4.springboot集成kafka开发
4.1 创建项目
4.2 配置文件
application.yml
spring:
application:
name: spring-boot-01-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092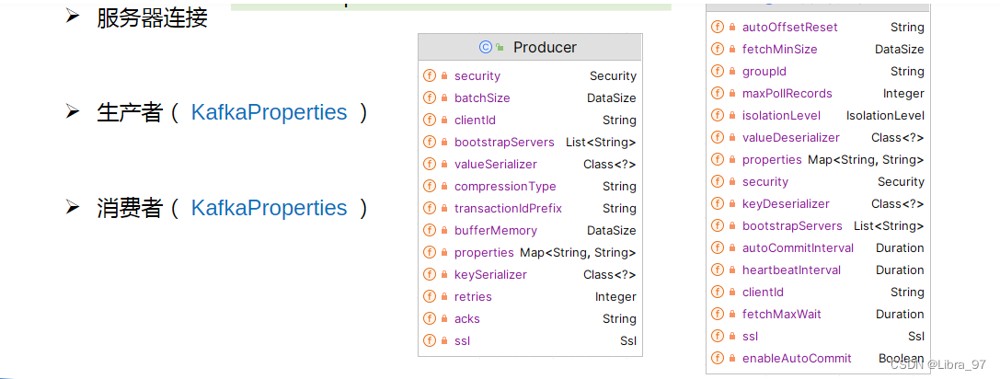
4.3 创建生产者
package com.zzc.producer;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent(){
kafkatemplate.send("hello-topic", "hello kafka");
}
}4.4 测试
package com.zzc.producer;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent(){
kafkatemplate.send("hello-topic", "hello kafka");
}
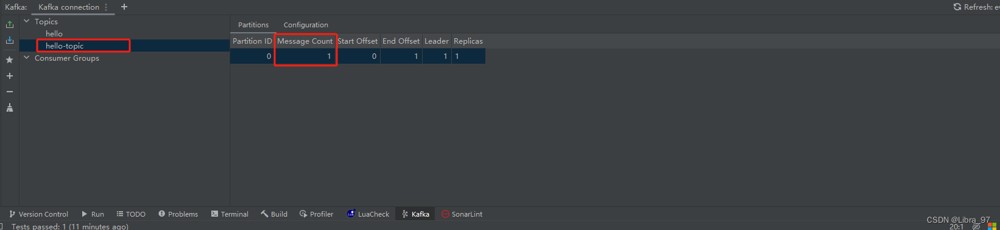
}hello-topic中已存放一个消息
4.5 创建消费者
package com.zzc.cosumer;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
@component
public class eventconsumer {
// 采用监听的方式接收事件(消息、数据)
@kafkalistener(topics = {"hello-topic"}, groupid = "hello-group")
public void onevent(string event){
system.out.printf("读取到的事件:" + event);
}
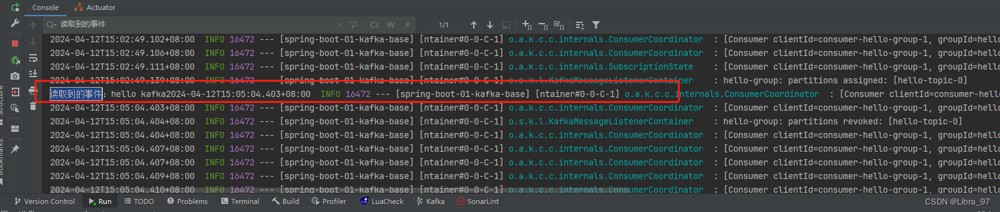
}启动springboot,发现并没有读取到之前的消息

此时使用测试类调用生成者再发送一个消息,此时消费者成功监听到刚生产的消息
4.6 kafka的几个概念
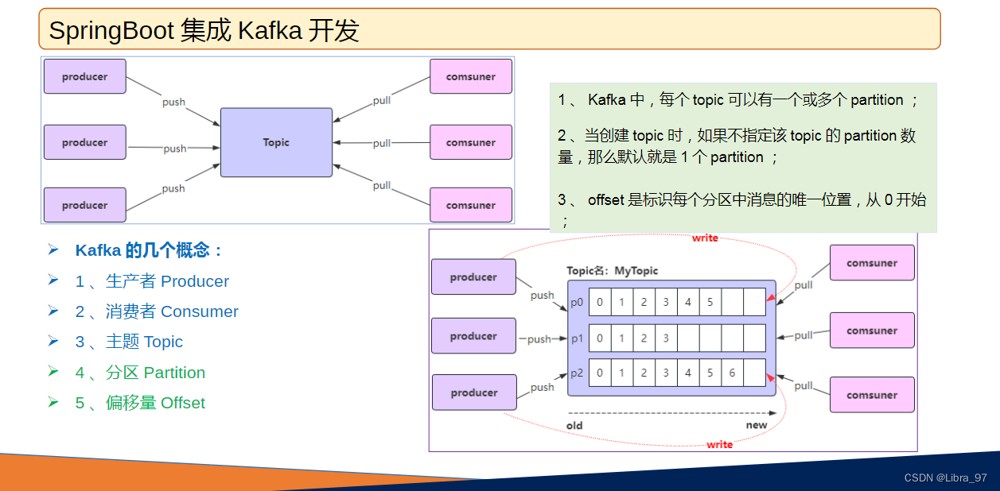
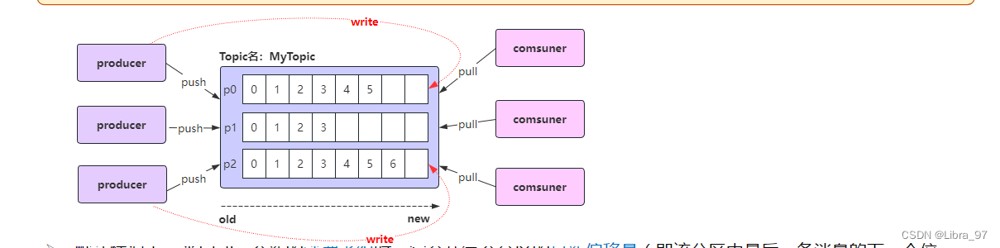
- 默认情况下,当启动一个新的消费者组时,它会从每个分区的最新偏移量(即该分区中最后一条消息的下一个位置)开始消费。如果希望从第一条消息开始消费,需要将消费者的 auto.offset.reset 设置为 earliest ;
- 注意: 如果之前已经用相同的消费者组 id 消费过该主题,并且 kafka 已经保存了该消费者组的偏移量,那么即使你设置了 auto.offset.reset=earliest ,该设置也不会生效,因为 kafka 只会在找不到偏移量时使用这个配置。在这种情况下,你需要手动重置偏移量或使用一个新的消费者组 id ;
4.7 消息消费时偏移量策略的配置
spring: kafka: consumer: auto-offset-reset: earliest
- 取值: earliest 、 latest 、 none 、 exception
- earliest :自动将偏移量重置为最早的偏移量;
- latest :自动将偏移量重置为最新偏移量;
- none :如果没有为消费者组找到以前的偏移量,则向消费者抛出异常;
- exception :向消费者抛出异常;( spring-kafka 不支持)
4.7.1 测试修改配置后能否消费之前的消息
修改配置重启服务后,并没有消费之前的消息

修改消费者组id,再次重启服务进行测试
@component
public class eventconsumer {
// 采用监听的方式接收事件(消息、数据)
@kafkalistener(topics = {"hello-topic"}, groupid = "hello-group-02")
public void onevent(string event){
system.out.println("读取到的事件:" + event);
}
}成功读取到之前的消息

4.7.2 手动重置偏移量
修改为读取最早的消息 ./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-earliest --execute 修改为读取最新的消息 ./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-latest --execute
执行命令
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group hello-group-02 --topic hello-topic --reset-offsets --to-earliest --execute

报错:提示我们不能在活跃的情况下进行修改偏移量,需要先停止服务
再次执行命令,已经重置偏移量成功

此时启动服务,读取到之前的消息了

4.8 生产者发送消息参数(生产者客户端向kafka的主题topic中写入事件)
4.8.1 message对象参数
/**
* 使用message对象发送消息
*/
public void sendevent02(){
// 通过构建器模式创建message对象
message<string> message = messagebuilder.withpayload("hello kafka")
// 在header中放置topic的名字
.setheader(kafkaheaders.topic, "test-topic-02")
.build();
kafkatemplate.send(message);
}测试是否发送消息到topic中
@test
public void test02(){
eventproducer.sendevent02();
}
成功发送消息到test-topic-02中
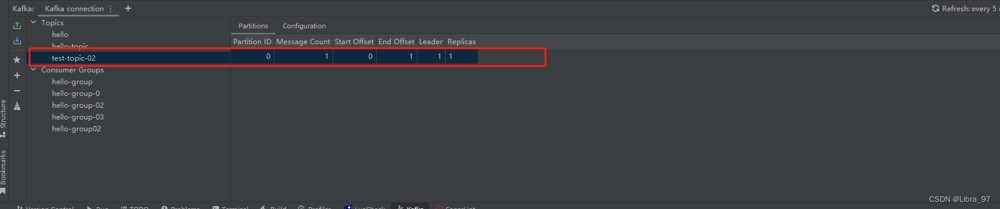
4.8.2 producerrecord对象参数
/**
* 使用producerrecord对象发送消息
*/
public void sendevent03(){
// headers里面是放一些信息(信息是key-value键值对),到时候消费者接收到该消息后,可以拿到这个headers里面放的信息
headers headers = new recordheaders();
headers.add("phone", "13698001234".getbytes(standardcharsets.utf_8));
headers.add("orderid", "12473289472846178242873".getbytes(standardcharsets.utf_8));
producerrecord<string, string> producerrecord = new producerrecord<>(
"test-topic-02",
0,
system.currenttimemillis(),
"k1",
"hello kafka",
headers
);
kafkatemplate.send(producerrecord);
}测试
@test
public void test03(){
eventproducer.sendevent03();
}
成功向test-topic-02中发送一条消息
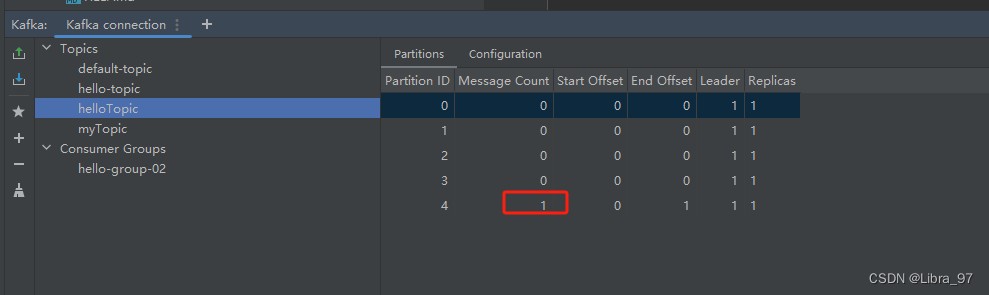
4.8.3 send最多参数构造方法
public void sendevent04() {
// string topic, integer partition, long timestamp, k key, @nullable v data
kafkatemplate.send(
"test-topic-02",
0,
system.currenttimemillis(),
"k2",
"hello kafka"
);
}测试
@test
public void test04(){
eventproducer.sendevent04();
}
成功向test-topic-02中发送一条消息

4.8.4 senddefault最多参数构造方法
public void sendevent05(){
kafkatemplate.senddefault(0, system.currenttimemillis(), "k3", "hello kafka");
}
测试
@test
public void test04(){
eventproducer.sendevent04();
}
执行测试方法,报错提示 topic不能为空
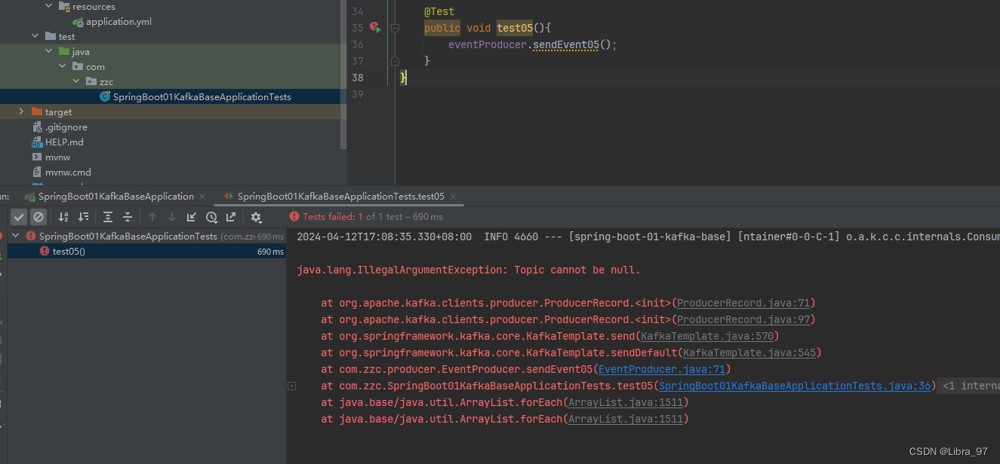
需要在配置文件中添加配置
spring:
application:
name: spring-boot-01-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
consumer:
auto-offset-reset: earliest
# 配置模板默认的主题topic名称
template:
default-topic: default-topic再次执行测试方法,成功向default-topic中发送消息
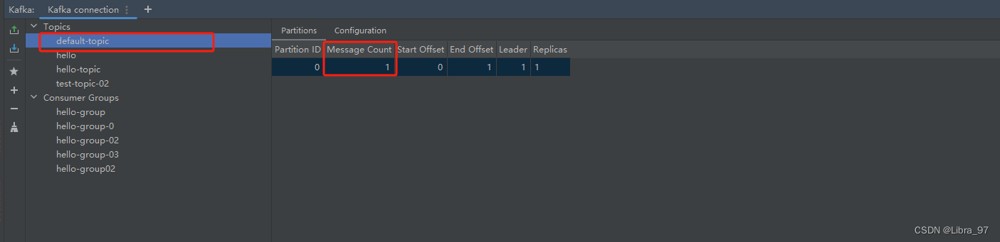
4.9 kafkatemplate.send()和kafkatemplate.senddefault()的区别
- 主要区别是发送消息到 kafka 时是否每次都需要指定主题 topic;
- kafkatemplate.send(…) 该方法需要明确地指定要发送消息的目标主题 topic ;
- kafkatemplate.senddefault() 该方法不需要指定要发送消息的目标主题 topic ;
- kafkatemplate.send(…) 方法适用于需要根据业务逻辑或外部输入动态确定消息目标 topic 的场景;
- kafkatemplate.senddefault() 方法适用于总是需要将消息发送到特定默认 topic 的场景;
- kafkatemplate.senddefault() 是一个便捷方法,它使用配置中指定的默认主题 topic 来发送消息;
- 如果应用中所有消息都发送到同一个主题时采用该方法非常方便,可以减少代码的重复或满足特定的业务需求;
4.10 获取生产者消息发送结果
- .send() 方法和 .senddefault() 方法都返回 completablefuture<sendresult<k, v>> ;
- completablefuture 是 java 8 中引入的一个类,用于异步编程,它表示一个异步计算的结果,这个特性使得调用者不必等待操作完成就能继续执行其他任务,从而提高了应用程序的响应速度和吞吐量;
- 方式一:调用 completablefuture 的 get() 方法,同步阻塞等待发送结果;
- 方式二:使用 thenaccept(), thenapply(), thenrun() 等方法来注册回调函数,回调函数将在completablefuture 完成时被执行;
4.10.1 调用 completablefuture 的 get() 方法,同步阻塞等待发送结果
/**
* 通过get方法同步阻塞等待发送结果
*/
public void sendevent06(){
completablefuture<sendresult<string, string>> completablefuture =
kafkatemplate.senddefault(0, system.currenttimemillis(), "k3", "hello kafka");
try {
// 1.阻塞等待的方式拿结果
sendresult<string, string> sendresult = completablefuture.get();
if (sendresult.getrecordmetadata() != null){
// kafka服务器确认已经接收到了消息
system.out.println("消息发送成功:" + sendresult.getrecordmetadata().tostring());
}
system.out.println("producerrecord: " + sendresult.getproducerrecord());
} catch (exception e) {
throw new runtimeexception(e);
}
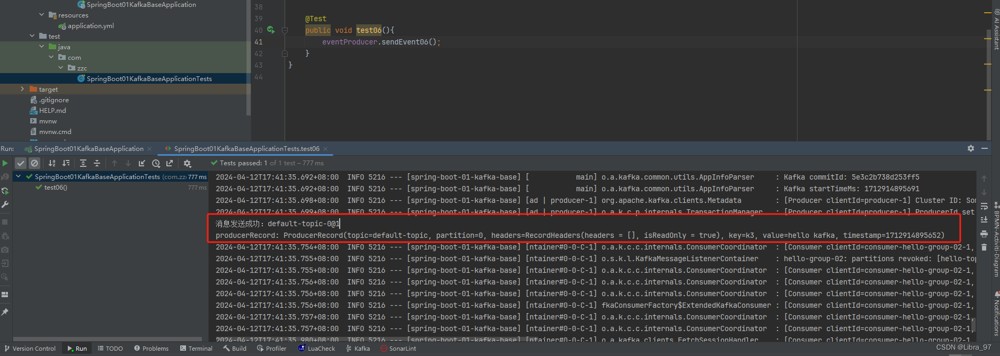
}测试,成功获取到结果和发送的消息信息
@test
public void test06(){
eventproducer.sendevent06();
}
4.10.2 使用 thenaccept()方法来注册回调函数,回调函数将在completablefuture 完成时被执行
/**
* 通过thenaccept方法注册回调函数
*/
public void sendevent07(){
completablefuture<sendresult<string, string>> completablefuture =
kafkatemplate.senddefault(0, system.currenttimemillis(), "k3", "hello kafka");
completablefuture.thenaccept(sendresult -> {
if (sendresult.getrecordmetadata() != null){
// kafka服务器确认已经接收到了消息
system.out.println("消息发送成功:" + sendresult.getrecordmetadata().tostring());
}
system.out.println("producerrecord: " + sendresult.getproducerrecord());
}).exceptionally( throwable -> {
// 做失败的处理
throwable.printstacktrace();
return null;
});
}
测试,成功获取到结果和发送的消息信息
@test
public void test07(){
eventproducer.sendevent07();
}

4.11 生产者发送对象消息
4.11.1 创建user对象
@builder
@allargsconstructor
@noargsconstructor
@data
public class user {
private int id;
private string phone;
private date birthday;
}4.11.2 注入新的kafkatemplate对象,因为之前的key和value泛型都是string类型
/**
* 发送对象消息
*/
@resource
private kafkatemplate<string, object> kafkatemplate2;
private kafkatemplate<string, object> kafkatemplate2;
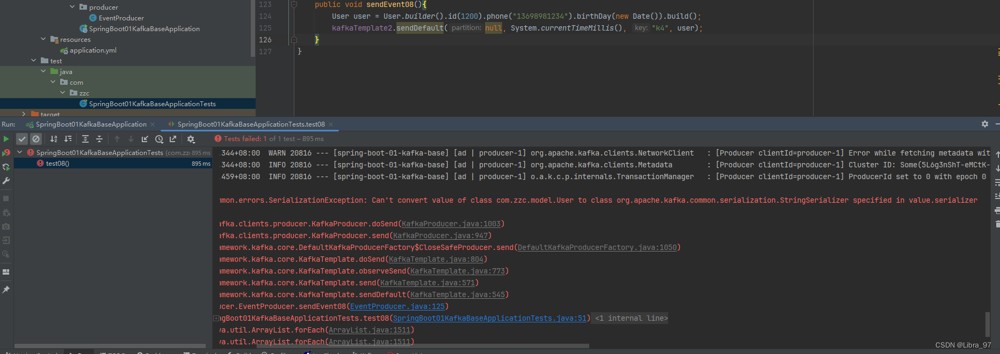
public void sendevent08(){
user user = user.builder().id(1200).phone("13698981234").birthday(new date()).build();
// 分区编号为 null ,交给 kafka 自己去分配
kafkatemplate2.senddefault(null, system.currenttimemillis(), "k4", user);
}
4.11.3 测试发送消息
报错 说不能将value转成stringserializer
需要在配置文件中指定value的serializer类型
producer:
# key和value都默认是stringserializer
value-serializer: org.springframework.kafka.support.serializer.jsonserializer
再次执行测试,执行成功
defalut-topic中新增一条消息
4.12 kafka的核心概念:replica副本
- replica :副本,为实现备份功能,保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且
kafka 仍然能够继续工作, kafka 提供了副本机制,一个 topic 的每个分区都有 1 个或多个副本; - replica 副本分为 leader replica 和 follower replica :
- leader :每个分区多个副本中的“主”副本,生产者发送数据以及消费者消费数据,都是来自 leader 副本
- follower :每个分区多个副本中的“从”副本,实时从 leader 副本中同步数据,保持和 leader 副本数据的同
步, leader 副本发生故障时,某个 follower 副本会成为新的 leader 副本;
- 设置副本个数不能为 0 ,也不能大于节点个数,否则将不能创建 topic ;
4.12.1 指定topic的分区和副本
4.12.1.1 方式一:通过kafka提供的命令行工具在创建topic时指定分区和副本
./kafka-topics.sh --create --topic mytopic --partitions 3 --replication-factor 1 --bootstrap-server 127.0.0.1:9092
创建成功
4.12.1.2 方式二:执行代码时指定分区和副本
- kafkatemplate.send(“topic”, message);
- 直接使用 send() 方法发送消息时, kafka 会帮我们自动完成 topic 的创建工作,但这种情况下创建的 topic 默认只有一个分区,分区有 1 个副本,也就是有它自己本身的副本,没有额外的副本备份;
- 我们可以在项目中新建一个配置类专门用来初始化 topic ;
@configuration
public class kafkaconfig {
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
// 副本不能设置为0 也不能超过节点数
return new newtopic("hellotopic", 5, (short) 1);
}
}创建成功
4.12.2 测试重启服务会不会重置消息,先向hellotopic中发送一个消息
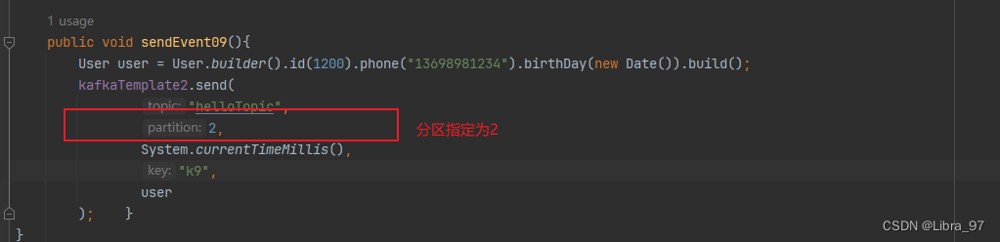
public void sendevent09(){
user user = user.builder().id(1200).phone("13698981234").birthday(new date()).build();
kafkatemplate2.send(
"hellotopic",
null,
system.currenttimemillis(),
"k9",
user
);
}
测试代码
@test
public void test09(){
eventproducer.sendevent09();
}
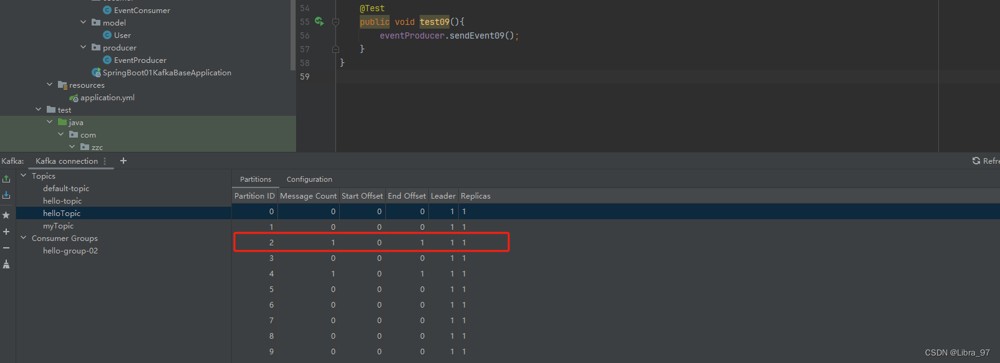
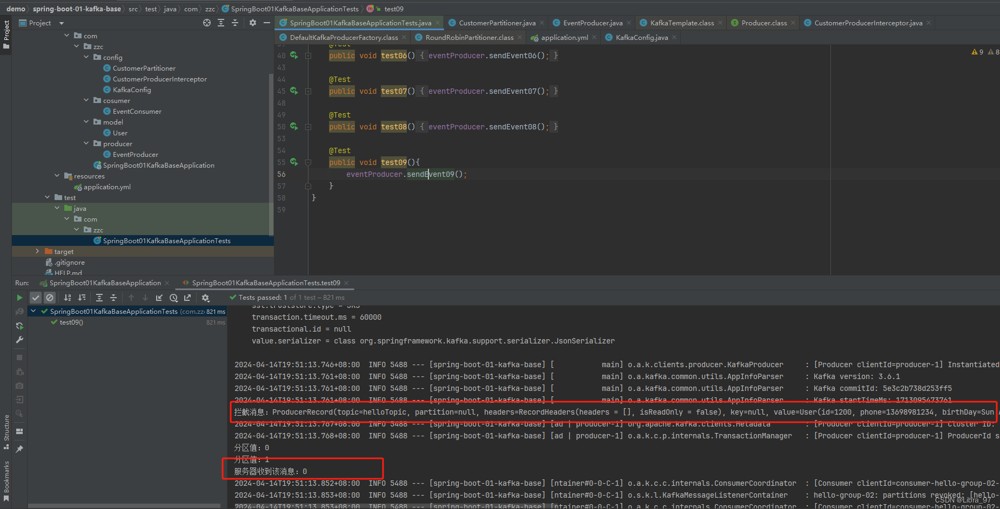
成功向hellotopic中发送一个消息
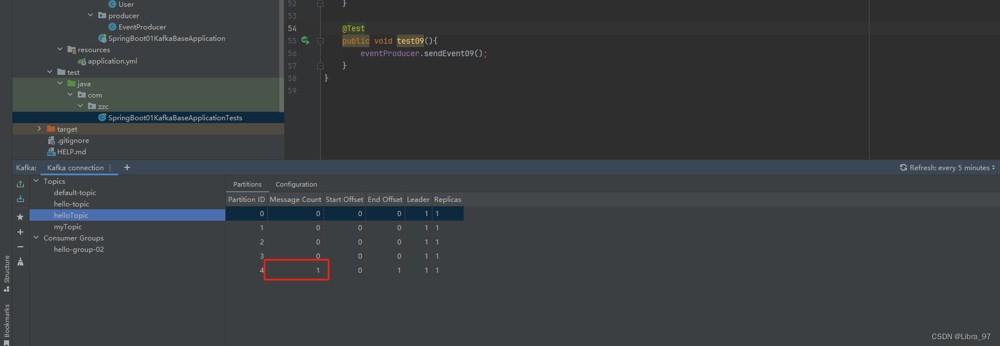
重启服务后,并没有重置消息
4.12.3 修改分区数
配置类中增加更新配置代码
@configuration
public class kafkaconfig {
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
return new newtopic("hellotopic", 5, (short) 1);
}
// 如果要修改分区数,只需修改配置值重启项目即可,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减少
@bean
public newtopic updatetopic(){
return new newtopic("hellotopic", 10, (short) 1);
}
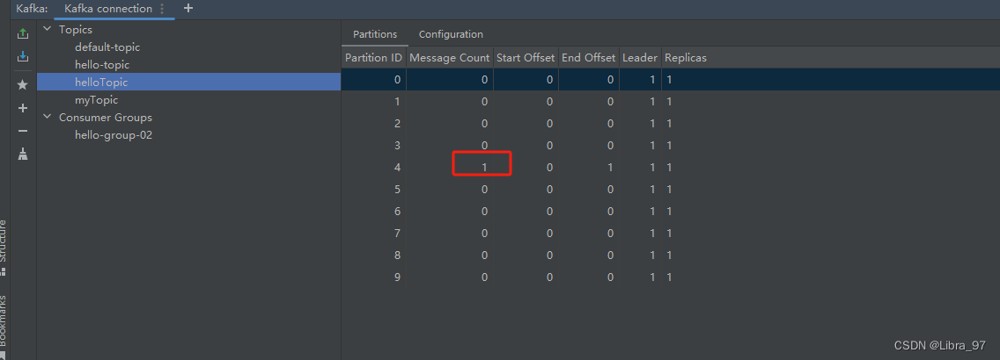
}重启项目,分区数更新为10,消息的位置也没发生变化
4.13 生产者发送消息的分区策略(消息发到哪个分区中?是什么策略)
- 生产者写入消息到topic,kafka将依据不同的策略将数据分配到不同的分区中
如果指定了分区,那将发送消息到指定分区中
执行测试代码
看send方法源代码可以看到
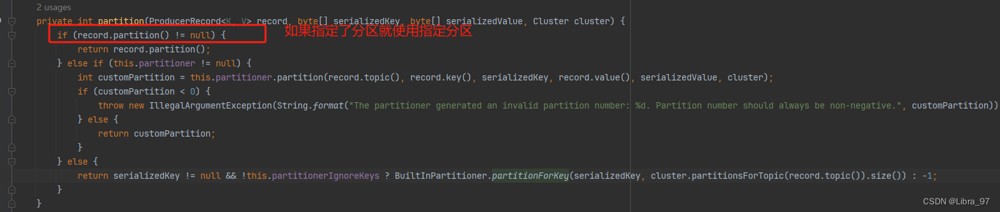
- 默认分配策略:builtinpartitioner
- 有key:utils.topositive(utils.murmur2(serializedkey)) % numpartitions;
- 没有key:使用随机数 % numpartitions
- 轮询分配策略:roundrobinpartitioner(实现的接口:partitioner)
- 自定义分配策略:我们自己定义
4.13.1 轮询分配策略
yml配置文件
spring:
application:
name: spring-boot-01-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
producer:
# key和value都默认是stringserializer
value-serializer: org.springframework.kafka.support.serializer.jsonserializer
key-serializer: org.apache.kafka.common.serialization.stringserializer
consumer:
auto-offset-reset: earliest
# 配置模板默认的主题topic名称
template:
default-topic: default-topic配置类
package com.zzc.config;
import org.apache.kafka.clients.admin.newtopic;
import org.apache.kafka.clients.producer.producerconfig;
import org.apache.kafka.clients.producer.roundrobinpartitioner;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.kafka.core.defaultkafkaproducerfactory;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.kafka.core.producerfactory;
import java.util.hashmap;
import java.util.map;
@configuration
public class kafkaconfig {
@value("${spring.kafka.bootstrap-servers}")
private string bootstrapservers;
@value("${spring.kafka.producer.value-serializer}")
private string valueserializer;
@value("${spring.kafka.producer.key-serializer}")
private string keyserializer;
/**
* 生产者相关配置
* @return
*/
public map<string, object> producerconfigs(){
hashmap<string, object> props = new hashmap<>();
props.put(producerconfig.bootstrap_servers_config, bootstrapservers);
props.put(producerconfig.key_serializer_class_config, keyserializer);
props.put(producerconfig.value_serializer_class_config, valueserializer);
props.put(producerconfig.partitioner_class_config, roundrobinpartitioner.class);
return props;
}
public producerfactory<string, object> producerfactory(){
return new defaultkafkaproducerfactory<>(producerconfigs());
}
/**
* kafkatemplate 覆盖相关配置类中的kafkatemplate
* @return
*/
@bean
public kafkatemplate<string, object> kafkatemplate(){
return new kafkatemplate<>(producerfactory());
}
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
return new newtopic("hellotopic", 5, (short) 1);
}
// 如果要修改分区数,只需修改配置值重启项目即可,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减少
@bean
public newtopic updatetopic(){
return new newtopic("hellotopic", 10, (short) 1);
}
}执行测试代码
public void sendevent09(){
user user = user.builder().id(1200).phone("13698981234").birthday(new date()).build();
kafkatemplate2.send(
"hellotopic",
user
); }
@test
public void test09(){
for (int i = 0; i < 5; i++) {
eventproducer.sendevent09();
}
}
debug模式,是进入到roundrobinpartitioner类中
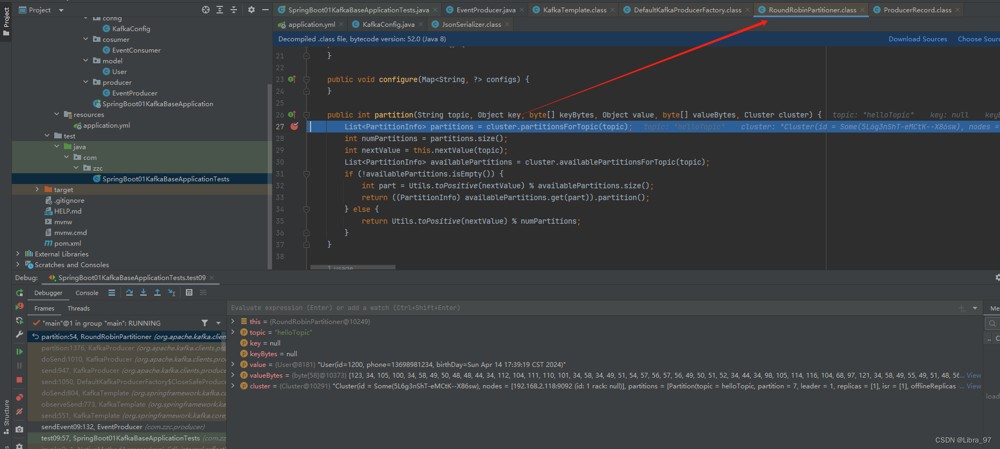
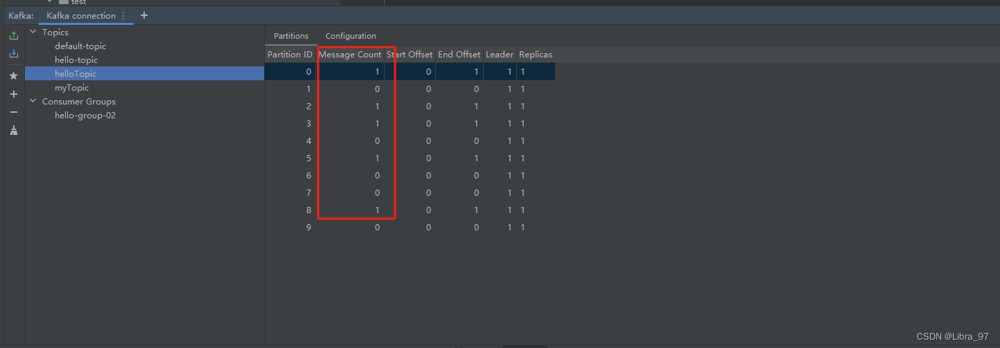
查看消息的分区情况,发现并没有完全的轮询,有点误差
4.13.2 自定义分配策略
创建自定义分配策略类实现partitioner接口
public class customerpartitioner implements partitioner {
private atomicinteger nextpartition = new atomicinteger(0);
@override
public int partition(string topic, object key, byte[] keybytes, object value, byte[] bytes1, cluster cluster) {
list<partitioninfo> partitions = cluster.partitionsfortopic(topic);
int numpartitions = partitions.size();
if (key == null){
// 使用轮询方式选择分区
int next = nextpartition.getandincrement();
// 如果next大于分区的大小,则重置为0
if (next >= numpartitions){
nextpartition.compareandset(next, 0);
}
system.out.println("分区值:" + next);
return next;
}else {
// 如果key不为null,则使用默认的分区策略
return utils.topositive(utils.murmur2(keybytes)) % numpartitions;
}
}
@override
public void close() {
}
@override
public void configure(map<string, ?> map) {
}
}配置类代码中将分配策略修改为自定义分配策略
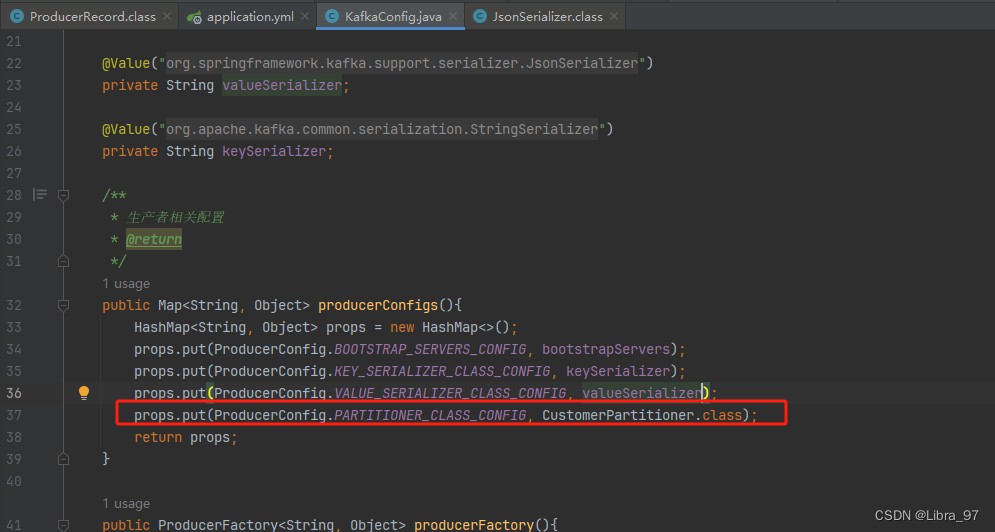
使用debug模式执行测试代码,成功执行到我们自定义的分配策略类中
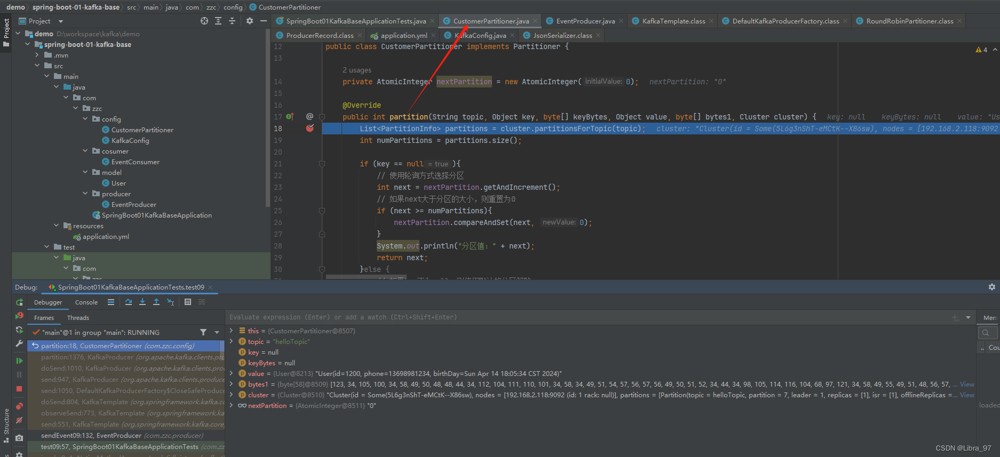
执行结果
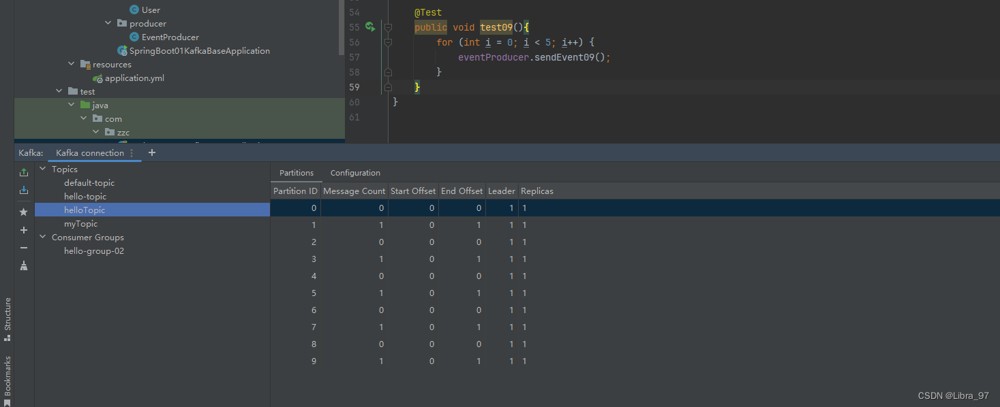
为什么是每隔一个存一个分区呢?查看源代码发现进行了二次计算partition
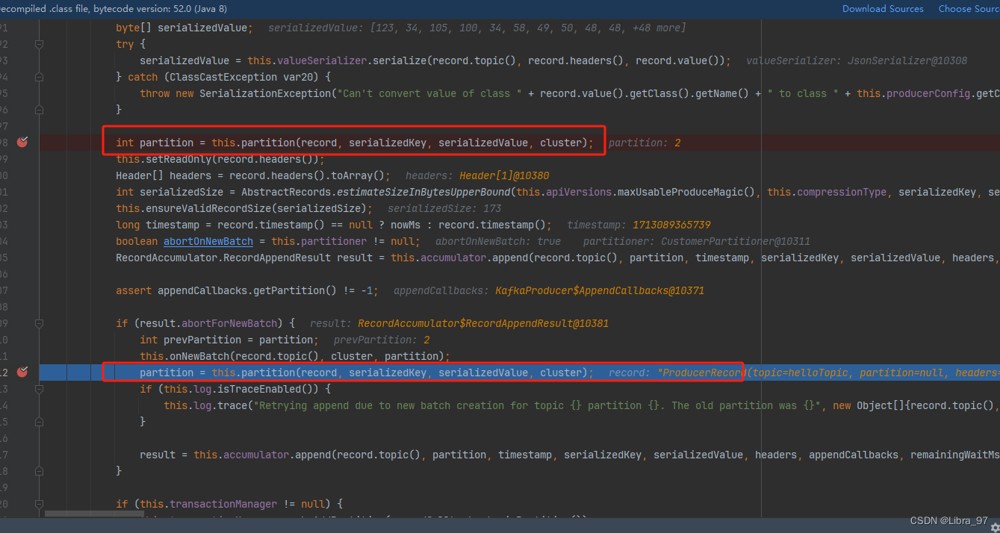
4.13 生产者发送消息的流程
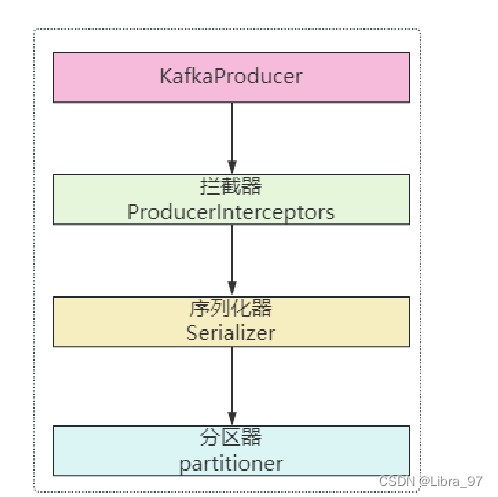
4.13.自定义拦截器拦截消息的发送
实现producerinterceptor接口,创建customerproducerinterceptor类
package com.zzc.config;
import org.apache.kafka.clients.producer.producerinterceptor;
import org.apache.kafka.clients.producer.producerrecord;
import org.apache.kafka.clients.producer.recordmetadata;
import java.util.map;
public class customerproducerinterceptor implements producerinterceptor<string, object> {
/**
* 发送消息时,会先调用该方法,对信息进行拦截,可以在拦截中对消息做一些处理,记录日志等操作...
* @param producerrecord
* @return
*/
@override
public producerrecord<string, object> onsend(producerrecord<string, object> producerrecord) {
system.out.println("拦截消息:" + producerrecord.tostring());
return producerrecord;
}
/**
* 服务器收到消息后的一个确认
* @param recordmetadata
* @param e
*/
@override
public void onacknowledgement(recordmetadata recordmetadata, exception e) {
if (recordmetadata != null){
system.out.println("服务器收到该消息:" + recordmetadata.offset());
}else {
system.out.println("消息发送失败了,exception = " + e.getmessage());
}
}
@override
public void close() {
}
@override
public void configure(map<string, ?> map) {
}
}配置类中添加拦截器
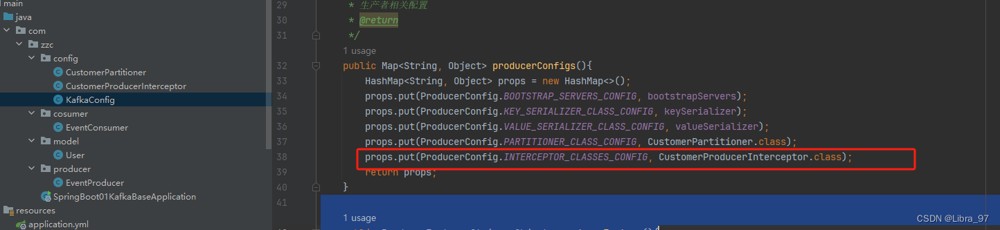
执行测试,发现报错了
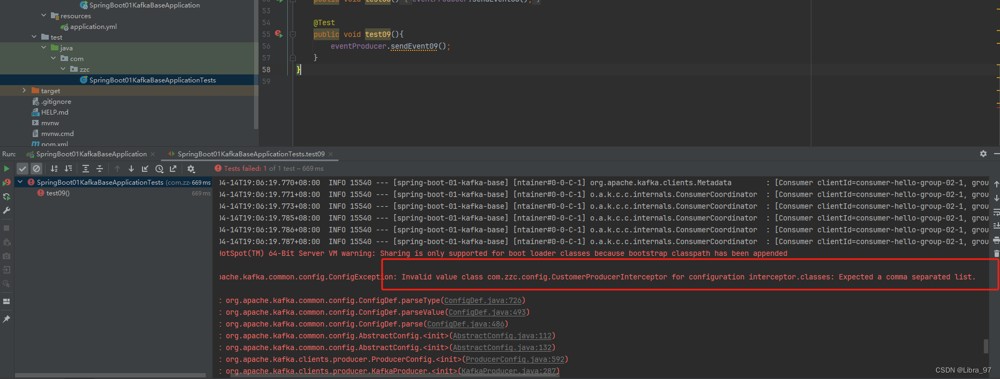
需要配置类中添加拦截器的名字
再次执行测试,成功执行了
4.14 获取生产者发送的消息
之前模块内容比较多,重新创建一个模块
消费者类
@component
public class eventconsumer {
// 采用监听的方式接收事件(消息、数据)
@kafkalistener(topics = {"hellotopic"}, groupid = "hellogroup")
public void onevent(string event){
system.out.println("读取到的事件:" + event);
}
}生产者类
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent() {
kafkatemplate.send("hellotopic", "hello kafka");
}
}配置文件
spring:
application:
name: spring-boot-02-kafka-base
kafka:
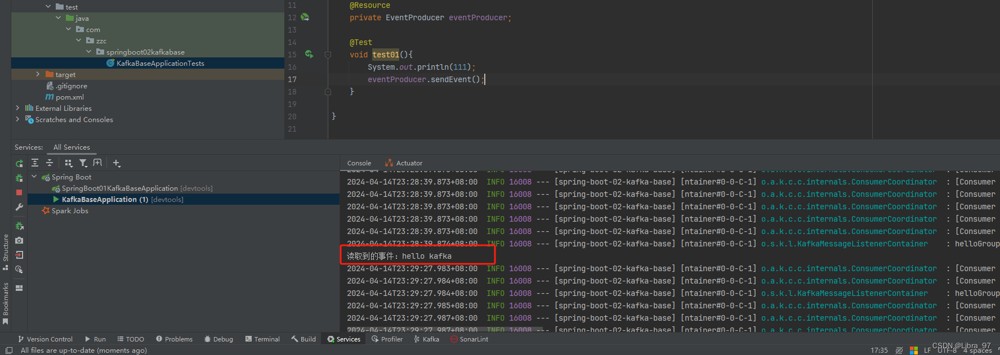
bootstrap-servers: 192.168.2.118:9092测试代码
@springboottest
class kafkabaseapplicationtests {
@resource
private eventproducer eventproducer;
@test
void test01(){
system.out.println(111);
eventproducer.sendevent();
}
}启动服务,执行测试代码,成功读取到最新发送的消息
4.14.1 @payload : 标记该参数是消息体内容
消费者类参数添加@payload注解
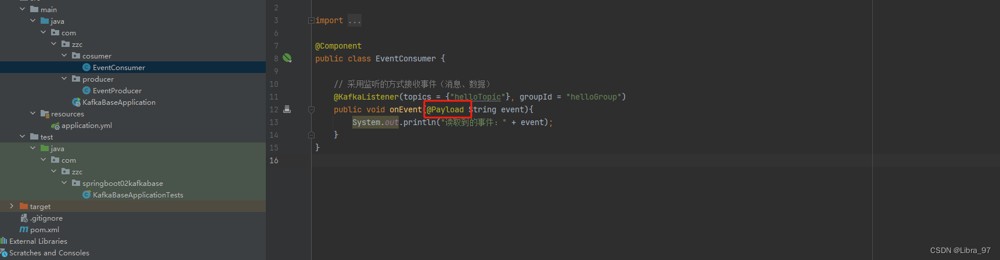
重启服务,执行测试代码 成功读取到最新消息
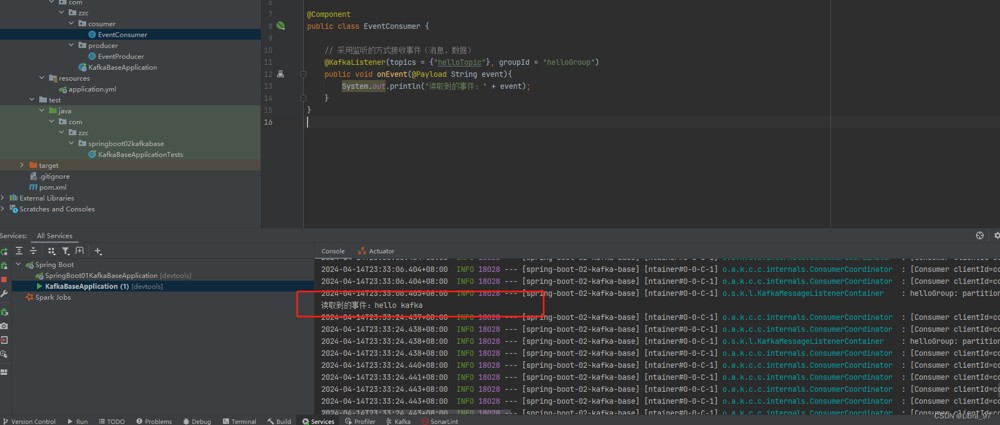
4.14.2 @header注解:标记该参数是消息头内容
消费者类参数添加@header注解 获取header中的topic和partition
@component
public class eventconsumer {
// 采用监听的方式接收事件(消息、数据)
@kafkalistener(topics = {"hellotopic"}, groupid = "hellogroup")
public void onevent(@payload string event,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition
){
system.out.println("读取到的事件:" + event + ", topic:" + topic + ", partition:" + partition);
}
}重启服务类,测试代码不变,进行测试
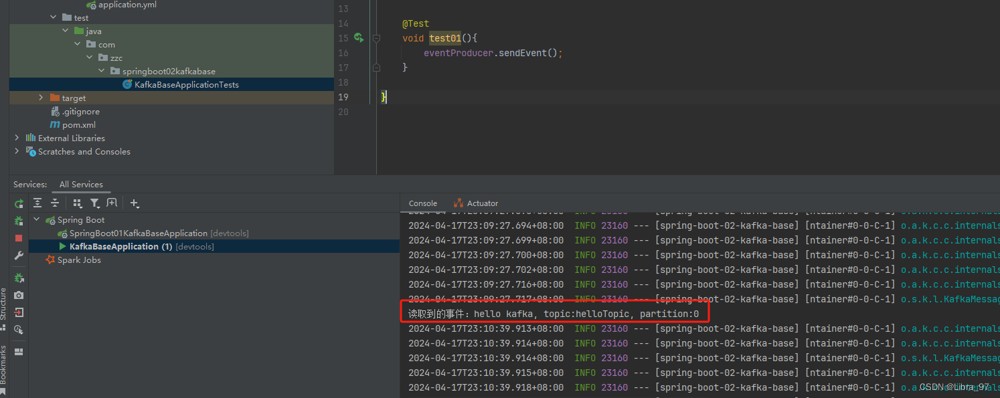
4.14.3 consumerrecord对象
可以从consumerrecord对象中获取想要的内容
@component
public class eventconsumer {
// 采用监听的方式接收事件(消息、数据)
@kafkalistener(topics = {"hellotopic"}, groupid = "hellogroup")
public void onevent(@payload string event,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord
){
system.out.println("读取到的事件:" + event + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord:" + consumerrecord.tostring());
}
}重启服务类,测试代码不变,进行测试
想要的内容都可以从consumerrecord对象中获取
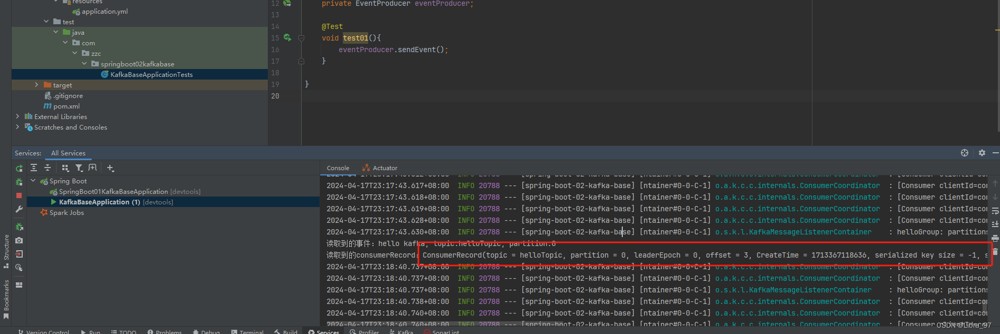
4.14.4 获取对象类型数据
user类代码
package com.zzc.model;
import lombok.allargsconstructor;
import lombok.builder;
import lombok.data;
import lombok.noargsconstructor;
import java.util.date;
@builder
@allargsconstructor
@noargsconstructor
@data
public class user {
private int id;
private string phone;
private date birthday;
}eventconsumer类新增onevent2方法
@kafkalistener(topics = {"hellotopic"}, groupid = "hellogroup")
public void onevent2(user user,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord
){
system.out.println("读取到的事件:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord:" + consumerrecord.tostring());
}
eventproducer类新增sendevent2方法
@resource
private kafkatemplate<string, object> kafkatemplate2;
public void sendevent2(){
user user = user.builder().id(213234).phone("13239407234").birthday(new date()).build();
kafkatemplate2.send("hellotopic", user);
}
测试类新增test02方法
@test
public void test02(){
eventproducer.sendevent2();
}
执行测试,报错生产者不能将user转换成string类型
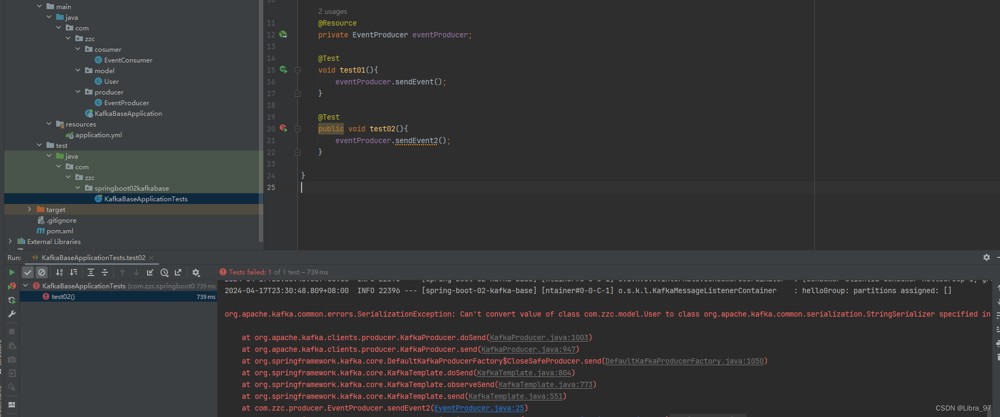
去配置文件中修改生产者和消费者的value序列化器
spring:
application:
name: spring-boot-02-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
producer:
value-serializer: org.springframework.kafka.support.serializer.jsonserializer
consumer:
value-deserializer: org.springframework.kafka.support.seri重新启动服务,依然报错,说没有找到jackson的jar包

那我们去pom文件中添加jackson依赖
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-json</artifactid>
</dependency>添加依赖后可以正常启动了
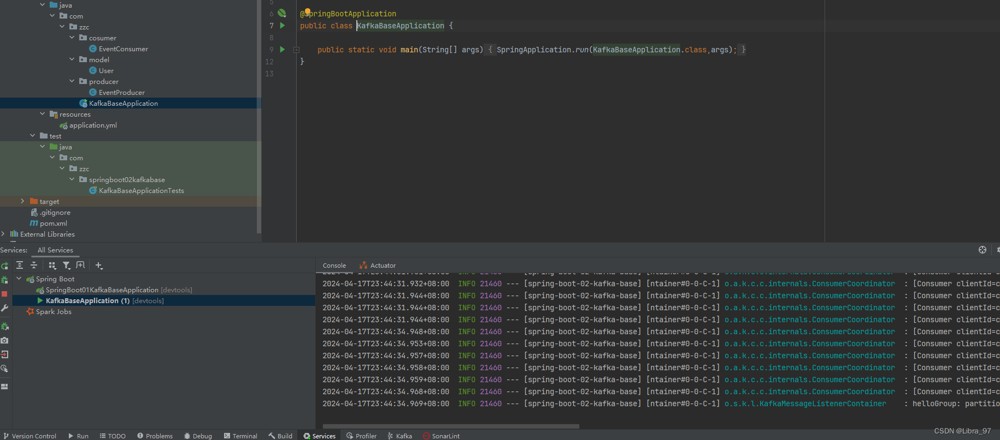
执行测试代码,服务一直报错,说user类不受安全的,只有java.util, java.lang下的类才是安全的
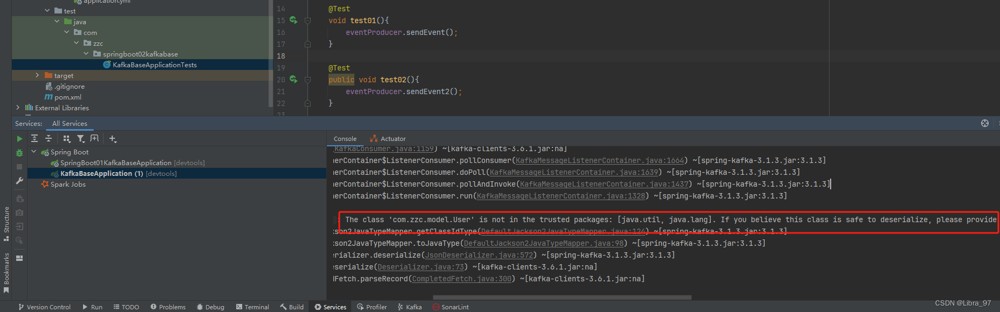
解决方案:将对象类型转为string类型进行发送,读取的时候再将string类型转为对象类型
创建jsonutils类
package com.zzc.util;
import com.fasterxml.jackson.core.jsonprocessingexception;
import com.fasterxml.jackson.databind.objectmapper;
public class jsonutils {
private static final objectmapper objectmapper = new objectmapper();
public static string tojson(object object){
try {
return objectmapper.writevalueasstring(object);
}catch (jsonprocessingexception e){
throw new runtimeexception(e);
}
}
public static <t> t tobean(string jsonstr, class<t> clazz){
try {
return objectmapper.readvalue(jsonstr, clazz);
} catch (jsonprocessingexception e) {
throw new runtimeexception(e);
}
}
}修改eventproducer代码,将原本的user类型改为string类型发送到topic中
public void sendevent2(){
user user = user.builder().id(213234).phone("13239407234").birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("hellotopic", userjson);
}
修改eventconsumer代码,将原本中参数的user类型改为string类型,再转换成user类型进行消费
@kafkalistener(topics = {"hellotopic"}, groupid = "hellogroup")
public void onevent2(string userstr,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord
){
user user = (user) jsonutils.tobean(userstr, user.class);
system.out.println("读取到的事件:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord:" + consumerrecord.tostring());
}
将配置文件中的消费者和生产者配置都注释掉
spring:
application:
name: spring-boot-02-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
# producer:
# value-serializer: org.springframework.kafka.support.serializer.jsonserializer
# consumer:
# value-deserializer: org.springframework.kafka.support.serializer.jsondeserializer重启服务,再次执行测试代码
4.14.5 获取自定义配置参数的数据
自定义配置topic的name和consumer的group值,消费者进行读取
spring:
application:
name: spring-boot-02-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
# producer:
# value-serializer: org.springframework.kafka.support.serializer.jsonserializer
# consumer:
# value-deserializer: org.springframework.kafka.support.serializer.jsondeserializer
kafka:
topic:
name: hellotopic
consumer:
group: hellogroup使用${}的方式进行读取配置文件中的值
@kafkalistener(topics = {"${kafka.topic.name}"}, groupid = "kafka.consumer.group")
public void onevent3(string userstr,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord
){
user user = (user) jsonutils.tobean(userstr, user.class);
system.out.println("读取到的事件3:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord3:" + consumerrecord.tostring());
}重启服务,执行测试代码,能够读取到消息
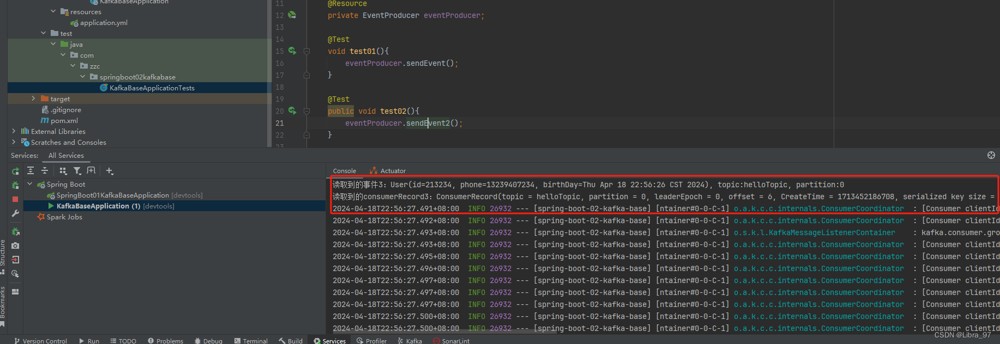
4.14.6 ack手动确认消息
默认情况下, kafka 消费者消费消息后会自动发送确认信息给 kafka 服务器,表示消息已经被成功消费。但在
某些场景下,我们希望在消息处理成功后再发送确认,或者在消息处理失败时选择不发送确认,以便 kafka 能
够重新发送该消息;
eventconsumer类代码
@kafkalistener(topics = {"${kafka.topic.name}"}, groupid = "kafka.consumer.group")
public void onevent4(string userstr,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord,
acknowledgment acknowledgment
){
user user = (user) jsonutils.tobean(userstr, user.class);
system.out.println("读取到的事件4:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord4:" + consumerrecord.tostring());
}
配置文件中添加手动ack模式
kafka:
bootstrap-servers: 192.168.2.118:9092
listener:
ack-mode: manual重启服务,执行测试代码。无论重启多少此服务,都能读取到这条消息,因为还没有确认消费这条消息,所以offset一直没有变
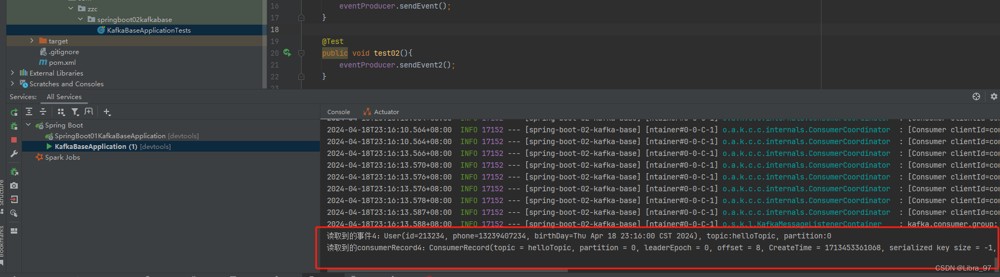
如果在代码中加入确认消费的话,那么就只会读取一次,offset也会发生变化
重启服务后,不再读取到这条消息了

平常业务中可以这么写
@kafkalistener(topics = {"${kafka.topic.name}"}, groupid = "kafka.consumer.group")
public void onevent4(string userstr,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord,
acknowledgment acknowledgment
){
try {
user user = (user) jsonutils.tobean(userstr, user.class);
system.out.println("读取到的事件4:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord4:" + consumerrecord.tostring());
int i = 1 / 0;
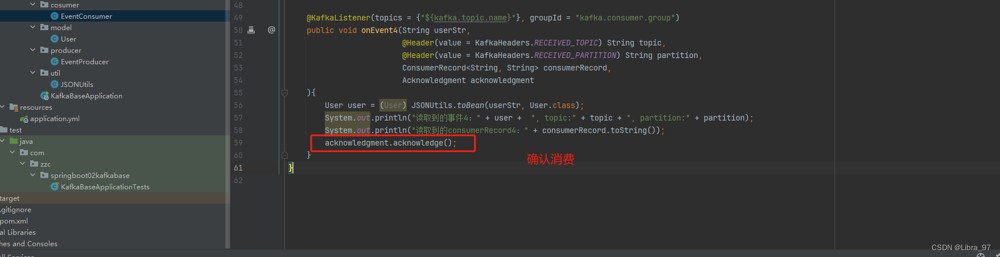
// 可以执行完所有业务,再进行确认消息。如果执行过程中发生异常,那么可以再次消费此消息
acknowledgment.acknowledge();
}catch (exception e){
e.printstacktrace();
}
}
4.14.7 指定 topic 、 partition 、 offset 消费
创建配置类,指定生成5个分区
@configuration
public class kafkaconfig {
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
return new newtopic("hellotopic", 5, (short) 1);
}
}eventconsumer类中新增onevent5方法
@kafkalistener(groupid = "${kafka.consumer.group}",
// 配置更加详细的监听信息 topics和topicpartitions不能同时使用
topicpartitions = {
@topicpartition(
topic = "${kafka.topic.name}",
// 监听topic的0、1、2号分区的所有消息
partitions = {"0", "1", "2"},
// 监听3、4号分区中offset从3开始的消息
partitionoffsets = {
@partitionoffset(partition = "3", initialoffset = "3"),
@partitionoffset(partition = "4", initialoffset = "3")
}
)
})
public void onevent5(string userstr,
@header(value = kafkaheaders.received_topic) string topic,
@header(value = kafkaheaders.received_partition) string partition,
consumerrecord<string, string> consumerrecord,
acknowledgment acknowledgment
){
try {
user user = (user) jsonutils.tobean(userstr, user.class);
system.out.println("读取到的事件5:" + user + ", topic:" + topic + ", partition:" + partition);
system.out.println("读取到的consumerrecord5:" + consumerrecord.tostring());
acknowledgment.acknowledge();
}catch (exception e){
e.printstacktrace();
}
}
eventproducer新增sendevent3方法
public void sendevent3(){
for (int i = 0; i < 25; i++) {
user user = user.builder().id(i).phone("13239407234" + i).birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate2.send("hellotopic", "k" + i, userjson);
}
}
重启服务,执行测试代码
@test
public void test03(){
eventproducer.sendevent3();
}
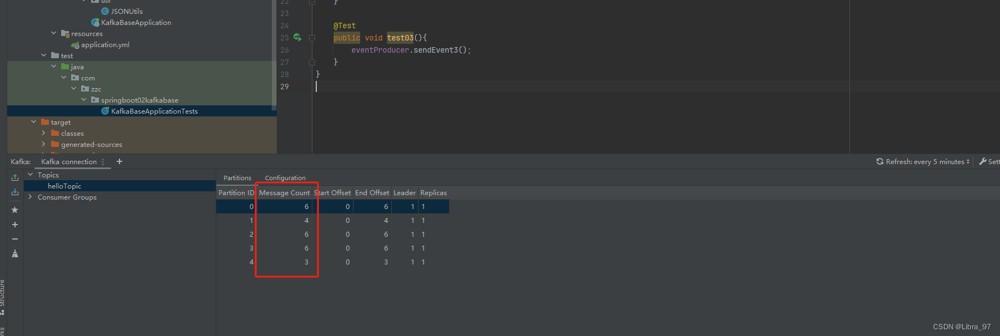
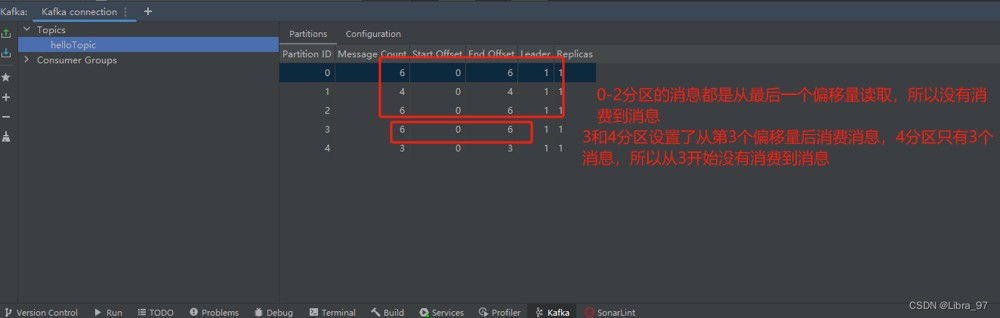
生成的25个消息已经发送到0~4号分区里了
消费消息,注意:需要停止服务,先运行测试代码,再启动服务
发现只消费了3条消息

现在去配置文件中修改成从最早的消息开始消费
consumer:
# 从最早的消息开始消费
auto-offset-reset: earliest再次重启服务进行消费,发现还是只消费到3条消息
这是怎么回事呢?我们之前有遇到过这种情况,有两个解决方案
- 手动修改分区的偏移量
- 换一个消费组id
我们去配置文件中换一个groupid,由原来的hellogroup改为hellogroup1
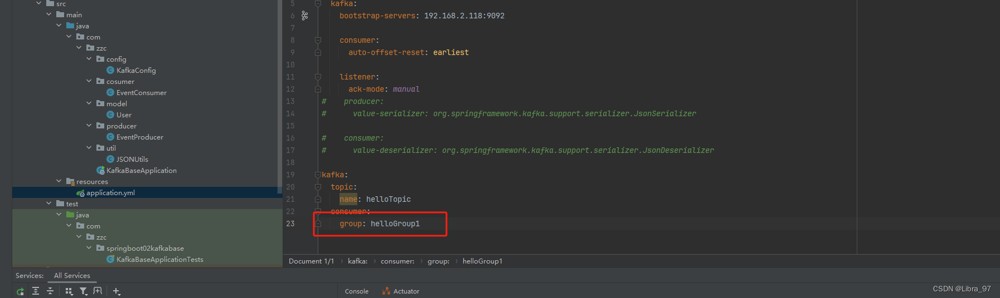
再次重启服务,发现已经读取到19个消息了

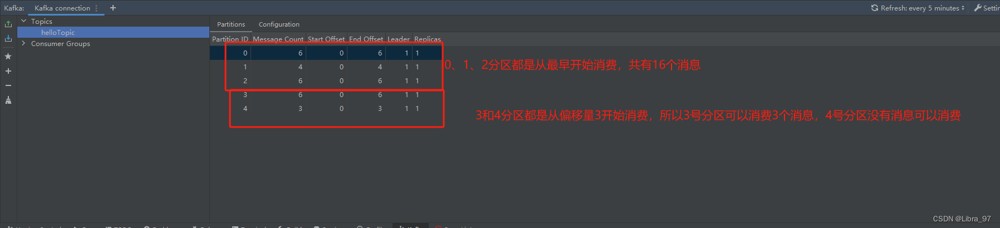
再次重启服务的话,发现又只能消费3个消息了

4.14.8 批量消费消息
重新创建一个模块 spring-boot-03-kafka-base
配置文件进行批量消费配置
spring:
application:
name: spring-boot-03-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
consumer:
# 设置批量最多消费多少条消息
max-poll-records: 20
listener:
# 设置批量消费
type: batch创建eventconsumer类
package com.zzc.springboot03kafkabase.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class eventconsumer {
@kafkalistener(topics = "batchtopic", groupid = "bactchgroup")
public void onevent(list<consumerrecord<string, string>> records) {
system.out.println(" 批量消费, records.size() = " + records.size() + " , records = " + records);
}
}user类
package com.zzc.springboot03kafkabase.model;
import lombok.allargsconstructor;
import lombok.builder;
import lombok.data;
import lombok.noargsconstructor;
import java.util.date;
@builder
@allargsconstructor
@noargsconstructor
@data
public class user {
private int id;
private string phone;
private date birthday;
}创建eventproducer类
package com.zzc.springboot03kafkabase.producer;
import com.zzc.springboot03kafkabase.model.user;
import com.zzc.springboot03kafkabase.util.jsonutils;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
import java.util.date;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent(){
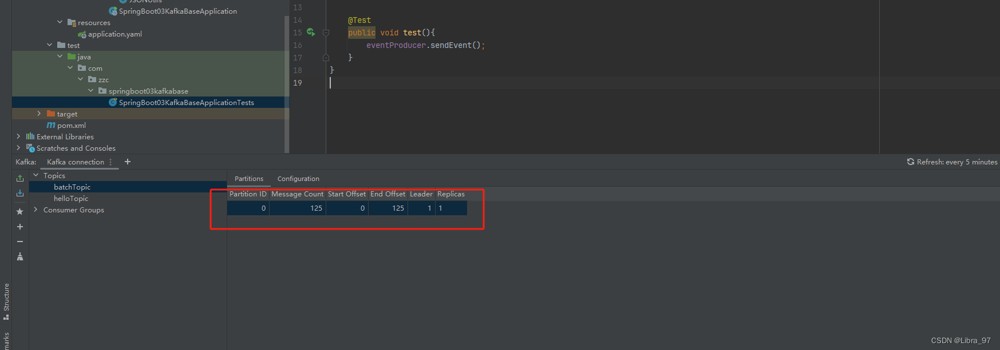
for (int i = 0; i < 125; i++) {
user user = user.builder().id(i).phone("13239407234" + i).birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("batchtopic", "k" + i, userjson);
}
}
}创建json字符串转换对象工具类
package com.zzc.springboot03kafkabase.util;
import com.fasterxml.jackson.core.jsonprocessingexception;
import com.fasterxml.jackson.databind.objectmapper;
public class jsonutils {
private static final objectmapper objectmapper = new objectmapper();
public static string tojson(object object){
try {
return objectmapper.writevalueasstring(object);
}catch (jsonprocessingexception e){
throw new runtimeexception(e);
}
}
public static <t> t tobean(string jsonstr, class<t> clazz){
try {
return objectmapper.readvalue(jsonstr, clazz);
} catch (jsonprocessingexception e) {
throw new runtimeexception(e);
}
}
}pom文件
<?xml version="1.0" encoding="utf-8"?>
<project xmlns="http://maven.apache.org/pom/4.0.0" xmlns:xsi="http://www.w3.org/2001/xmlschema-instance"
xsi:schemalocation="http://maven.apache.org/pom/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelversion>4.0.0</modelversion>
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>3.2.5</version>
<relativepath/> <!-- lookup parent from repository -->
</parent>
<groupid>com.zzc</groupid>
<artifactid>spring-boot-03-kafka-base</artifactid>
<version>0.0.1-snapshot</version>
<name>spring-boot-03-kafka-base</name>
<description>spring-boot-03-kafka-base</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-json</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.kafka</groupid>
<artifactid>spring-kafka</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-devtools</artifactid>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<optional>true</optional>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-test</artifactid>
<scope>test</scope>
</dependency>
<dependency>
<groupid>org.springframework.kafka</groupid>
<artifactid>spring-kafka-test</artifactid>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-maven-plugin</artifactid>
<configuration>
<excludes>
<exclude>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>先执行测试文件,生成125个消息到batchtopic的主题中
启动服务,发现一条消息也没有消费到
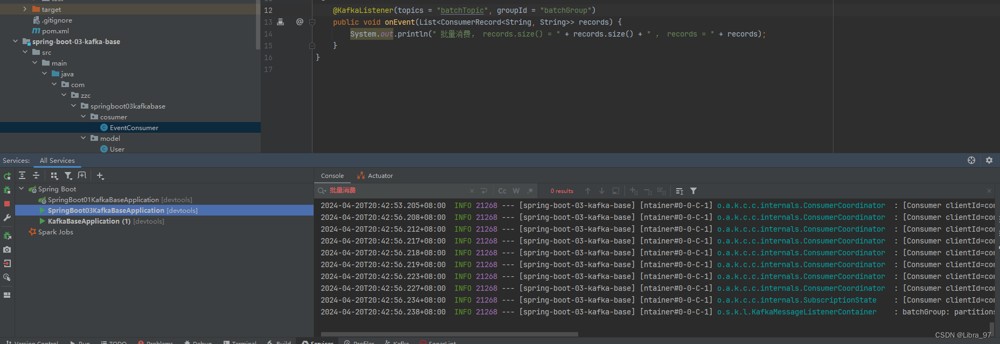
这个问题之前也遇到过,因为默认是最后一个偏移量+1开始消费的。
此时我们需要先在配置文件中将消费消息配置成从最早消息开始消费
consumer:
# 设置批量最多消费多少条消息
max-poll-records: 20
auto-offset-reset: earliest修改groupid,因为之前已经使用这个groupid消费过次一次了 所以要换一个groupid
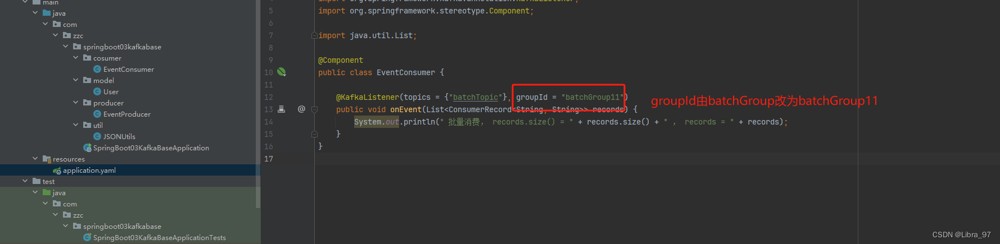
重启服务,成功消费到消息。每次最多消费20条,总共125条消息都消费到了。
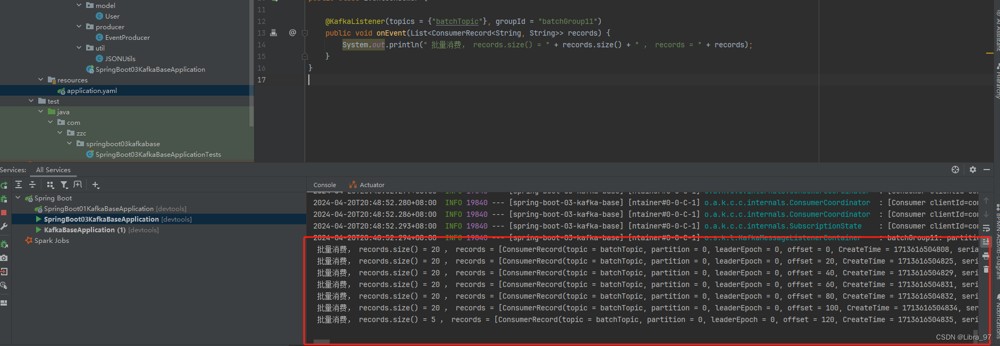
4.15 消费消息拦截器
在消息消费之前,我们可以通过配置拦截器对消息进行拦截,在消息被实际处理之前对其进行一些操作,例如记录日志、修改消息内容或执行一些安全检查等;
4.15.1 创建新模块spring-boot-04-kafka-base,依赖还是springboot、lombok、kafka这三个
4.15.2 主文件中添加代码
package com.zzc;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.applicationcontext;
import org.springframework.context.configurableapplicationcontext;
import org.springframework.kafka.config.kafkalistenercontainerfactory;
import org.springframework.kafka.core.consumerfactory;
import java.util.map;
@springbootapplication
public class springboot04kafkabaseapplication {
public static void main(string[] args) {
applicationcontext context = springapplication.run(springboot04kafkabaseapplication.class, args);
map<string, consumerfactory> beansoftype = context.getbeansoftype(consumerfactory.class);
beansoftype.foreach((k, v) -> {
system.out.println(k + " -- " + v);
});
map<string, kafkalistenercontainerfactory> beansoftype2 = context.getbeansoftype(kafkalistenercontainerfactory.class);
beansoftype2.foreach((k, v) -> {
system.out.println(k + " -- " + v);
});
}
}启动服务类,发现容器中默认有kafkaconsumerfactory和kafkalistenercontainerfactory类

我们需要使用自己的kafkaconsumerfactory和kafkalistenercontainerfactory,因为我们需要加上拦截器
4.15.2 创建拦截器customconsumerinterceptor
package com.zzc.interceptor;
import org.apache.kafka.clients.consumer.consumerinterceptor;
import org.apache.kafka.clients.consumer.consumerrecords;
import org.apache.kafka.clients.consumer.offsetandmetadata;
import org.apache.kafka.common.topicpartition;
import java.util.map;
public class customconsumerinterceptor implements consumerinterceptor<string, string > {
/**
* 在消费消息之前执行
* @param consumerrecords
* @return
*/
@override
public consumerrecords<string, string> onconsume(consumerrecords<string, string> consumerrecords) {
system.out.println("onconsumer方法执行:" + consumerrecords);
return consumerrecords;
}
/**
* 消息拿到之后,提交offset之前执行该方法
* @param offsets
*/
@override
public void oncommit(map<topicpartition, offsetandmetadata> offsets) {
system.out.println("oncommit方法执行:" + offsets);
}
@override
public void close() {
}
@override
public void configure(map<string, ?> map) {
}
}4.15.3 创建配置类
package com.zzc.config;
import com.zzc.interceptor.customconsumerinterceptor;
import org.apache.kafka.clients.consumer.consumerconfig;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.kafka.config.concurrentkafkalistenercontainerfactory;
import org.springframework.kafka.config.kafkalistenercontainerfactory;
import org.springframework.kafka.core.consumerfactory;
import org.springframework.kafka.core.defaultkafkaconsumerfactory;
import java.util.hashmap;
import java.util.map;
@configuration
public class kafkaconfig {
@value("${spring.kafka.bootstrap-servers}")
private string bootstrapservers;
@value("${spring.kafka.consumer.value-deserializer}")
private string valuedeserializer;
@value("${spring.kafka.consumer.key-deserializer}")
private string keydeserializer;
public map<string, object> consumerconfigs(){
hashmap<string, object> consumer = new hashmap<>();
consumer.put(consumerconfig.bootstrap_servers_config,bootstrapservers);
consumer.put(consumerconfig.key_deserializer_class_config,keydeserializer);
consumer.put(consumerconfig.value_deserializer_class_config, valuedeserializer);
// 添加一个消费拦截器
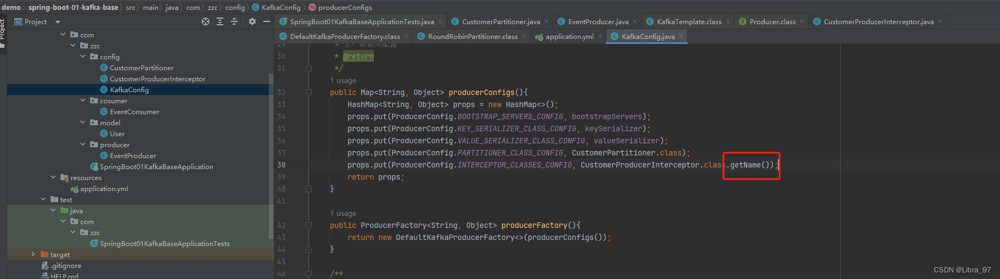
consumer.put(consumerconfig.interceptor_classes_config, customconsumerinterceptor.class.getname());
return consumer;
}
/**
* 消费者创建工厂
* @return
*/
@bean
public consumerfactory<string, string> ourconsumerfactory(){
return new defaultkafkaconsumerfactory<>(consumerconfigs());
}
/**
* 监听器容器工厂
* @param ourconsumerfactory
* @return
*/
@bean
public kafkalistenercontainerfactory ourkafkalistenercontainerfactory(consumerfactory ourconsumerfactory){
concurrentkafkalistenercontainerfactory<string, string> listenercontainerfactory = new concurrentkafkalistenercontainerfactory<>();
listenercontainerfactory.setconsumerfactory(ourconsumerfactory);
return listenercontainerfactory;
}
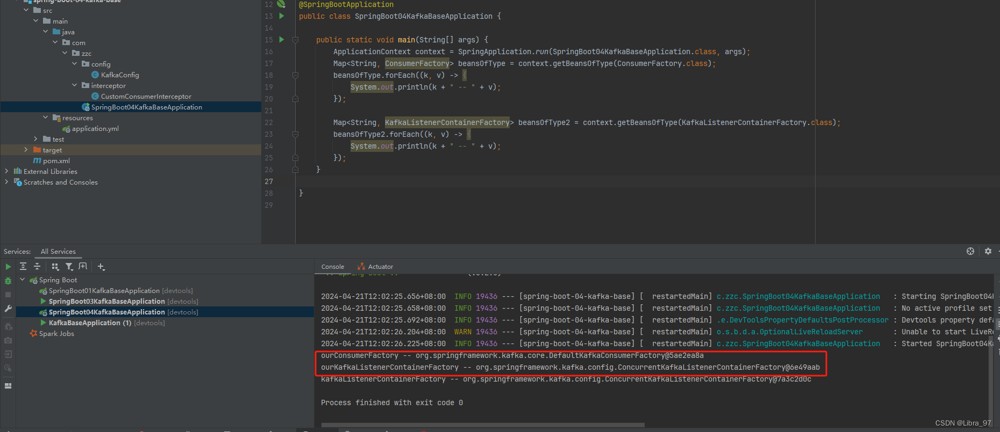
}4.15.4 测试spring容器默认的和自定义的消费者创建工厂和监听器容器工厂
重启服务,测试容器中用的已经是我们自己创建的消费者创建工厂和监听器容器工厂了
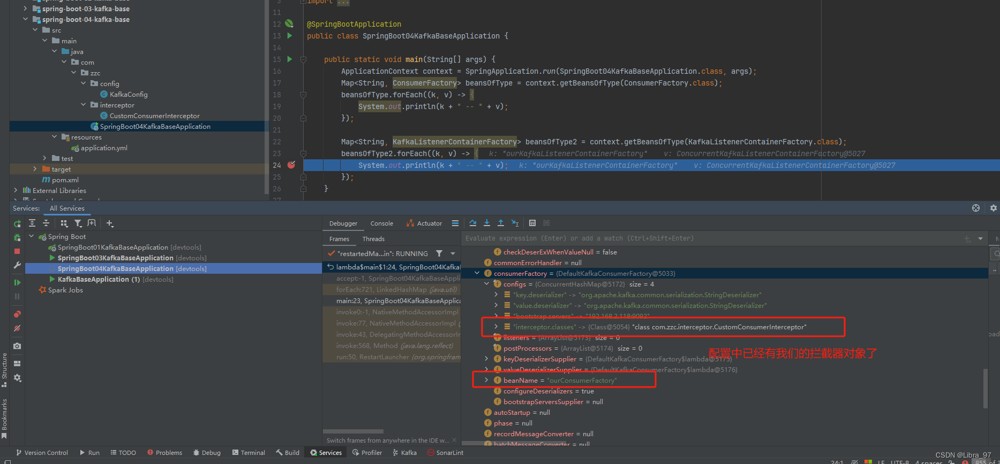
我们自定义的监听器容器工厂的配置中可以看到有我们创建的拦截器对象
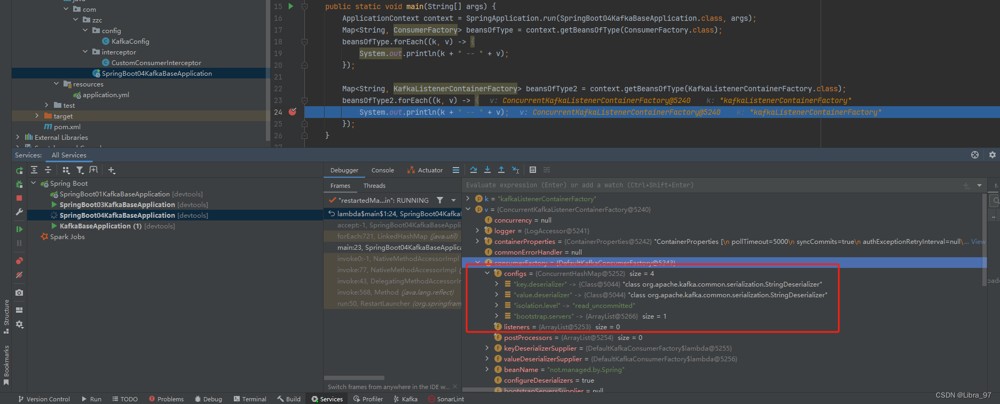
spring的默认监听器工厂对象的配置中就没有我们创建的拦截器对象
4.15.5 消费消息
创建消费者对象,kafkalistener注解加上containerfactory参数
package com.zzc.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class eventconsumer {
@kafkalistener(topics = {"intertopic"}, groupid = "intergroup", containerfactory = "ourkafkalistenercontainerfactory")
public void onevent(consumerrecord<string, string> records) {
system.out.println(" 消费消息, records = " + records);
}
}创建生产者对象
package com.zzc.producer;
import com.zzc.model.user;
import com.zzc.util.jsonutils;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
import java.util.date;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent() {
user user = user.builder().id(1023).phone("13239407234").birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("intertopic", "k", userjson);
}
}测试代码
@resource
private eventproducer eventproducer;
@test
public void test(){
eventproducer.sendevent();
}启动服务,再执行测试代码,成功打印出拦截器中的消息
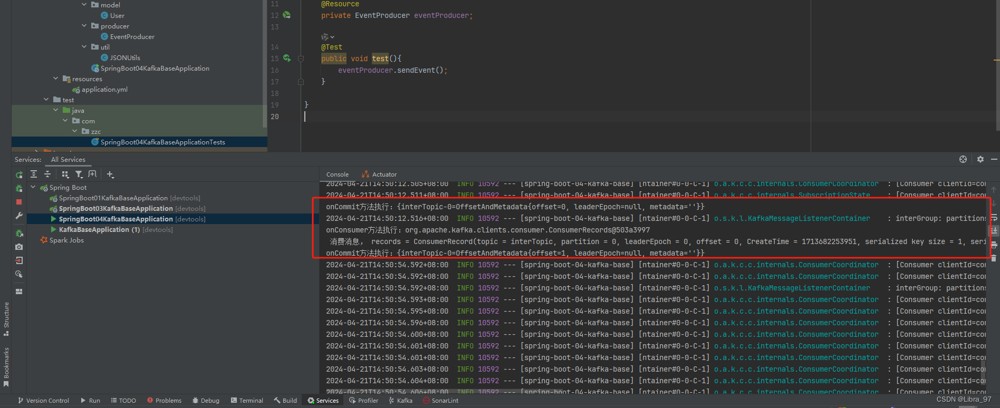
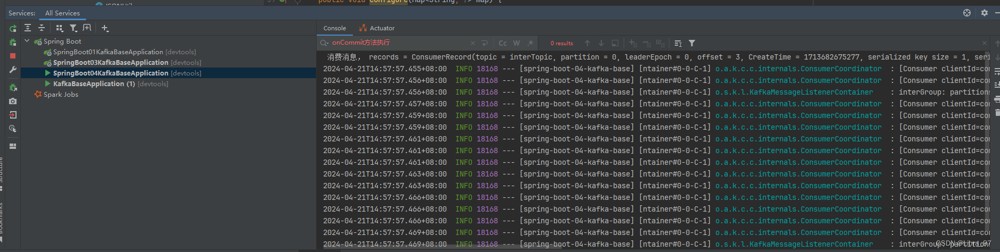
测试kafkalistener注解中不加containerfactory参数是否会打印拦截器的消息
@component
public class eventconsumer {
// @kafkalistener(topics = {"intertopic"}, groupid = "intergroup", containerfactory = "ourkafkalistenercontainerfactory")
@kafkalistener(topics = {"intertopic"}, groupid = "intergroup", )
public void onevent(consumerrecord<string, string> records) {
system.out.println(" 消费消息, records = " + records);
}
}重启服务,再次执行测试代码,发现并没有打印出拦截器的消息
4.16 消息转发
消息转发就是应用 a 从 topica 接收到消息,经过处理后转发到 topicb ,再由应用 b 监听接收该消息,即一个应用处理完成后将该消息转发至其他应用处理,这在实际开发中,是可能存在这样的需求的;
创建一个新模块spring-boot-05-kafka-base,结构如下
consumer代码
package com.zzc.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.messaging.handler.annotation.sendto;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class eventconsumer {
@kafkalistener(topics = {"topica"}, groupid = "group1")
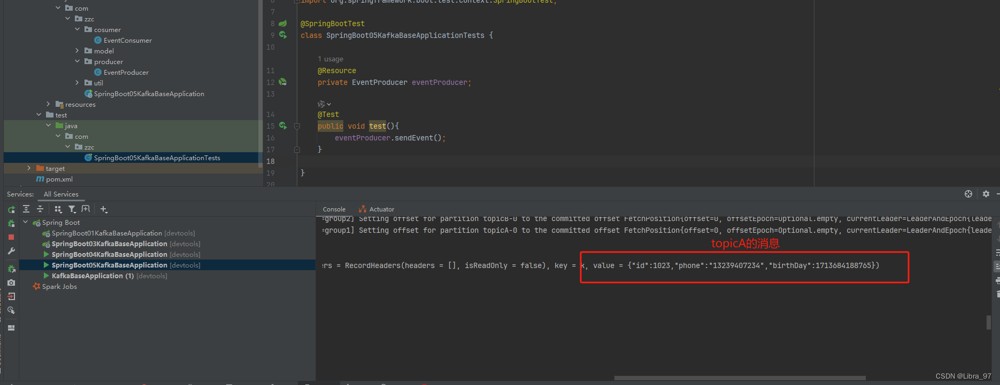
@sendto("topicb") // 转发消息给topicb
public string onevent(consumerrecord<string, string> record) {
system.out.println(" 消费消息, record = " + record);
return record.value() + "forward message";
}
@kafkalistener(topics = {"topicb"}, groupid = "group2")
public void onevent2(list<consumerrecord<string, string>> records) {
system.out.println(" 消费消息, record = " + records);
}
}producer代码
package com.zzc.producer;
import com.zzc.model.user;
import com.zzc.util.jsonutils;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
import java.util.date;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent() {
user user = user.builder().id(1023).phone("13239407234").birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("topica", "k", userjson);
}
}启动服务,执行测试代码
4.17 消息消费的分区策略
- kafka 消费消息时的分区策略:是指 kafka 主题 topic 中哪些分区应该由哪些消费者来消费;
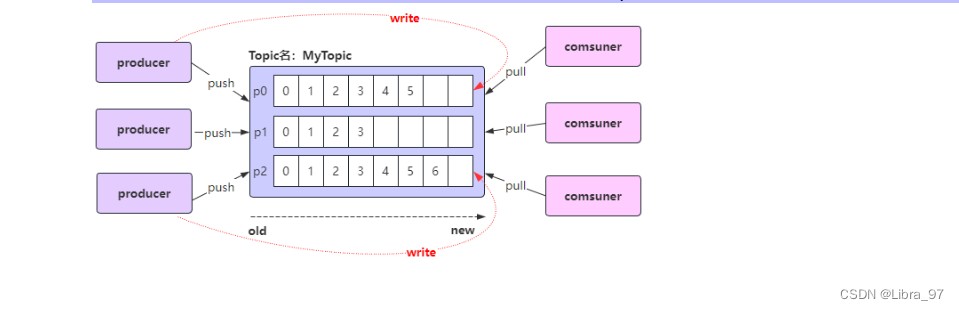
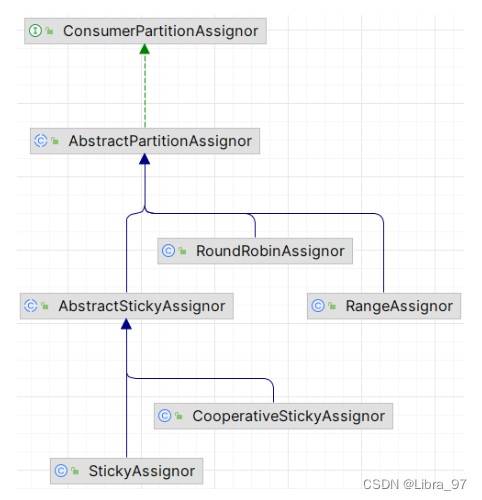
- kafka 有多种分区分配策略,默认的分区分配策略是rangeassignor ,除了 rangeassignor 策略外, kafka 还有其他分区分配策略:
- roundrobinassignor
- stickyassignor
- cooperativestickyassignor ,
- 这些策略各有特点,可以根据实际的应用场景和需求来选择适合的分区分配策略;
4.17.1 rangeassignor 策略
创建新模块spring-boot-06-kafka-base
配置类kafkaconfig
package com.zzc.config;
import org.apache.kafka.clients.admin.newtopic;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
@configuration
public class kafkaconfig {
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
return new newtopic("mytopic", 10, (short) 1);
}
}消费者类eventconsumer
package com.zzc.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class eventconsumer {
// concurrency 消费者数量
@kafkalistener(topics = {"mytopic"}, groupid = "mygroup", concurrency = "3")
public void onevent(consumerrecord<string, string> records) {
system.out.println(" 消费消息, records = " + records);
}
}生产者类
package com.zzc.producer;
import com.zzc.model.user;
import com.zzc.util.jsonutils;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
import java.util.date;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent() {
for (int i = 0; i < 100; i++) {
user user = user.builder().id(i).phone("13239407234" + i).birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("mytopic", "k" + i, userjson);
}
}
}测试代码
package com.zzc;
import com.zzc.producer.eventproducer;
import jakarta.annotation.resource;
import org.junit.jupiter.api.test;
import org.springframework.boot.test.context.springboottest;
@springboottest
class springboot06kafkabaseapplicationtests {
@resource
private eventproducer eventproducer;
@test
public void test(){
eventproducer.sendevent();
}
}配置文件
spring:
application:
name: spring-boot-06-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.stringdeserializer
value-deserializer: org.apache.kafka.common.serialization.stringdeserializer
auto-offset-reset: earliest先执行测试代码,生产100个消息发送到10个分区中
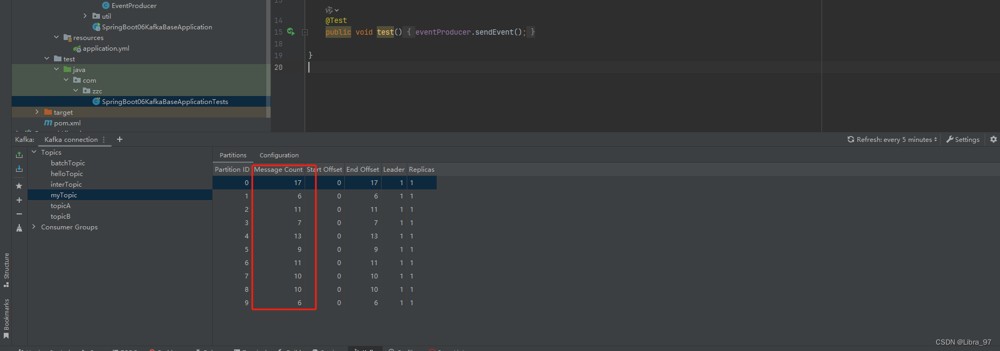
启动服务,进行消费,打印出100个消息

我们来看一下最小的线程id38是否消费4个分区
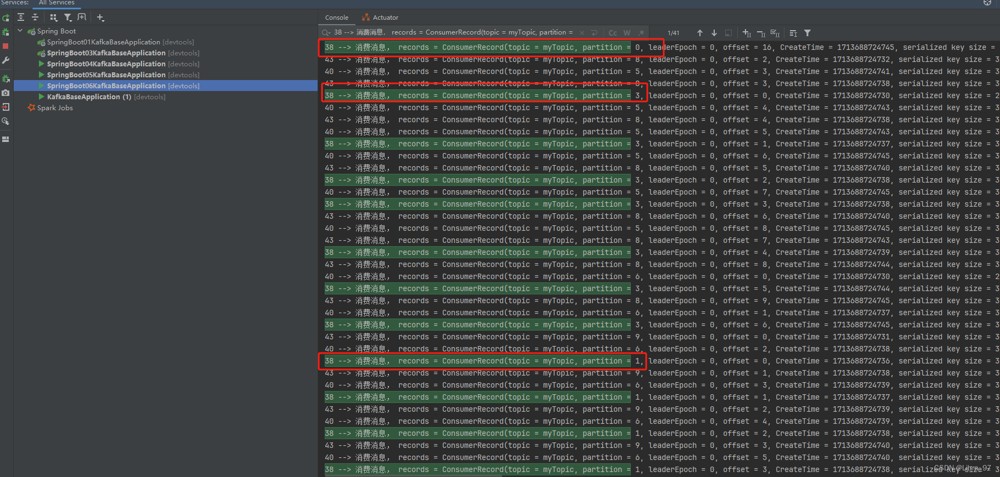
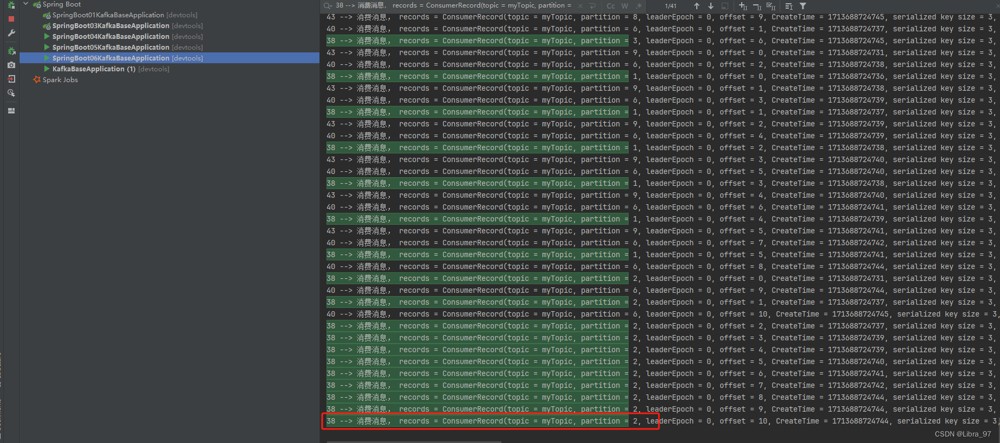
线程id38确实是消费了0、1、2、3号共4个分区。其他两个线程各消费3个分区
4.17.2 roundrobinassignor策略
配置文件中无法修改策略,所以需要在配置类中设置
配置类代码
package com.zzc.config;
import org.apache.kafka.clients.admin.newtopic;
import org.apache.kafka.clients.consumer.consumerconfig;
import org.apache.kafka.clients.consumer.roundrobinassignor;
import org.apache.kafka.clients.producer.roundrobinpartitioner;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.kafka.config.concurrentkafkalistenercontainerfactory;
import org.springframework.kafka.config.kafkalistenercontainerfactory;
import org.springframework.kafka.core.consumerfactory;
import org.springframework.kafka.core.defaultkafkaconsumerfactory;
import java.util.hashmap;
import java.util.map;
@configuration
public class kafkaconfig {
@value("${spring.kafka.bootstrap-servers}")
private string bootstrapservers;
@value("${spring.kafka.consumer.value-deserializer}")
private string valuedeserializer;
@value("${spring.kafka.consumer.key-deserializer}")
private string keydeserializer;
@value("${spring.kafka.consumer.auto-offset-reset}")
private string autooffsetreset;
public map<string, object> consumerconfigs(){
hashmap<string, object> consumer = new hashmap<>();
consumer.put(consumerconfig.bootstrap_servers_config,bootstrapservers);
consumer.put(consumerconfig.key_deserializer_class_config,keydeserializer);
consumer.put(consumerconfig.value_deserializer_class_config, valuedeserializer);
consumer.put(consumerconfig.auto_offset_reset_config, autooffsetreset);
// 设置消费者策略为轮询模式
consumer.put(consumerconfig.partition_assignment_strategy_config, roundrobinassignor.class.getname());
return consumer;
}
// 创建一个名为hellotopic的topic并设置分区数为5,分区副本数为1
@bean
public newtopic newtopic(){
return new newtopic("mytopic", 10, (short) 1);
}
/**
* 消费者创建工厂
* @return
*/
@bean
public consumerfactory<string, string> ourconsumerfactory(){
return new defaultkafkaconsumerfactory<>(consumerconfigs());
}
/**
* 监听器容器工厂
* @param ourconsumerfactory
* @return
*/
@bean
public kafkalistenercontainerfactory ourkafkalistenercontainerfactory(consumerfactory ourconsumerfactory){
concurrentkafkalistenercontainerfactory<string, string> listenercontainerfactory = new concurrentkafkalistenercontainerfactory<>();
listenercontainerfactory.setconsumerfactory(ourconsumerfactory);
return listenercontainerfactory;
}
}消费者代码中设置为自定义监听器容器创建工厂
package com.zzc.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
import java.util.list;
@component
public class eventconsumer {
// concurrency 设置消费者数量 containerfactory 设置监听器容器工厂
@kafkalistener(topics = {"mytopic"}, groupid = "mygroup4", concurrency = "3", containerfactory = "ourkafkalistenercontainerfactory")
public void onevent(consumerrecord<string, string> records) {
system.out.println(thread.currentthread().getid() + " --> 消费消息, records = " + records);
}
}执行测试代码,发现线程id39消费的分区变成0、3、6、9号分区了
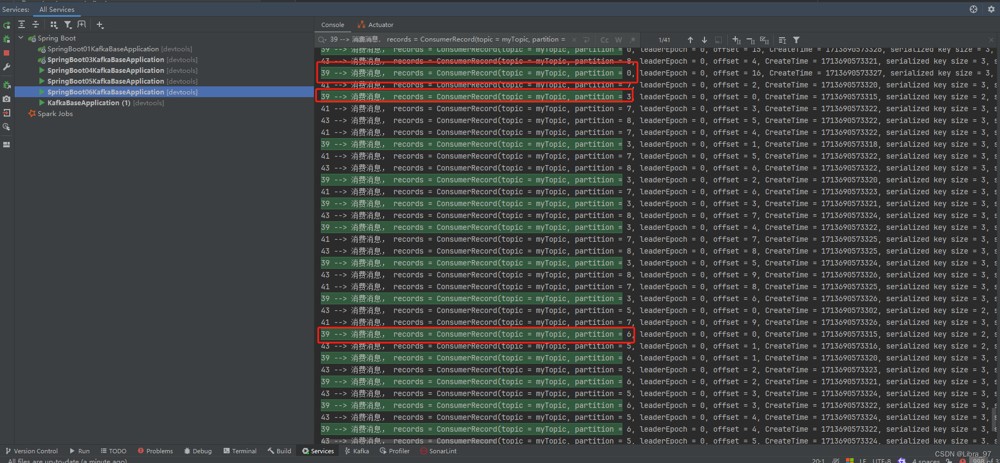
采用 roundrobinassignor 策略进行测试,得到的结果如下:
39 : 0 , 3 , 6 , 9
41 : 1 , 4 , 7
43 : 2 , 5 , 8
4.17.3 stickyassignor 消费分区策略
- 尽可能保持消费者与分区之间的分配关系不变,即使消费组的消费者成员发生变化,减少不必要的分区重分配;
- 尽量保持现有的分区分配不变,仅对新加入的消费者或离开的消费者进行分区调整。这样,大多数消费者可以
继续消费它们之前消费的分区,只有少数消费者需要处理额外的分区;所以叫“粘性”分配;
4.17.4 cooperativestickyassignor 消费分区策略
- 与 stickyassignor 类似,但增加了对协作式重新平衡的支持,即消费者可以在它离开消费者组之前通知协调
器,以便协调器可以预先计划分区迁移,而不是在消费者突然离开时立即进行分区重分配;
4.18 kafka 事件 ( 消息、数据 ) 的存储
kafka的所有事件(消息、数据)都存储在/tmp/kafka-logs目录中,可通过log.dirs=/tmp/kafka-logs配置
kafka的所有事件(消息、数据)都是以日志文件的方式来保存
kafka一般都是海量的消息数据,为了避免日志文件过大,日志文件被存放在多个日志目录下,日志目录的命名规则为:<topic_name>-<partiton_id>
比如创建一个名为 firsttopic 的 topic ,其中有 3 个 partition ,那么在 kafka 的数据目录( /tmp/kafka-
log )中就有 3 个目录, firsttopic-0 、 firsttopic-1 、 firsttopic-2 ;
进入mytopic-0中

查看日志信息

- 00000000000000000000.index 消息索引文件
- 00000000000000000000.log 消息数据文件
- 00000000000000000000.timeindex 消息的时间戳索引文件
- 00000000000000000006.snapshot 快照文件,生产者发生故障或重启时能够恢复并继续之前的操作
- leader-epoch-checkpoint 记录每个分区当前领导者的 epoch 以及领导者开始写入消息时的起始偏移量
- partition.metadata 存储关于特定分区的元数据( metadata )信息
每次消费一个消息并且提交以后,会保存当前消费到的最近的一个 offset ; 在 kafka 中,有一个 __consumer_offsets 的 topic , 消费者消费提交的 offset 信息会写入到 该 topic 中, __consumer_offsets 保存了每个 consumer group 某一时刻提交的 offset 信息 , __consumer_offsets 默认有 50 个分区; consumer_group 保存在哪个分区中的计算公式: math.abs(“groupid”.hashcode())%groupmetadatatopicpartitioncount ;
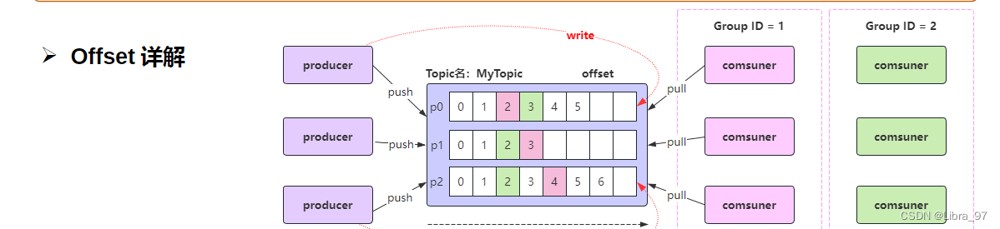
4.19 offset详解
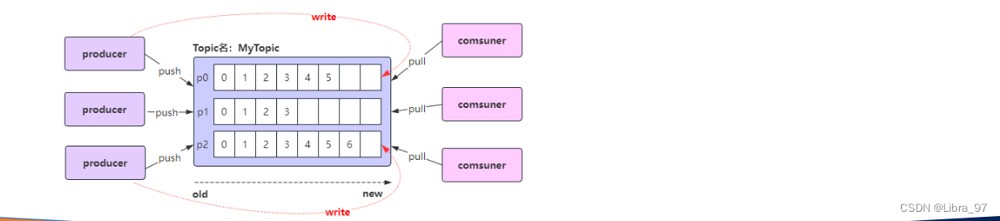
4.19.1 生产者offset
生产者发送一条消息到 kafka 的 broker 的某个 topic 下某个 partition 中;
kafka 内部会为每条消息分配一个唯一的 offset ,该 offset 就是该消息在 partition 中的位置
创建spring-boot-07-kafka-base模块
消费者代码
package com.zzc.cosumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.stereotype.component;
@component
public class eventconsumer {
@kafkalistener(topics = {"offsettopic"}, groupid = "offsetgroup")
public void onevent(consumerrecord<string, string> records) {
system.out.println(thread.currentthread().getid() + " --> 消费消息, records = " + records);
}
}生产者代码
package com.zzc.producer;
import com.zzc.model.user;
import com.zzc.util.jsonutils;
import jakarta.annotation.resource;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.stereotype.component;
import java.util.date;
@component
public class eventproducer {
@resource
private kafkatemplate<string, string> kafkatemplate;
public void sendevent() {
for (int i = 0; i < 2; i++) {
user user = user.builder().id(i).phone("13239407234" + i).birthday(new date()).build();
string userjson = jsonutils.tojson(user);
kafkatemplate.send("offsettopic", "k" + i, userjson);
}
}
}配置文件
spring:
application:
name: spring-boot-07-kafka-base
kafka:
bootstrap-servers: 192.168.2.118:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.stringdeserializer
value-deserializer: org.apache.kafka.common.serialization.stringdeserializer测试代码
package com.zzc;
import com.zzc.producer.eventproducer;
import jakarta.annotation.resource;
import org.junit.jupiter.api.test;
import org.springframework.boot.test.context.springboottest;
@springboottest
class springboot07kafkabaseapplicationtests {
@resource
private eventproducer eventproducer;
@test
public void test(){
eventproducer.sendevent();
}
}执行测试代码
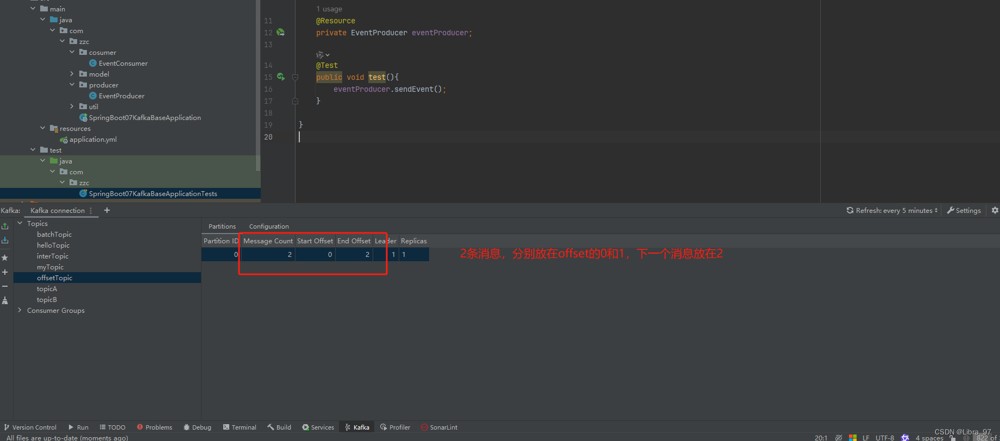
4.19.2 消费者offset
- 每个消费者组启动开始监听消息,默认从消息的最新的位置开始监听消息,即把最新的位置作为消费者
offset ;- 分区中还没有发送消息,则最新的位置就是0
- 分区中已经发送过消息,则最新的位置就是生产者offset的下一个位置
- 消费者消费消息后,如果不提交确认( ack ),则 offset 不更新,提交了才更新;
- 命令行命令: ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group 消费者组名 --describe
4.19.2.1 验证分区中已经发送过消息的情况
启动服务,监听器并没有消费到消息
使用命令看一下offsetgroup的offset是在哪

我们再发两条消息试试,先把服务停了,执行测试代码发送消息
再次执行命令 查看offsetgroup的offset是在哪

我们现在启动服务,能够消费到消息了
消费完消息,再次执行命令,发现current-offset已经变成4了,也没有消息可读了

4.19.2.2 验证分区中还没有发过消息的情况
我们把offsettopic删除,然后重启服务,再执行命令
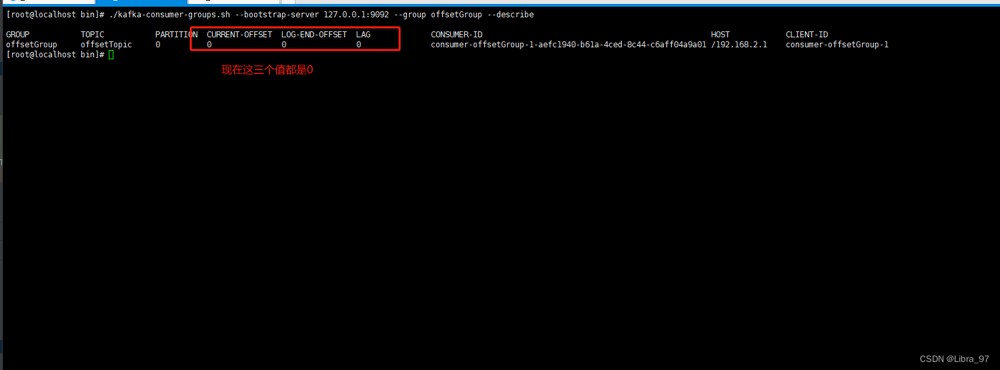
然后停止服务,执行测试代码 发送消息,在执行命令
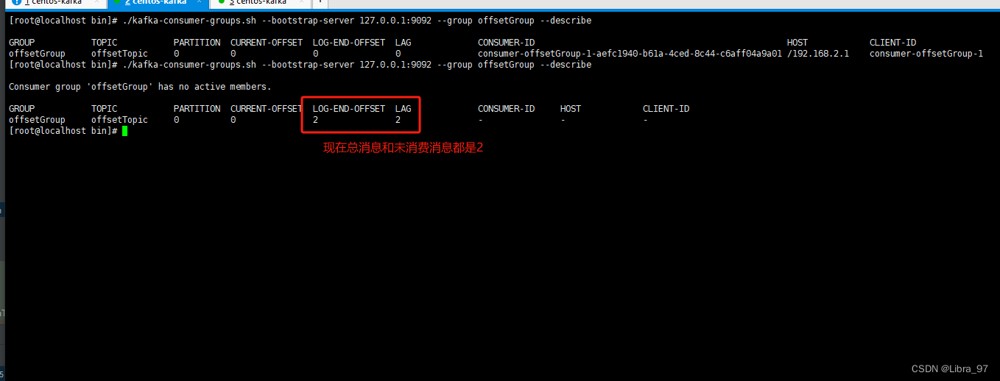
我们再启动服务,就能够消费这2个消息
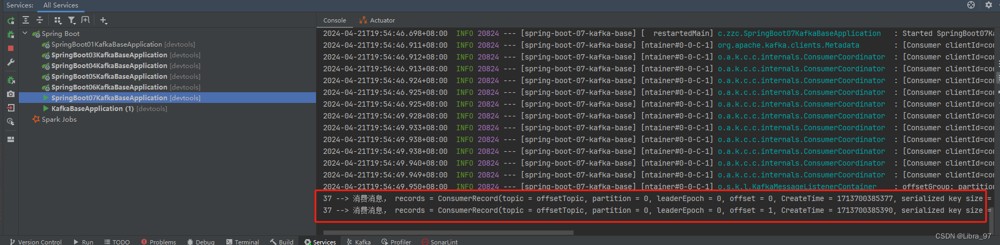
4.19.3 offset总结
消费者从什么位置开始消费,就看消费者的 offset 是多少,消费者 offset 是多少,它启动后,可以通过上面
的命令查看;
到此这篇关于springboot集成kafka开发的文章就介绍到这了,更多相关springboot kafka开发内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论