在现代软件开发中,json (javascript object notation) 已成为数据交换的通用语言。无论是与 web api 通信、存储应用程序配置,还是在不同服务间传递信息,json 的身影无处不在。python 凭借其强大的标准库,内置了功能完备的 json 模块来应对这一切。
然而,对于许多初学者来说,load、loads、dump、dumps 这四个核心函数似乎总是有点令人困惑。它们的名字如此相似,功能又各有侧重。本文将彻底厘清它们的区别,从基础用法到高级技巧,在处理 json 数据时游刃有余。
一、核心法则:解密神秘的s后缀
要掌握这四个函数,我们首先要理解一个最关键的区别:函数名末尾的 s。
这里的 s 代表 string (字符串)。
- 带 s 的函数 (loads, dumps): 它们操作的对象是内存中的 python 字符串。
- 不带 s 的函数 (load, dump): 它们操作的对象是 文件(或类文件)对象,负责数据的读写。
记住这个“黄金法则”,就已经掌握了它们一半的奥秘。接下来,围绕两大核心操作——序列化和反序列化来展开。
1、序列化:将 python 对象转换为 json
序列化(也称编码)是将 python 对象(如字典或列表)转换为 json 格式的过程。
1.1 json.dumps(): 转换成 json字符串
当需要将一个 python 对象变成一个 json 格式的字符串,以便通过网络发送或在程序中进一步处理时,dumps() 是不二之选。
import json
# 一个 python 字典
data = {
"name": "张三",
"age": 30,
"courses": ["数学", "英语"]
}
# 转换为 json 字符串
# ensure_ascii=false 确保中文字符正常显示
# indent=4 让输出格式更美观
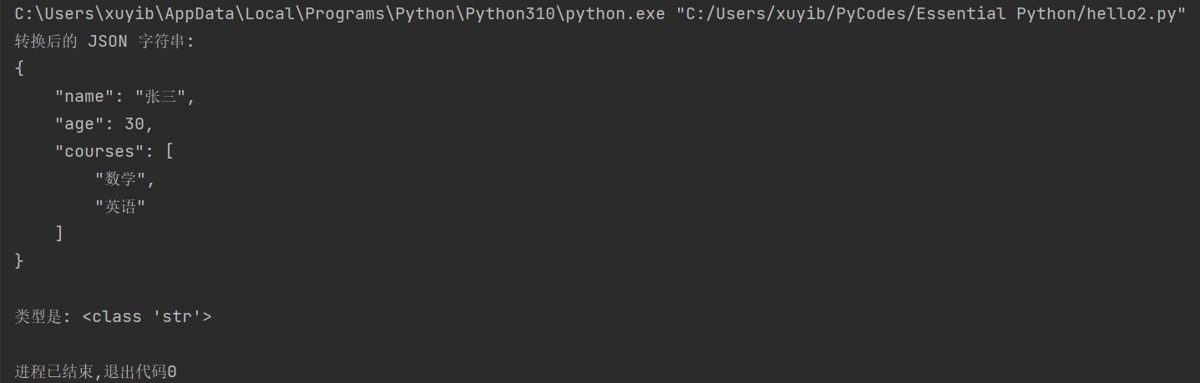
json_string = json.dumps(data, ensure_ascii=false, indent=4)
print("转换后的 json 字符串:")
print(json_string)
print("\n类型是:", type(json_string))运行结果:
1.2 json.dump(): 写入到 json文件
当需要将数据持久化存储,例如保存配置文件或程序状态时,dump() 可以直接将 python 对象写入文件中。
import json
data = {
"name": "李四",
"age": 25,
"courses": ["数学", "英语"]
}
# 'w' 表示写入模式,encoding='utf-8' 支持中文
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=false, indent=4)
print("数据已成功写入 data.json 文件。")1.3ensure_ascii 详解
ensure_ascii 是 json.dump() 和 json.dumps() 函数中的一个布尔类型参数,它控制着输出结果中如何处理非 ascii 字符(例如中文、日文、特殊符号等)。
当调用 json.dumps() 或 json.dump() 而不指定 ensure_ascii 参数时,它默认为 true。在这种模式下,所有非 ascii 字符都会被“转义”成 \uxxxx 的形式。\uxxxx 是一种 unicode 转义序列。这种做法的初衷是为了保证最大的兼容性。因为 ascii 编码是计算机世界里最基础、最通用的字符集,任何系统都可以无误地处理纯 ascii 文本。通过将所有特殊字符转换为 ascii 范围内的 \u 序列,可以确保生成的 json 字符串在任何环境下(即使是那些不支持 utf-8 的老旧系统)都能被安全地传输和存储,不会产生编码错误或乱码。
推荐:当明确地将 ensure_ascii 设置为 false 时,是在告诉 json 模块:“请不要转义这些非 ascii 字符,直接将它们原样输出。”
注意:当使用 ensure_ascii=false 并且要将结果写入文件 (json.dump()) 时,有一个非常重要的配套操作:必须在 open() 函数中指定编码,通常是 encoding='utf-8'。ensure_ascii=false 产生了包含原生非 ascii 字符的输出。如果不指定编码,python 可能会使用操作系统的默认编码(在某些 windows 系统上可能是 gbk 或 cp936)来尝试写入文件。此时如果字符(比如某些特殊符号或生僻字)不在该默认编码范围内,程序就会抛出 unicodeencodeerror 错误。
在今天,utf-8 已经成为事实上的标准。因此,在 python 项目中,强烈推荐始终使用 ensure_ascii=false 并配合 encoding='utf-8' 来处理 json 数据。这会让数据文件更易于管理、调试,也更节省空间。
2、反序列化:将 json 解析为 python 对象
2.1 json.loads(): 从 json字符串中加载
从 api 响应或消息队列中收到一个 json 格式的字符串时,loads() 会将其解析为 python 的字典或列表。
import json
json_string = '''
{
"name": "王五",
"isalive": true,
"hobbies": ["篮球", "游戏"]
}
'''
# 从字符串加载
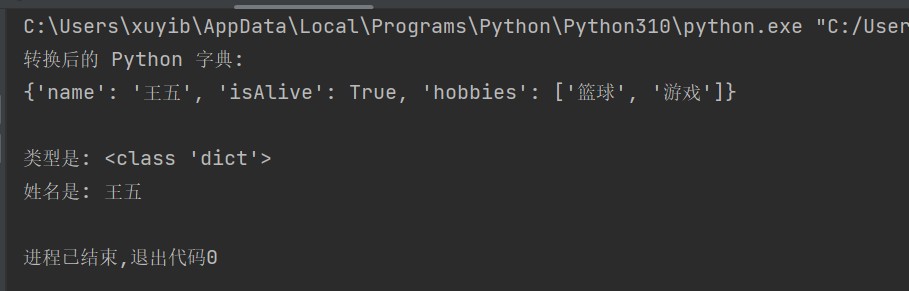
python_dict = json.loads(json_string)
print("转换后的 python 字典:")
print(python_dict)
print("\n类型是:", type(python_dict))
print("姓名是:", python_dict["name"])运行结果:
2.2 json.load(): 从 json文件中读取
当需要从一个配置文件(如 user_data.json)中读取数据并加载到程序中时,load() 是最直接的方法。
import json
# 'r' 表示读取模式,encoding='utf-8' 支持中文
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print("从文件读取的数据:")
print(data)
print("\n类型是:", type(data))
print("课程是:", data["courses"])3、表格对比
| 函数 | 操作 | 输入 | 输出 | 主要用途 |
| json.dumps() | 序列化 | python 对象 | json 格式的字符串 | 网络传输、内存处理 |
| json.dump() | 序列化 | python 对象 + 文件对象 | none (写入文件) | 数据持久化、保存配置 |
| json.loads() | 反序列化 | json 格式的字符串 | python 对象 | 解析 api 响应、文本数据 |
| json.load() | 反序列化 | 文件对象 | python 对象 | 从文件加载配置或数据 |
二、超越基础:json模块的进阶工具
上述四个函数能满足 99% 的需求,同时在某些特殊场景下,json 模块还提供了更强大的工具:
1、处理自定义对象 (jsonencoder)
当试图序列化一个 python 自定义对象(比如一个类的实例)时,json.dumps() 默认是不知道如何处理的,会抛出 typeerror。为了解决这个问题,json 模块提供了 jsonencoder 和 jsondecoder 类。
json.jsonencoder: 你可以通过继承这个类并重写 default() 方法,来告诉 dumps 如何处理你自定义的数据类型。场景示例:你想将一个包含 datetime 对象的字典序列化,但 json 标准里没有日期时间类型。
import json
from datetime import datetime
# 默认情况下,这会报错
# data = {'name': 'test', 'time': datetime.now()}
# json.dumps(data) # typeerror: object of type datetime is not json serializable
# 使用自定义 encoder
class datetimeencoder(json.jsonencoder):
def default(self, obj):
if isinstance(obj, datetime):
# 将 datetime 对象格式化为字符串
return obj.isoformat()
# 其他类型调用父类的默认处理方法
return super().default(obj)
data = {'name': 'test', 'time': datetime.now()}
json_string = json.dumps(data, cls=datetimeencoder, indent=4)
print(json_string)
# 输出:
# {
# "name": "test",
# "time": "2025-10-06t22:01:28.123456"
# }json.jsondecoder: 与上面对应,可以通过继承这个类,使用 object_hook 参数来定义如何将特定的 json 数据结构转换回自定义的 python 对象。
import json
from datetime import datetime
def datetime_decoder_hook(json_dict):
"""
一个用于 json.loads 的 object_hook 函数。
它会检查字典中的值,尝试将符合 iso 8601 格式的字符串转换回 datetime 对象。
"""
for key, value in json_dict.items():
# 检查值是否为字符串,并尝试进行转换
if isinstance(value, str):
try:
# 尝试用 fromisoformat 解析
# python 3.7+ 支持解析带 z 和微秒的完整 iso 格式
json_dict[key] = datetime.fromisoformat(value)
except (valueerror, typeerror):
# 如果转换失败(说明它不是我们想要的日期格式),则保持原样
pass
return json_dict
# 1. 准备一个包含 iso 日期格式字符串的 json
json_string = """
{
"name": "test_event",
"user_id": 123,
"created_at": "2025-10-06t22:01:28.123456",
"metadata": {
"source": "api",
"processed_at": "2025-10-07t10:55:00.543210"
}
}
"""
# 2. 使用 object_hook 进行解码
data_with_datetime = json.loads(json_string, object_hook=datetime_decoder_hook)
# 3. 验证结果
print("解码后的 python 对象:")
print(data_with_datetime)
print("\n--- 类型验证 ---")
print(f"'created_at' 的类型是: {type(data_with_datetime['created_at'])}")
print(f"'processed_at' 的类型是: {type(data_with_datetime['metadata']['processed_at'])}")
print(f"'name' 的类型是: {type(data_with_datetime['name'])}")运行结果:

直接使用 object_hook 参数通常是最简单直接的方式。但如果想创建一个可重用的、配置更复杂的解码器,或者在某个类中封装解码逻辑,也可以选择继承 json.jsondecoder。
import json
from datetime import datetime
class customdatetimedecoder(json.jsondecoder):
def __init__(self, *args, **kwargs):
# 将我们的钩子函数绑定到解码器实例上
json.jsondecoder.__init__(self, object_hook=self.datetime_hook, *args, **kwargs)
def datetime_hook(self, json_dict):
for key, value in json_dict.items():
if isinstance(value, str):
try:
json_dict[key] = datetime.fromisoformat(value)
except (valueerror, typeerror):
pass
return json_dict
# 使用自定义的解码器类
json_string = '{"name": "test", "time": "2025-10-06t22:01:28.123456"}'
# 通过 cls 参数传入自定义的解码器类
data = json.loads(json_string, cls=customdatetimedecoder)
print(data)
print(f"time 字段的类型是: {type(data['time'])}")2、健壮的错误处理 (jsondecodeerror):
当解析格式错误的 json 时,程序会抛出 json.jsondecodeerror。在生产环境中,应该使用 try...except 块来捕获这个异常,避免程序因此崩溃。
场景示例:从一个 api 获取了一段不完整的 json 字符串。
import json
invalid_json = '{"name": "john", "age": 30,' # 注意这里缺少了结尾的 '}'
try:
data = json.loads(invalid_json)
except json.jsondecodeerror as e:
print(f"json 解析失败: {e}")
# 输出: json 解析失败: unexpected end of document: line 1 column 29 (char 28)3、便捷的命令行工具(json.tool):
python 提供了一个方便的命令行工具,可以快速验证 json 文件的合法性并将其格式化输出。只需在终端运行 python -m json.tool your_file.json 即可。
三、总结
| 功能分类 | 主要成员 | 用途 | 使用频率 |
| 核心功能 | load, loads, dump, dumps | 在 python 对象和 json 之间进行转换(文件/字符串) | 非常高 (99%) |
| 高级定制 | jsonencoder, jsondecoder | 处理非标准/自定义数据类型的序列化和反序列化 | 较低 |
| 错误处理 | jsondecodeerror | 捕获和处理格式错误的 json 数据 | 中等(在生产代码中很重要) |
| 命令行工具 | json.tool | 从命令行快速验证和格式化 json 文件 | 偶尔(对开发者调试很有用) |
到此这篇关于python处理json的四大函数全解析(load/loads/dump/dumps)的文章就介绍到这了,更多相关python处理json内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论