前言
在 java 里,getbytes() 是 string 类的一个实例方法,其主要作用是将字符串按照指定的字符编码方案转换为字节数组。
一、常见重载形式
1.getbytes():使用平台默认的字符编码将字符串转换为字节数组。
2.getbytes(charset charset):使用指定的 charset 对象所表示的字符编码将字符串转换为字节数组。
3.getbytes(string charsetname):使用指定的字符编码名称将字符串转换为字节数组,如果指定的字符编码不支持,会抛出 unsupportedencodingexception 异常。
二、示例代码
import java.io.unsupportedencodingexception;
import java.nio.charset.standardcharsets;
public class getbytesexample {
public static void main(string[] args) {
string str = "你好,世界!";
// 使用平台默认编码
byte[] bytesdefault = str.getbytes();
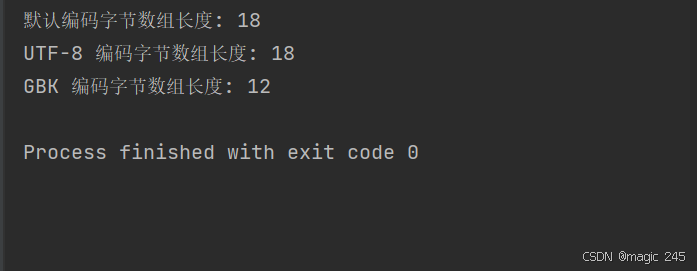
system.out.println("默认编码字节数组长度: " + bytesdefault.length);
// 使用指定的 charset 对象
byte[] bytesutf8 = str.getbytes(standardcharsets.utf_8);
system.out.println("utf-8 编码字节数组长度: " + bytesutf8.length);
// 使用指定的字符编码名称
try {
byte[] bytesgbk = str.getbytes("gbk");
system.out.println("gbk 编码字节数组长度: " + bytesgbk.length);
} catch (unsupportedencodingexception e) {
e.printstacktrace();
}
}
}运行结果:
三、getbytes(charset charset)和getbytes(string charsetname)的区别
在 java 中,getbytes(charset charset) 和 getbytes(string charsetname) 都用于将字符串按照指定的字符编码转换为字节数组,但它们存在一些区别,下面从多个方面进行详细分析:
1. 参数类型
getbytes(charset charset):该方法接受一个 charset 对象作为参数。charset 是 java 中用于表示字符编码的类,它提供了丰富的方法和属性来处理字符编码相关的操作。例如,standardcharsets.utf_8 就是一个 charset 对象,代表 utf - 8 字符编码。
getbytes(string charsetname):此方法接受一个字符串类型的参数,该字符串表示字符编码的名称,如 "utf-8"、"gbk" 等。
2. 异常处理
getbytes(charset charset):该方法不会抛出 unsupportedencodingexception 异常。因为在使用 charset 对象时,通常是从 standardcharsets 类或者通过 charset 类的静态方法获取有效的 charset 对象,这些对象所代表的字符编码是 java 虚拟机所支持的,所以不会出现不支持的编码问题。
getbytes(string charsetname):如果指定的字符编码名称在当前 java 虚拟机中不被支持,会抛出 unsupportedencodingexception 异常。因此,在使用该方法时需要进行异常处理。
3. 代码可读性和安全性
getbytes(charset charset):使用 charset 对象可以提高代码的可读性和安全性。因为 charset 对象是类型安全的,编译器可以在编译时检查参数的类型,避免传递无效的编码名称。而且,standardcharsets 类提供了一些常用的字符编码常量,使用这些常量可以使代码更具可读性。
getbytes(string charsetname):使用字符串表示字符编码名称,可能会因为拼写错误或者使用了不支持的编码名称而导致运行时异常。同时,由于字符串是动态的,编译器无法在编译时检查编码名称的有效性,代码的安全性相对较低。
4. 性能
从性能角度来看,两者的差异通常可以忽略不计。不过,getbytes(charset charset) 方法由于直接使用 charset 对象,避免了对编码名称的解析过程,理论上可能会稍微快一点。
示例代码对比
import java.io.unsupportedencodingexception;
import java.nio.charset.charset;
import java.nio.charset.standardcharsets;
public class getbytesdifference {
public static void main(string[] args) {
string str = "hello, world!";
// 使用 getbytes(charset charset)
charset utf8charset = standardcharsets.utf_8;
byte[] bytes1 = str.getbytes(utf8charset);
system.out.println("使用 getbytes(charset charset) 转换后的字节数组长度: " + bytes1.length);
// 使用 getbytes(string charsetname)
try {
byte[] bytes2 = str.getbytes("utf-8");
system.out.println("使用 getbytes(string charsetname) 转换后的字节数组长度: " + bytes2.length);
} catch (unsupportedencodingexception e) {
e.printstacktrace();
}
}
}在上述示例中,getbytes(charset charset) 方法直接使用 standardcharsets.utf_8 这个 charset 对象,而 getbytes(string charsetname) 方法使用字符串 "utf-8" 作为参数,并且需要进行异常处理。
综上所述,建议在实际开发中优先使用 getbytes(charset charset) 方法,以提高代码的可读性、安全性和性能。
附:javastring.getbytes()解决utf-8乱码
string str = “xxxxxxxxx”;
new string(str.getbytes("iso-8859-1"),"utf-8");注意:
有时候,为了让中文字符适应某些特殊要求(如httpheader要求其内容必须为iso8859-1编码),可能会通过将中文字符按照字节方式来编码的情况,如:
string s_iso88591 = newstring("中".getbytes("utf-8"),"iso8859-1"),这样得到的s_iso8859-1字符串实际是三个在iso8859-1中的字符,在将这些字符传递到目的地后,目的地程序再通过相反的方式strings_utf8 = newstring(s_iso88591.getbytes("iso8859-1"),"utf-8")来得到正确的中文汉字"中",这样就既保证了遵守协议规定、也支持中文。
总结
到此这篇关于java中的getbytes()方法使用的文章就介绍到这了,更多相关java中getbytes()方法内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论