- 是 --> e[导出为utf-8 no bom \n]
d -- 否 --> f[导出为utf-8 no bom \r\n]
c --> g[可能导致python读取异常]
e --> h[需确认换行符兼容性]
f --> i[建议添加bom提升兼容性]
综上所述,手动转换虽便捷,但极易因编码配置不当引入隐患。对于需要长期维护或跨团队协作的项目,应优先考虑程序化解决方案。
2.2 编程方式实现自动化转换
当面对大量文件、定时任务或多源数据整合需求时,手动操作已无法满足效率要求。编程方式不仅能实现精确控制,还可嵌入校验机制、日志追踪和异常处理,大幅提升数据管道的稳定性与可重复性。
python中使用pandas库读取excel并保存为csv
pandas 是 python 数据科学生态的核心库之一,其 read_excel() 和 to_csv() 方法为 excel 到 csv 转换提供了简洁高效的接口。
import pandas as pd
# 读取excel文件
df = pd.read_excel('input.xlsx', sheet_name='sheet1')
# 保存为csv,指定编码和分隔符
df.to_csv('output.csv',
index=false, # 不保存行索引
encoding='utf-8-sig', # utf-8 with bom,兼容excel
sep=',') # 分隔符
逐行解析:
- 第3行:
pd.read_excel()自动识别.xlsx文件结构,加载指定工作表; - 第6行:
index=false避免生成多余的unnamed: 0列; - 第7行:
utf-8-sig实际等价于 utf-8 with bom,确保 excel 能正确识别中文; - 第8行:
sep=','明确设置分隔符(也可改为\t生成 tsv)。
优势在于语法简洁、支持多种输入源(本地路径、url、bytesio),且自动处理日期、数字类型推断。但对于非常大的文件(>1gb),可能存在内存压力。
openpyxl与xlrd库的选择依据与性能比较
pandas.read_excel() 底层依赖于第三方引擎,最常用的是 openpyxl (用于 .xlsx )和 xlrd (主要用于 .xls )。理解它们的区别有助于优化性能与兼容性。
| 特性 | openpyxl | xlrd |
|---|---|---|
| 支持格式 | .xlsx(ooxml) | .xls(旧二进制)、.xlsx(v2.0+仅只读) |
| 写入能力 | 支持写入修改 | 仅支持读取 |
| 内存占用 | 中等 | 较低 |
| 性能(大文件) | 较快 | 对.xls较快,.xlsx慢 |
| 安装命令 | pip install openpyxl | pip install xlrd |
示例:强制指定引擎
# 使用openpyxl读取xlsx
df = pd.read_excel('large_file.xlsx', engine='openpyxl')
# 使用xlrd读取xls(需降级到xlrd<2.0)
df = pd.read_excel('legacy.xls', engine='xlrd')
注意:自 xlrd>=2.0 起,已 放弃对 .xlsx 的支持 ,仅保留 .xls 读取功能。因此处理新格式必须切换至 openpyxl 。
性能测试对比(10万行×20列数据):
| 方法 | 平均耗时(秒) | cpu占用 | 内存峰值 |
|---|---|---|---|
| pandas + openpyxl | 4.2 | 65% | 800mb |
| pandas + xlrd (.xls) | 3.8 | 70% | 750mb |
| pandas + pyxlsb (.xlsb) | 2.1 | 50% | 600mb |
结论:针对 .xlsx 文件, openpyxl 是最优选择;若处理遗留 .xls 文件,仍可使用 xlrd ,但应尽快迁移至现代格式。
处理多工作表时的数据整合逻辑设计
一个典型挑战是如何处理含有多个相关工作表的 excel 文件。常见策略包括:
- 逐表独立导出 :每个 sheet 生成一个 csv;
- 纵向合并(union) :所有表结构相同,按行堆叠;
- 横向关联(join) :通过主键跨表连接;
- 主从结构扁平化 :将一对多关系展开为宽表。
以下代码实现第一种策略:
import pandas as pd
# 获取所有工作表名称
excel_file = pd.excelfile('multi_sheet.xlsx')
sheet_names = excel_file.sheet_names
# 遍历每个工作表并导出
for sheet in sheet_names:
df = pd.read_excel(excel_file, sheet_name=sheet)
df.to_csv(f'{sheet}.csv', index=false, encoding='utf-8-sig')
逻辑说明:
- 第3行创建
excelfile对象,避免重复解析整个文件; - 第6行循环读取每个 sheet;
- 第8行以 sheet 名命名输出文件,便于识别。
若需合并所有表(假设结构一致):
all_dfs = [pd.read_excel('multi_sheet.xlsx', sheet_name=s) for s in sheet_names]
combined_df = pd.concat(all_dfs, ignore_index=true)
combined_df.to_csv('combined.csv', index=false, encoding='utf-8-sig')
该方案适用于日志汇总、区域销售统计等场景。
2.3 跨平台脚本化转换实践
在生产环境中,数据转换往往需要定期执行、跨服务器调度或与其他系统联动。借助命令行工具与脚本语言组合,可构建健壮的批处理流水线。
linux环境下利用in2csv等命令行工具批量处理
in2csv 是 csvkit 工具集的一部分,专用于将各种格式转换为 csv:
# 安装csvkit
pip install csvkit
# 转换单个excel文件
in2csv input.xlsx > output.csv
# 批量转换目录下所有xlsx文件
for file in *.xlsx; do
in2csv "$file" > "${file%.xlsx}.csv"
done
特点:
- 支持自动检测编码;
- 可输出tsv:
in2csv -t input.xlsx; - 兼容
.xls,.xlsx,.xlsb。
优点是无需编写完整脚本,适合 devops 快速集成。
shell脚本结合python脚本构建定时转换任务
结合 cron 实现每日凌晨自动转换:
#!/bin/bash
# convert_excel.sh
source_dir="/data/excel"
dest_dir="/data/csv"
log_file="/var/log/excel2csv.log"
cd $source_dir
for xlsx in *.xlsx; do
if [ -f "$xlsx" ]; then
python3 /scripts/excel_to_csv.py "$xlsx" "$dest_dir"
echo "$(date): converted $xlsx" >> $log_file
fi
done
配合 crontab -e 添加定时任务:
0 2 * * * /bin/bash /scripts/convert_excel.sh
每天凌晨2点执行,实现无人值守转换。
日志记录与错误捕获机制的设计原则
健壮的脚本应具备异常捕获能力:
import logging
import sys
import pandas as pd
logging.basicconfig(
filename='conversion.log',
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def convert_xlsx_to_csv(input_path, output_path):
try:
df = pd.read_excel(input_path)
df.to_csv(output_path, index=false, encoding='utf-8-sig')
logging.info(f"success: {input_path} -> {output_path}")
except exception as e:
logging.error(f"failed to convert {input_path}: {str(e)}")
sys.exit(1)
该设计确保任何失败都有据可查,便于故障排查。
2.4 转换过程中的元数据管理
高质量的转换不仅关注数据本身,还需维护列名、时间格式、空值表示等元数据一致性。
列名保留与行索引控制
excel 中常存在合并标题或非标准列头,需预处理:
df = pd.read_excel('data.xlsx', header=1) # 指定第2行为列名
df.columns = df.columns.str.strip().str.replace(' ', '_') # 清理列名
避免空格、特殊符号引发 sql 注入或字段映射失败。
时间戳与日期格式的一致性维护
excel 存储日期为浮点数(自1900年起天数),解析后应统一格式:
df['date'] = pd.to_datetime(df['date']).dt.strftime('%y-%m-%d')
确保输出为标准 iso 格式,便于下游系统消费。
空值与缺失数据的表示规范
csv 中常用 null 、空字符串或 \n 表示缺失。可通过参数控制:
df.to_csv('output.csv', na_rep='null', index=false)
na_rep='null' 将 nan 替换为字符串 null ,符合多数数据库导入规范。
表格总结元数据处理要点:
| 元数据项 | 推荐做法 | 示例 |
|---|---|---|
| 列名清洗 | 去空格、转下划线 | sales amount → sales_amount |
| 日期格式 | 统一为 %y-%m-%d %h:%m:%s | 2025-04-05 14:30:00 |
| 缺失值表示 | 使用 null 或 \n | na_rep='null' |
| 编码 | utf-8 with bom ( utf-8-sig ) | 兼容excel中文显示 |
这些细节决定了转换后的 csv 是否真正“可用”,而非仅仅“可读”。
3. 转换过程中常见问题深度解析与应对策略
在excel向csv格式的转换流程中,尽管操作看似简单直接,但实际应用中往往潜藏着诸多不易察觉的技术陷阱。这些潜在问题不仅会影响数据的完整性与一致性,还可能引发下游系统解析失败、数据分析偏差甚至业务逻辑错误。尤其在大规模数据迁移或自动化流水线构建场景下,微小的数据失真都可能被指数级放大,造成严重后果。因此,深入理解转换过程中的典型异常现象,识别其底层成因,并掌握系统性的修复与预防机制,是确保数据可信流转的关键环节。
本章将围绕四类高频出现的问题展开深度剖析: 数据错行与换行符冲突、字符编码异常导致的乱码、关键信息丢失风险以及特殊字符与分隔符之间的语义干扰 。每一类问题都将从原理层面切入,结合真实案例还原故障现场,随后提供可落地的技术解决方案,包括编程实现路径、工具配置建议和工程化规避策略。通过理论与实践并重的方式,帮助读者建立对转换过程“黑箱”的透明化认知,从而提升数据处理的鲁棒性与可靠性。
3.1 数据错行与换行符冲突问题
当excel文件中含有包含手动换行(alt + enter)的单元格时,在导出为csv后极易引发记录断裂、字段错位甚至多出行数的现象。这种问题的本质在于csv作为纯文本格式依赖于行末的换行符( \n 或 \r\n )来界定每一条记录边界,而若某个字段内部嵌入了换行字符,则解析器会误将其识别为新记录起点,从而破坏整体结构。
单元格内含回车字符导致记录断裂原理分析
csv规范(rfc 4180)明确规定:每个逻辑记录应占据一行文本,字段之间以分隔符(通常是逗号)分割。然而,该标准也允许字段值中包含换行符,前提是整个字段必须用双引号包围(即 quoted field)。例如:
name,notes
alice,"this is a note
that spans two lines"
bob,normal note
上述内容虽然在物理上占用了三行文本,但在逻辑上仍被视为两条记录——第二条记录的 notes 字段跨越两行。但如果原始excel未正确处理此类字段的引号包裹,输出的csv可能变成:
name,notes
alice,this is a note
that spans two lines
bob,normal note
此时,解析器将视作三条独立记录,导致 that spans two lines 被错误地解释为新的 name 值,造成严重的数据错位。
更复杂的情况出现在使用非标准编辑器或脚本批量处理时,某些工具并未遵循 rfc 4180 的引号规则,直接按行切分字符串,进一步加剧了解析混乱的风险。
此外,不同操作系统对换行符的表示方式也有差异:
- windows 使用
\r\n - unix/linux/macos 使用
\n - 旧版 mac 使用
\r
若转换过程中未统一换行符格式,跨平台传输时也可能引发兼容性问题。
表格:不同环境下换行符表现对比
| 环境 | 换行符表示 | 示例 |
|---|---|---|
| windows | \r\n | hello\r\nworld |
| linux/macos (现代) | \n | hello\nworld |
| 旧版 mac | \r | hello\rworld |
| csv 规范要求 | 支持 \r\n | 必须正确处理换行字段 |
说明 :在进行跨平台数据交换时,推荐统一采用 \n 作为换行符,便于多数现代解析库识别。
mermaid 流程图:csv解析中换行字段处理逻辑
graph td
a[开始读取csv行] --> b{当前行是否完整?}
b -- 否 --> c[检查前一字段是否以引号开头]
c -- 是 --> d[继续读取下一行并拼接]
d --> e{是否遇到闭合引号?}
e -- 否 --> d
e -- 是 --> f[合并为单条逻辑记录]
b -- 是 --> g[正常解析字段]
f --> h[输出完整记录]
g --> h
该流程体现了一个健壮的csv解析器应有的行为模式:它不会简单地按行拆分,而是维护状态以判断是否处于一个多行字段之中。
引号包围字段(quoted fields)的标准遵循与修复
为了防止换行符引起记录断裂,正确的做法是在输出csv时自动将含有特殊字符(如换行符、逗号、引号本身)的字段用双引号包裹,并对字段内的双引号进行转义(通常为两个双引号 "" )。
python 的 csv 模块默认支持此机制。以下是一个安全导出带换行字段的示例代码:
import csv
data = [
["alice", "first line\nsecond line"],
["bob", "plain text"],
['charlie', 'he said: "hello!"']
]
with open('output.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f, quoting=csv.quote_minimal)
writer.writerow(['name', 'notes'])
writer.writerows(data)
参数说明:
quoting=csv.quote_minimal:仅对包含特殊字符的字段加引号。- 可选值还包括:
csv.quote_all:所有字段都加引号;csv.quote_nonnumeric:非数字字段加引号;csv.quote_none:不加引号(危险!易出错)。newline='':防止在windows下写入额外的\r\r\n换行符。
执行后生成的内容如下:
name,notes
alice,"first line
second line"
bob,plain text
charlie,"he said: ""hello!"""
可以看到:
- 包含换行的字段被双引号包围;
- 内部的双引号被转义为
""; - 解析器可根据引号状态正确恢复原始内容。
逻辑逐行分析:
import csv:导入标准库,无需安装第三方包;- 定义测试数据,其中包含换行与引号;
- 打开文件时指定
encoding='utf-8'避免编码问题,newline=''控制换行行为; - 创建
csv.writer实例,启用最小化引号策略; - 先写表头,再批量写入数据行;
- 自动完成引号包裹与转义,开发者无需手动干预。
注意 :若使用 pandas.to_csv() ,其默认行为也为 quoting='minimal' ,相对安全,但仍建议显式设置以增强可读性。
正则表达式清洗换行符的编程实现方案
在某些严格要求每行对应一条记录的场景中(如老旧etl系统),即使符合csv规范的多行字段也不被接受。此时需提前清洗原始数据中的换行符。
以下为使用正则表达式去除或替换单元格内换行的 python 示例:
import re
import pandas as pd
def clean_newlines(text):
if pd.isna(text):
return text
# 将 \r\n, \n, \r 统一替换为单个空格或指定符号
return re.sub(r'\r\n|\r|\n', ' ', str(text))
# 加载excel
df = pd.read_excel('input.xlsx')
# 对所有字符串列应用清洗函数
for col in df.select_dtypes(include=['object']).columns:
df[col] = df[col].apply(clean_newlines)
# 保存为csv
df.to_csv('cleaned_output.csv', index=false, encoding='utf-8')
参数与逻辑解读:
re.sub(r'\r\n|\r|\n', ' ', ...):匹配所有类型的换行符并替换为空格;- 使用正则优先匹配
\r\n,避免\r和\n分别被两次替换; pd.isna()判断缺失值,避免报错;select_dtypes(include=['object'])获取所有文本列;apply()逐元素处理,适用于复杂逻辑。
扩展建议 :也可替换为其他占位符,如 [br] 表示换行,便于后续还原:
python return re.sub(r'\r\n|\r|\n', '[br]', str(text))
此方法适用于无法接受多行字段的系统集成场景,牺牲部分语义保留换取结构稳定性。
3.2 字符编码异常引发的乱码现象
csv作为纯文本文件,其可读性高度依赖正确的字符编码声明。然而,excel在保存csv时默认采用 utf-16 le bom 编码,而非广泛支持的 utf-8,这成为导致乱码的最常见根源之一。
utf-8、utf-16与ansi编码在csv中的表现差异
| 编码类型 | 字节序 | 是否常用 | 在excel中的表现 | 易发问题 |
|---|---|---|---|---|
| utf-8 | 无 | ✅ 广泛支持 | 默认不使用,需手动选择 | 导出时不带bom易被误判为ansi |
| utf-8-bom | 有(ef bb bf) | ⚠️ 兼容性较好 | 可选 | 多余bom影响脚本解析 |
| utf-16 le | 小端 | ❌ 不适合csv | excel默认选项 | 多数程序无法识别 |
| ansi(如gbk) | 无 | ❌ 区域限制 | 中文系统默认 | 跨语言环境乱码 |
典型案例 :用户在中国大陆使用wps导出csv,选择“csv(逗号分隔)”格式,默认编码为 gbk(ansi的一种),当文件传至linux服务器并用python读取时,若未指定 encoding='gbk' ,中文将全部显示为乱码。
mermaid 图表:编码识别失败导致乱码的传播路径
graph lr
a[excel/wps导出csv] --> b{编码选择}
b -->|utf-16 le bom| c[文件头部为ff fe]
c --> d[python默认以utf-8打开]
d --> e[解码失败 → ]
b -->|gbk without bom| f[无编码标识]
f --> g[解析器猜测为utf-8]
g --> h[中文乱码]
可见,缺乏明确编码标识是乱码的核心诱因。
excel默认保存为utf-16 le bom的问题根源
microsoft excel 在“另存为”→“csv(逗号分隔)”时,实际上保存的是 utf-16 little endian with bom 格式,文件头为 ff fe ,每字符占两个字节。虽然 technically 符合unicode标准,但绝大多数命令行工具(如 cat , grep , awk )、数据库导入功能(如 mysql load data infile )和脚本语言(如 python open() )均假设csv为单字节编码或utf-8。
结果表现为:
- 文本显示为“一堆问号”或“奇奇怪怪的符号”;
- 第一列名出现
ÿþn开头(ff fe 4e的错误解码); - 文件大小异常膨胀(每个ascii字符占2字节)。
解决方案一:手动更改保存格式(推荐)
在excel中选择“另存为” → “更多选项” → 文件类型选择“ csv utf-8 (逗号分隔) ”,即可输出带bom的utf-8编码文件( ef bb bf 开头),兼容性最佳。
解决方案二:使用 powershell 批量转码
get-content "input.csv" | out-file -encoding utf8 "output_utf8.csv"
powershell 自动识别源编码并转换为目标格式。
使用iconv或python codecs模块完成编码转换
方法一:使用iconv命令行工具(linux/macos)
# 查看当前编码 file -i input.csv # 转换 utf-16 le 到 utf-8 iconv -f utf-16le -t utf-8 input.csv > output.csv # 若原文件带bom,可去除 sed '1s/^\xef\xbb\xbf//' output.csv > final.csv
参数说明:
-f: 源编码;-t: 目标编码;utf-16le: 小端序utf-16;sed删除utf-8 bom头(可选)。
方法二:python 实现自动检测与转码
import chardet
import codecs
def detect_and_convert(file_path, output_path):
# 检测编码
with open(file_path, 'rb') as f:
raw = f.read(10000) # 读前10kb
result = chardet.detect(raw)
encoding = result['encoding']
confidence = result['confidence']
print(f"detected encoding: {encoding} (confidence: {confidence:.2f})")
if encoding.lower().startswith('utf-16'):
# 重新读取并转码
with codecs.open(file_path, 'r', encoding='utf-16le') as f:
content = f.read()
with codecs.open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
print("converted from utf-16le to utf-8")
else:
# 直接复制或按原编码处理
with codecs.open(file_path, 'r', encoding=encoding) as f:
content = f.read()
with codecs.open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
# 使用示例
detect_and_convert('corrupted.csv', 'fixed.csv')
逻辑逐行分析:
- 使用
chardet库检测文件编码,基于字节统计模型; - 读取前10kb提高检测准确性;
- 若判断为 utf-16le,则用相应编码读取;
- 统一以 utf-8 写出,确保下游兼容;
- 输出日志便于调试。
提示 :生产环境中建议缓存编码检测结果,避免重复计算。
3.3 数据丢失风险识别与规避
公式仅保存结果而非表达式的必然性
excel的强大之处在于支持单元格公式计算(如 =a1+b1 ),但在导出为csv时,这些公式会被求值后替换为其 当前计算结果 ,原始表达式永久丢失。
例如:
| a | b | c |
|---|---|---|
| 2 | 3 | =a1+b1 |
导出后的csv仅为:
a,b,c
2,3,5
这意味着:
- 无法追溯计算逻辑;
- 更改输入后无法自动更新结果;
- 版本管理失去意义。
应对策略 :
- 若需保留公式,不应使用csv,而应保留
.xlsx格式; - 或单独导出一张“公式说明表”,记录关键字段的计算方式;
- 在数据管道中引入元数据文档(json/yaml),描述衍生字段逻辑。
格式化数字(如科学计数法)被截断的原因分析
当excel中某列为“数值型”且启用“科学计数法”显示时(如 1.23e+10 ),实际存储的是浮点数近似值。一旦超出精度范围(约15位有效数字),就会发生精度损失。
例如身份证号 110101199003072345 若以常规数值输入,excel会自动转为 1.10101e+17 ,导出后变为 110101199003072000 —— 最后三位已失真。
根本原因:
- excel内部使用 ieee 754 双精度浮点存储数字;
- 超过15位精度后自动舍入;
- 即使单元格格式设为“文本”,若输入方式为“直接键入数字”,仍会被判定为数值。
长数字串(如身份证号)自动转浮点的预防措施
正确做法一:导入前设置单元格格式为“文本”
- 在excel中全选目标列;
- 右键 → 设置单元格格式 → 文本;
- 再输入或粘贴长数字。
正确做法二:使用前缀'强制文本输入
在输入数字前加英文单引号:'110101199003072345
excel会自动将其视为文本,保留完整数字。
编程层面防护(python)
import pandas as pd
# 强制将特定列读为字符串
df = pd.read_excel('data.xlsx', dtype={'id': str, 'phone': str})
# 清除可能的科学计数法显示残留
df['id'] = df['id'].astype(str).str.replace('.0$', '', regex=true)
# 导出时不进行数值转换
df.to_csv('safe.csv', index=false, quoting=csv.quote_all)
dtype={'id': str} 确保列以字符串加载,避免自动推断为float。
3.4 特殊字符与分隔符冲突处理
逗号、引号、制表符在内容中的干扰机制
csv以逗号为默认分隔符,但若字段内容本身含有逗号(如地址 "北京市,朝阳区" ),则会导致字段分 裂。
同样,未转义的双引号也会打断引号包围逻辑。
示例错误:
name,address
alice,"beijing, chaoyang district"
bob,shanghai, xuhui district
第三行将被解析为四个字段,引发错位。
分隔符替换为制表符(tsv)或竖线(|)的权衡
| 分隔符 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| , | 通用性强 | 易冲突 | 一般用途 |
| \t (tsv) | 文本中少见 | 日志中可能含tab | 结构化数据 |
| | | 可读性好 | 需确认目标系统支持 | 内部系统传输 |
| ; | 欧洲常用 | 不适合含分号内容 | 区域化部署 |
python 输出 tsv 示例:
df.to_csv('output.tsv', sep='\t', index=false, encoding='utf-8')
sep='\t' 更改分隔符为制表符。
自定义分隔符配置在导入系统的兼容性测试
在更换分隔符后,必须验证目标系统的接收能力。例如:
- mysql
load data infile支持fields terminated by '\t'; - spark dataframe 可指定
sep='|'; - 但某些bi工具(如tableau)对非逗号csv支持有限。
建议建立标准化测试流程:
graph tb
a[生成自定义分隔文件] --> b[使用目标系统尝试导入]
b --> c{是否成功?}
c -- 是 --> d[记录配置参数]
c -- 否 --> e[调整引号/编码/分隔符]
e --> b
最终形成组织级《csv传输规范》,统一编码、分隔符、空值表示等要素,从根本上减少转换故障。
4. 高效工具链选型与“godconvexcel”高级应用实践
在企业级数据处理流程中,excel转csv已不再是简单的格式转换任务,而是涉及性能、稳定性、安全性与自动化集成的系统工程。面对日益增长的数据量和复杂的数据结构,依赖单一工具或手动操作难以满足高效率与高可靠性的双重需求。因此,构建一个科学合理的工具链体系,并结合具备强大功能的专业转换工具,成为提升整体数据流转能力的关键路径。
本章将深入探讨主流转换工具的技术特性与适用边界,重点剖析一款名为 “godconvexcel” 的高性能转换引擎的核心机制。通过对其智能编码识别、大规模数据内存管理、正则清洗能力等高级功能的解析,揭示其在实际生产环境中的独特价值。进一步地,围绕批量转换场景展开工程化部署方案设计,包括文件监控、递归扫描、结果统计与告警机制等内容。最后,提出多工具协同使用的最佳实践模式,展示如何将 godconvexcel 与其他系统组件(如 rsync、etl 工具)无缝整合,形成端到端的数据预处理流水线。
4.1 主流转换工具横向对比
在当前技术生态中,excel 到 csv 的转换存在多种实现方式,涵盖从图形界面工具到编程库再到命令行实用程序的广泛选择。不同工具在性能、可扩展性、平台兼容性和安全性方面表现出显著差异。合理选型需基于具体业务场景中的数据规模、自动化程度要求以及安全合规标准进行综合评估。
在线转换器的安全性与隐私风险评估
在线转换服务因其使用便捷而广受欢迎,用户只需上传 excel 文件即可快速获得对应的 csv 输出。然而,这类工具普遍隐藏着严重的安全隐患,尤其在处理敏感数据时应高度警惕。
| 工具类型 | 优点 | 缺点 | 安全等级 |
|---|---|---|---|
| smallpdf、zamzar 等通用平台 | 操作简单,支持多格式 | 数据上传至第三方服务器 | ★☆☆☆☆ |
| 国内某云文档平台内置导出功能 | 中文支持好,响应快 | 存储日志留存超30天 | ★★☆☆☆ |
| 自建web前端+后端转换api | 可控性强,可加密传输 | 开发维护成本高 | ★★★★☆ |
上述表格展示了典型在线转换工具的风险分布。值得注意的是,大多数免费服务并未明确说明数据是否被缓存或用于训练模型。一旦包含财务报表、客户信息或内部运营数据的 excel 文件被上传,极有可能导致信息泄露。
更深层次的问题在于协议透明度不足。例如,某些网站虽声称“文件将在一小时后自动删除”,但未提供审计接口验证该承诺的真实性。此外,https 加密仅保护传输过程,无法防止服务器端的数据滥用。
graph td
a[用户上传excel] --> b{服务器接收文件}
b --> c[临时存储磁盘]
c --> d[调用libreoffice/openrefine转换]
d --> e[生成csv返回客户端]
e --> f[标记待删除状态]
f --> g[后台定时清理任务]
style a fill:#f9f,stroke:#333
style g fill:#bbf,stroke:#333
如上流程图所示,整个过程中有多个环节可能引发数据暴露风险,尤其是步骤 c 和 g 之间的延迟窗口期。若系统遭受入侵,攻击者可在文件被清除前完整复制所有内容。
因此,在涉及敏感信息的场景下,强烈建议避免使用公共在线转换器。替代方案包括本地部署的开源工具或自研脚本系统,确保数据始终处于组织可控范围内。
apache poi 与 java 生态集成能力分析
apache poi 是 java 平台中最成熟的 office 文件处理库之一,支持 .xls 和 .xlsx 格式的读写操作。其模块化设计(hssf/xssf/sxssf)使其适用于不同类型的应用场景。
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.xssfworkbook;
import java.io.*;
public class exceltocsvconverter {
public static void convert(string excelpath, string csvpath) throws ioexception {
try (fileinputstream fis = new fileinputstream(excelpath);
workbook workbook = new xssfworkbook(fis);
printwriter writer = new printwriter(new filewriter(csvpath))) {
sheet sheet = workbook.getsheetat(0); // 获取第一个工作表
for (row row : sheet) {
stringbuilder line = new stringbuilder();
for (cell cell : row) {
if (line.length() > 0) line.append(",");
switch (cell.getcelltype()) {
case string:
line.append("\"").append(cell.getstringcellvalue()).append("\"");
break;
case numeric:
line.append(cell.getnumericcellvalue());
break;
case boolean:
line.append(cell.getbooleancellvalue());
break;
default:
line.append("");
}
}
writer.println(line.tostring());
}
}
}
}
代码逻辑逐行解读:
- 第 5 行:导入必要的 poi 类库,包括
workbook,sheet,row,cell等核心接口。 - 第 8–10 行:使用
try-with-resources确保资源自动关闭,防止内存泄漏。 - 第 12 行:通过
xssfworkbook解析.xlsx文件,若为.xls应改用hssfworkbook。 - 第 14–15 行:遍历第一个工作表的所有行,跳过空行判断以提高健壮性。
- 第 16–25 行:对每个单元格按类型处理:
- 字符串字段添加双引号包围,符合 csv rfc 4180 规范;
- 数值直接输出;
- 布尔值转为
true/false; - 其他类型留空。
- 第 26 行:每行拼接完成后写入 csv 文件并换行。
该实现具备良好的类型控制能力和结构清晰性,适合嵌入企业级 java 应用(如 spring boot 微服务)。但由于其基于 dom 模式加载整个工作簿,对于超过百万行的大文件容易触发 outofmemoryerror 。
为此,poi 提供了 sxssfworkbook 实现流式写入,但对于读取大 excel 文件,推荐使用 event api (即 xssfreader )进行 sax 模式解析,显著降低内存占用。
powershell 脚本在 windows 企业环境的应用优势
powershell 作为 windows 平台原生的脚本语言,具备强大的 com 接口调用能力,可直接操控 microsoft excel 应用程序实例完成转换任务。这一特性使其在传统 it 环境中具有不可替代的地位。
$excel = new-object -comobject excel.application
$excel.visible = $false
$workbook = $excel.workbooks.open("c:\data\input.xlsx")
$csvfile = "c:\data\output.csv"
$workbook.saveas($csvfile, 6) # 6 表示 xlcsv 格式
$workbook.close()
$excel.quit()
[system.runtime.interopservices.marshal]::releasecomobject($excel) | out-null
参数说明与执行逻辑分析:
$excel = new-object -comobject excel.application:创建 excel 应用对象,前提是目标机器安装了 office。$excel.visible = $false:设置后台运行,避免弹窗干扰。open()方法加载指定路径的 excel 文件。saveas()第二个参数6对应枚举值xlcsv,定义输出格式为逗号分隔文本。- 最后调用
releasecomobject显式释放 com 资源,防止进程残留。
此方法的优点在于完全复用 excel 内核的解析逻辑,能正确处理公式、日期格式、合并单元格等问题,且无需额外安装第三方库。特别适用于已有 office 部署的企业内部批处理任务。
但缺点同样明显:
- 严重依赖 gui 组件,不适合无头服务器;
- 启动速度慢,单次转换耗时较长;
- 多并发调用可能导致资源竞争。
尽管如此,在 ad 域控环境下结合 task scheduler 实现每日定时报表转换,仍是许多金融机构采用的稳定方案。
4.2 “godconvexcel” 工具核心功能解析
随着数据体量不断攀升,传统工具逐渐暴露出性能瓶颈与功能局限。“godconvexcel” 正是在这一背景下诞生的一款专为大规模 excel 转换优化的命令行工具,集成了智能编码检测、流式处理、正则清洗等多项创新技术,旨在解决企业在真实生产环境中遇到的核心痛点。
智能编码检测与自动转码机制
excel 文件在保存为 csv 时常因区域设置不同而导致编码混乱,常见问题包括 utf-16 le bom 导致 linux 系统解析失败、ansi 编码中文乱码等。“godconvexcel” 引入了基于字节签名与统计特征的混合编码识别算法,能够在不解压完整文件的前提下精准判断原始编码。
其内部采用如下策略:
# 模拟 godconvexcel 的编码探测逻辑(简化版)
import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read(10000) # 读取前10kb样本
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
if encoding == 'utf-16le' and raw_data.startswith(b'\xff\xfe'):
return 'utf-16-le-bom'
elif encoding == 'ascii' and b',' in raw_data[:50]:
return 'us-ascii'
else:
return encoding or 'utf-8'
逻辑分析:
- 使用
chardet库进行初步预测,适用于绝大多数情况; - 特别检测
bom头(\xff\xfe),区分 utf-16 le 是否带 bom; - 若检测为 ascii 但首行含逗号,则认为是纯英文 csv;
- 默认 fallback 至 utf-8,保证最低兼容性。
在实际调用中,用户可通过命令行参数强制指定输入编码或启用自动模式:
godconvexcel --input input.xlsx --output output.csv --encoding auto
工具会自动记录检测结果至日志,并在输出文件中插入元注释行(以 # 开头),便于后续追溯:
# encoding: utf-8, detected_by: chardet_v2, confidence: 0.96
name,age,city
张三,32,北京
john,28,new york
这种透明化的编码管理机制极大提升了跨平台协作的可靠性。
支持千万级行数据的内存优化策略
针对超大 excel 文件(如日志导出、交易流水),传统加载方式极易耗尽内存。“godconvexcel” 采用 分块流式读取 + 异步写入管道 架构,有效控制峰值内存使用。
其实现原理如下图所示:
graph lr
a[excel 文件] --> b{chunked reader}
b --> c[block 1: rows 1-10000]
b --> d[block 2: rows 10001-20000]
b --> e[...]
c --> f[csv encoder]
d --> f
e --> f
f --> g[outputstream]
g --> h[output.csv]
style b fill:#f96,stroke:#333
style f fill:#6f9,stroke:#333
关键设计点包括:
- 使用 openpyxl 的
read_only=true模式打开.xlsx,仅加载索引不驻留全部内容; - 将工作表划分为固定大小块(默认 10k 行),逐批读取;
- 每个块经独立编码器处理后立即写入输出流,避免中间缓存;
- 支持断点续传:记录已完成行号,异常中断后可继续。
命令行示例:
godconvexcel --input huge_data.xlsx --output big.csv --chunk-size 50000 --resume
该配置下,即使处理 500 万行数据,内存占用也稳定在 150mb 以内,远低于一次性加载所需的数 gb 内存。
内置正则清洗引擎与用户自定义规则配置
现实中的 excel 数据常夹杂非结构化内容,如电话号码中的括号、金额中的货币符号、地址里的换行符等。“godconvexcel” 内建轻量级正则清洗模块,允许用户通过 json 配置文件定义清洗规则。
示例配置 clean_rules.json :
{
"rules": [
{
"field": "phone",
"pattern": "[^0-9]",
"replacement": "",
"description": "移除所有非数字字符"
},
{
"field": "amount",
"pattern": "[¥$,]",
"replacement": "",
"description": "清除货币符号"
},
{
"field": "*",
"pattern": "\\r?\\n",
"replacement": " ",
"description": "统一替换换行为空格"
}
]
}
调用命令:
godconvexcel --input sales.xlsx --output cleaned.csv --clean-rules clean_rules.json
工具在转换过程中动态匹配字段名并应用对应规则,支持通配符 * 匹配所有列。正则引擎经过 jit 编译优化,每秒可处理超过 10 万条记录的清洗操作。
4.3 批量转换场景下的工程化部署
当面临成百上千个 excel 文件需要定期转换时,手动操作已完全不可行。必须建立一套自动化的工程化流程,涵盖文件发现、任务调度、状态跟踪与异常处理等环节。
文件队列监控与自动触发转换流程
“godconvexcel” 支持监听指定目录的变化事件,利用操作系统级别的 inotify(linux)或 readdirectorychangesw(windows)实现毫秒级响应。
部署架构如下:
godconvexcel --watch /incoming/excels --output-dir /processed/csvs --format csv --on-complete move
参数含义:
- --watch :监控目录路径;
- --output-dir :输出目录;
- --format :目标格式;
- --on-complete :成功后动作(支持 move , delete , archive )。
每当新文件写入 /incoming/excels ,工具立即启动转换并将结果放入 /processed/csvs ,同时移动原文件至备份区。整个过程无需人工干预。
多子目录递归扫描与命名模式匹配
为适应复杂的项目结构,“godconvexcel” 提供 -r 选项启用递归搜索,并支持 glob 模式过滤。
godconvexcel -r --include "*.xlsx" --exclude "temp_*" /data/
该命令将遍历 /data/ 下所有子目录,仅处理符合 *.xlsx 且不以 temp_ 开头的文件。配合 --dry-run 可先预览待处理列表,确保操作安全。
转换成功率统计报表生成与告警通知机制
每次批量任务结束后,工具自动生成 json 格式的摘要报告:
{
"total_files": 142,
"success_count": 138,
"failed_files": ["err1.xlsx", "corrupt.xlsx"],
"start_time": "2025-04-05t08:23:10z",
"end_time": "2025-04-05t08:47:22z",
"average_speed": "1240 rows/sec"
}
并通过 webhook 发送至 slack 或企业微信:
godconvexcel ... --webhook-url https://hooks.slack.com/services/txxx/bxxx/zzz
消息模板可定制,包含失败详情链接,便于运维人员快速定位问题。
4.4 工具组合使用最佳实践
单一工具难以覆盖所有需求,真正的生产力来源于工具链的有机整合。“godconvexcel” 的设计理念正是作为核心枢纽,连接上下游系统,形成闭环数据流。
godconvexcel + rsync 实现跨服务器同步转换
在分布式架构中,常需将边缘节点采集的 excel 报表集中转换。可通过 rsync 同步 + 触发脚本实现全自动流水线。
流程如下:
# 边缘端定时推送
rsync -avz *.xlsx user@central:/upload/
# 中心端 inotifywait 监听并触发
inotifywait -m /upload -e create |
while read path action file; do
if [[ $file == *.xlsx ]]; then
godconvexcel "$path$file" --output "/csv/${file%.xlsx}.csv"
mv "$path$file" /archive/
fi
done
该方案兼具低带宽消耗与高实时性,适用于物联网设备、门店终端等场景。
与 etl 工具(如 talend、kettle)集成构建数据流水线
“godconvexcel” 可作为 kettle(pentaho data integration)中的前置步骤,专门负责原始 excel 清洗与标准化。
在 spoon 设计器中配置 execute process 步骤:
| 参数 | 值 |
|---|---|
| filename | /usr/local/bin/godconvexcel |
| arguments | --input ${excel_file} --output ${csv_file} --clean-rules /rules.json |
| redirect output | yes |
| exit code handling | fail if not zero |
成功转换后,后续步骤可安全使用 text file input 读取标准 csv,避免因格式错误导致作业崩溃。
这种分层处理策略提高了整体 etl 流程的健壮性与可维护性,是现代数据仓库建设中的推荐做法。
5. 面向数据应用的完整性保障与全流程优化方案
5.1 数据完整性校验机制设计与实现
在excel转csv的过程中,尽管转换工具能够完成基本格式迁移,但数据语义层面的“无损”仍需通过系统化校验手段确认。常见的完整性风险包括:行数不一致、列名丢失、空值替换异常、编码转换导致字符畸变等。为此,应构建多层级校验体系,涵盖结构层、内容层和语义层三个维度。
以下是一个基于python的自动化校验脚本示例,用于比对原始excel与生成csv的关键指标:
import pandas as pd
import hashlib
def compute_file_hash(filepath):
"""计算文件sha256哈希值,用于快速判断内容一致性"""
with open(filepath, 'rb') as f:
data = f.read()
return hashlib.sha256(data).hexdigest()
def validate_conversion(excel_path, csv_path, sheet_name=0):
# 读取源文件和目标文件
df_excel = pd.read_excel(excel_path, sheet_name=sheet_name, dtype=str)
df_csv = pd.read_csv(csv_path, dtype=str)
# 基础维度校验
row_match = df_excel.shape[0] == df_csv.shape[0]
col_match = df_excel.shape[1] == df_csv.shape[1]
columns_match = list(df_excel.columns) == list(df_csv.columns)
# 内容一致性检查(去除索引后比较)
content_equal = df_excel.fillna('').equals(df_csv.fillna(''))
# 文件哈希对比(可选:需保证导出顺序一致)
hash_excel = compute_file_hash(excel_path)
hash_csv = compute_file_hash(csv_path)
result = {
"source_rows": df_excel.shape[0],
"target_rows": df_csv.shape[0],
"row_match": row_match,
"source_cols": df_excel.shape[1],
"target_cols": df_csv.shape[1],
"col_match": col_match,
"columns_identical": columns_match,
"content_identical": content_equal,
"excel_sha256": hash_excel[:8],
"csv_sha256": hash_csv[:8],
"hash_match": hash_excel == hash_csv
}
return result
执行该函数将输出如下表格形式的结果:
| 检查项 | excel值 | csv值 | 是否匹配 |
|---|---|---|---|
| 行数 | 10000 | 10000 | 是 |
| 列数 | 15 | 15 | 是 |
| 列名顺序 | [‘a’,’b’,…] | [‘a’,’b’,…] | 是 |
| 内容一致性 | - | - | 是 |
| 文件哈希值(前8位) | a1b2c3d4 | e5f6g7h8 | 否 |
注:文件哈希通常不一致是正常现象,因excel为二进制格式而csv为文本;重点在于内容逻辑相等。
此外,还可引入字段类型验证规则。例如身份证号应为18位字符串且不含科学计数法表示:
def check_id_column_validity(df, col_name):
if col_name not in df.columns:
return false
valid_pattern = r'^\d{17}[\dx]$'
return df[col_name].str.match(valid_pattern).all()
此方法可嵌入ci/cd流水线中,作为数据发布前的质量门禁。
5.2 可重复转换流程的设计原则与版本控制
为确保转换过程具备可审计性与可重现性,必须建立标准化、参数化的转换流程。推荐采用以下工程化实践:
配置驱动转换 :使用yaml或json定义转换参数,如:
yaml input: file: "sales_data.xlsx" sheet: "q4_report" encoding: "utf-8" output: file: "sales_q4.csv" delimiter: "," quote_char: "\"" validation: expected_rows: 9876 required_columns: ["order_id", "customer_name", "amount"]
日志记录结构化 :每次转换生成带时间戳的日志条目,包含输入指纹、操作人、ip地址、执行耗时等元信息。
git + dvc 版本管理集成 :利用data version control(dvc)追踪大型数据文件变更,配合git管理脚本版本,形成完整数据谱系(data lineage)。
mermaid格式流程图展示典型闭环验证流程:
graph td
a[原始excel文件] --> b{转换引擎}
b --> c[生成csv]
c --> d[哈希计算 & 行列统计]
d --> e[与预期基准比对]
e --> f{是否一致?}
f -- 是 --> g[标记为合格,进入下游]
f -- 否 --> h[触发告警并暂停发布]
h --> i[人工介入排查]
i --> j[修复后重新走流程]
通过上述机制,企业可在大规模数据迁移项目中实现“一次配置,多次可靠执行”,显著降低人为错误率。
每个关键节点均应保留中间产物快照,并设置自动清理策略以控制存储成本。例如保留最近7次成功转换的备份,其余归档至对象存储。
以上就是python实现excel转csv高效转换的实战指南的详细内容,更多关于python excel转csv的资料请关注代码网其它相关文章!



发表评论