前言
在大模型(如 openai gpt、claude、glm、文心一言、通义千问等)广泛应用的时代,开发者在调用 api 时,往往需要安全、灵活地管理访问密钥(api key)、接口地址(endpoint)和模型参数。
不同的配置方式适用于不同的开发阶段和部署场景,从本地调试到企业级生产环境都有相应的最佳实践。本文将系统介绍调用大模型 api 的多种方式,包括硬编码、配置文件、环境变量、命令行参数、secrets 管理服务等,并对比它们的优缺点与适用场景。
1. 常见调用方式概览
在调用大模型 api 时,开发者需要告诉程序两个关键信息:
- 身份认证信息(如
api_key) - 接口信息(如
base_url或模型名称)
这些信息可以通过多种方式传入。下面的表格总结了常见方法的特点。
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 1. 硬编码(hardcode) | 实现简单,快速调试 | 极度不安全,不易维护 | 临时脚本、demo |
| 2. 配置文件(config file) | 清晰分离配置与代码 | 文件需妥善保护 | 本地或团队项目 |
| 3. 环境变量(environment variable) | 安全、不暴露在源码中 | 管理繁琐 | 部署、ci/cd、容器 |
| 4. 命令行参数(cli args) | 灵活可覆盖默认值 | 容易出现在命令历史 | 临时测试、调试 |
| 5. 云端密钥管理(secrets manager) | 安全、集中管理、可轮换 | 需额外部署 | 企业级生产环境 |
2. 各种方式的详细说明
2.1 硬编码(hardcode)
最直接的方式是将密钥直接写入代码中:
import openai
openai.api_key = "sk-xxxxxx"
response = openai.chatcompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "你好"}]
)
优点:
- 快速测试方便
缺点: - 密钥暴露在代码中,安全性极差
- 一旦上传到 github 或共享仓库,后果严重
建议: 仅限个人实验或短期 demo,切勿在生产环境中使用。
2.2 配置文件(config file)
将配置集中放在文件中是常见做法,可使用 yaml、json 或 .ini 格式。
示例 config.yaml:
api: provider: openai api_key: "sk-xxxxxx" base_url: "https://api.openai.com/v1"
加载示例:
import yaml, openai
with open("config.yaml") as f:
config = yaml.safe_load(f)
openai.api_key = config["api"]["api_key"]
openai.base_url = config["api"]["base_url"]
优点:
- 可维护性强,结构清晰
- 支持多环境配置(dev/test/prod)
缺点:
- 仍需防止文件泄露,建议
.gitignore排除配置文件。
2.3 环境变量(environment variable)
环境变量是生产环境最常见的安全配置方式。
设置环境变量:
export openai_api_key="sk-xxxxxx"
python 调用:
import os, openai
openai.api_key = os.getenv("openai_api_key")
优点:
- 不出现在源码中,安全性高
- 与容器化(docker、k8s)和 ci/cd 兼容性好
缺点:
- 配置分散,管理复杂,难以追踪变更。
2.4 命令行参数(cli 参数)
可通过命令行传入 key,适用于临时测试或脚本工具。
命令行运行:
python app.py --api-key sk-xxxxxx
python 接收参数:
import argparse
parser = argparse.argumentparser()
parser.add_argument("--api-key", required=true)
args = parser.parse_args()
openai.api_key = args.api_key
优点:
- 灵活性高,可在不同密钥间快速切换
缺点: - 命令记录中可能泄露敏感信息,不适合长期使用。
2.5 云端密钥管理系统(secrets manager)
在企业生产环境中,推荐使用云端密钥管理服务。
常见方案包括:
- aws secrets manager
- azure key vault
- google secret manager
- hashicorp vault
- kubernetes secrets
aws 示例:
import boto3, json, openai
client = boto3.client('secretsmanager')
secret = client.get_secret_value(secretid='openai/api_key')
openai.api_key = json.loads(secret['secretstring'])['api_key']
优点:
- 高安全性(加密、访问控制、自动轮换)
- 支持审计与自动化管理
缺点:
- 部署复杂,需要额外服务依赖。
3. 进阶配置方式
除了上面几种传统方案,还有一些更灵活的高级配置手段:
- .env 文件(dotenv):使用
python-dotenv将.env文件自动加载为环境变量。 - 统一配置中心(nacos、consul、etcd):适用于分布式系统集中管理。
- ci/cd 注入变量:在 github actions、gitlab ci 中安全注入运行时 secret。
- 加密配置文件:配置文件使用 gpg 或 kms 加密,仅运行时解密。
- 后端代理模式(web app):前端不直接暴露 key,而由后端代理转发调用。
4. 综合建议与最佳实践
| 场景 | 推荐方式 |
|---|---|
| 本地测试 | .env 文件 + 环境变量 |
| 小型项目 | 配置文件 + .gitignore |
| 容器部署 | 环境变量 或 docker secrets |
| 企业生产 | 云端 secrets manager |
| 团队协作 | 配置中心(如 nacos、consul) |
| web 应用 | 后端代理转发调用大模型 api |
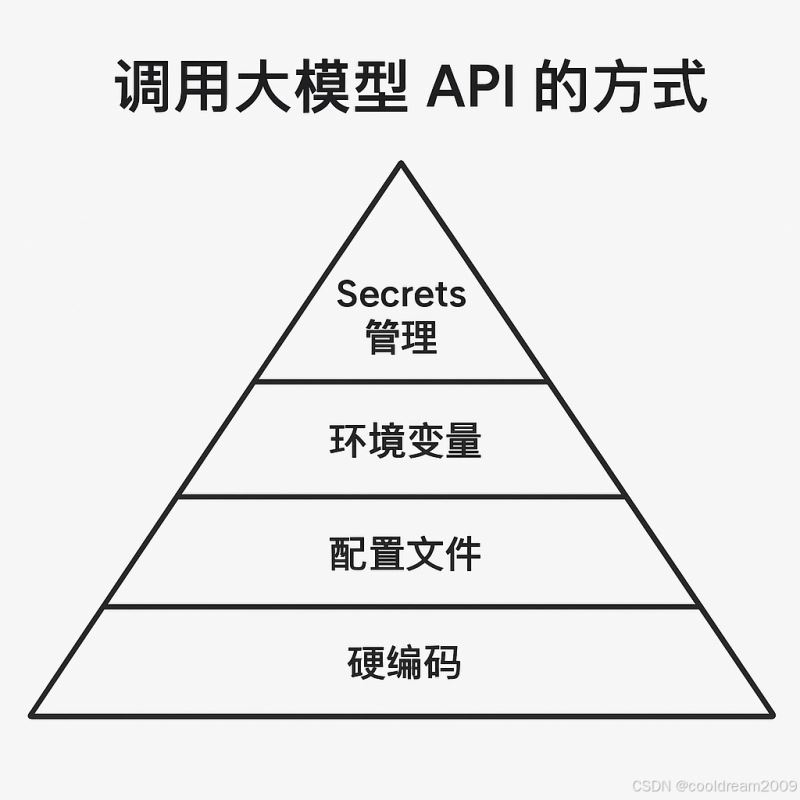
5. 调用方式的分层架构思维
调用大模型 api 的方式可分为四个抽象层次,从低安全性到高安全性逐步演进:
┌─────────────────────────────────────────┐ │ 服务层(secrets manager、配置中心) │ ← 安全、自动化、企业级管理 ├─────────────────────────────────────────┤ │ 系统层(环境变量、cli 参数) │ ← 部署与运维层配置 ├─────────────────────────────────────────┤ │ 文件层(config.yaml、.env) │ ← 本地配置、可版本化管理 ├─────────────────────────────────────────┤ │ 代码层(硬编码) │ ← 临时测试、快速验证 └─────────────────────────────────────────┘
这种分层结构有助于理解:配置越靠上层,越安全、越灵活、越可维护。
结语
调用大模型 api 看似简单,但背后涉及的安全性、可维护性与环境隔离问题不可忽视。 从最初的硬编码,到使用配置文件、环境变量,再到云端密钥管理与配置中心,开发者需要根据项目规模、团队协作方式和部署环境选择合适方案。 在现代 ai 应用的开发中,安全与灵活并重是关键:**让模型更聪明的同时,也让系统更安全、更专业。
以上就是python调用大模型api的多种方式与最佳实践的详细内容,更多关于python调用大模型api的资料请关注代码网其它相关文章!




发表评论