一、使用ip2region离线获取
1、ip2region简介
目前支持其他语言的查询客户端,项目地址:https://github.com/lionsoul2014/ip2region
java版本的文档:https://github.com/lionsoul2014/ip2region/blob/master/binding/java/readme.md
ip2region是一个离线ip地址定位库和ip定位数据管理框架,10微秒级别的查询效率,提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。
2、导包
<dependency>
<groupid>org.lionsoul</groupid>
<artifactid>ip2region</artifactid>
<version>2.7.0</version>
</dependency>
3、下载xdb文件
下载地址:https://github.com/lionsoul2014/ip2region/blob/master/data/ip2region.xdb
4、java获取ip地址归属地
(1)完全基于文件的查询
基于文件的查询性能较差,并且searcher类是线程不安全的。并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
import org.lionsoul.ip2region.xdb.searcher;
import java.io.*;
import java.util.concurrent.timeunit;
public class searchertest {
public static void main(string[] args) throws ioexception {
// 1、创建 searcher 对象,需要指定 xdb文件的位置
string dbpath = "e:\\javacodes\\ip2region.xdb";
searcher searcher = null;
try {
searcher = searcher.newwithfileonly(dbpath);
} catch (ioexception e) {
system.out.printf("failed to create searcher with `%s`: %s\n", dbpath, e);
return;
}
// 2、查询
try {
string ip = "27.219.61.123";
long stime = system.nanotime();
string region = searcher.search(ip);
long cost = timeunit.nanoseconds.tomicros((long) (system.nanotime() - stime));
system.out.printf("{region: %s, iocount: %d, took: %d μs}\n", region, searcher.getiocount(), cost);
// {region: 中国|0|山东省|青岛市|联通, iocount: 2, took: 408 μs}
} catch (exception e) {
system.out.printf("failed to search", e);
}
// 3、关闭资源
searcher.close();
// 备注:并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
}
}
(2)缓存 vectorindex 索引
我们可以提前从 xdb 文件中加载出来 vectorindex 数据,然后全局缓存,每次创建 searcher 对象的时候使用全局的 vectorindex 缓存可以减少一次固定的 io 操作,从而加速查询,减少 io 压力。
import org.lionsoul.ip2region.xdb.searcher;
import java.io.*;
import java.util.concurrent.timeunit;
public class searchertest {
public static void main(string[] args) throws ioexception {
string dbpath = "e:\\javacodes\\springbootdemo\\src\\main\\resources\\ip2region.xdb";
// 1、从 dbpath 中预先加载 vectorindex 缓存,并且把这个得到的数据作为全局变量,后续反复使用。
byte[] vindex;
try {
vindex = searcher.loadvectorindexfromfile(dbpath);
} catch (exception e) {
system.out.printf("failed to load vector index from `%s`: %s\n", dbpath, e);
return;
}
// 2、使用全局的 vindex 创建带 vectorindex 缓存的查询对象。
searcher searcher;
try {
searcher = searcher.newwithvectorindex(dbpath, vindex);
} catch (exception e) {
system.out.printf("failed to create vectorindex cached searcher with `%s`: %s\n", dbpath, e);
return;
}
// 3、查询
try {
string ip = "27.219.61.123";
long stime = system.nanotime();
string region = searcher.search(ip);
long cost = timeunit.nanoseconds.tomicros((long) (system.nanotime() - stime));
system.out.printf("{region: %s, iocount: %d, took: %d μs}\n", region, searcher.getiocount(), cost);
// {region: 中国|0|山东省|青岛市|联通, iocount: 2, took: 408 μs}
} catch (exception e) {
system.out.printf("failed to search", e);
}
// 4、关闭资源
searcher.close();
// 备注:每个线程需要单独创建一个独立的 searcher 对象,但是都共享全局的制度 vindex 缓存。
}
}
(3)缓存整个 xdb 数据
我们也可以预先加载整个 ip2region.xdb 的数据到内存,然后基于这个数据创建查询对象来实现完全基于文件的查询,类似之前的 memory search。
并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
import org.lionsoul.ip2region.xdb.searcher;
import java.io.*;
import java.util.concurrent.timeunit;
public class searchertest {
public static void main(string[] args) {
string dbpath = "e:\\javacodes\\springbootdemo\\src\\main\\resources\\ip2region.xdb";
// 1、从 dbpath 加载整个 xdb 到内存。
byte[] cbuff;
try {
cbuff = searcher.loadcontentfromfile(dbpath);
} catch (exception e) {
system.out.printf("failed to load content from `%s`: %s\n", dbpath, e);
return;
}
// 2、使用上述的 cbuff 创建一个完全基于内存的查询对象。
searcher searcher;
try {
searcher = searcher.newwithbuffer(cbuff);
} catch (exception e) {
system.out.printf("failed to create content cached searcher: %s\n", e);
return;
}
// 3、查询
try {
string ip = "27.219.61.123";
long stime = system.nanotime();
string region = searcher.search(ip);
long cost = timeunit.nanoseconds.tomicros((long) (system.nanotime() - stime));
system.out.printf("{region: %s, iocount: %d, took: %d μs}\n", region, searcher.getiocount(), cost);
// {region: 中国|0|山东省|青岛市|联通, iocount: 0, took: 1044 μs}
} catch (exception e) {
system.out.printf("failed to search", e);
}
// 4、关闭资源 - 该 searcher 对象可以安全用于并发,等整个服务关闭的时候再关闭 searcher
// searcher.close();
// 备注:并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
}
}
二、使用第三方网站在线查询
在这里推荐两个查询网站,需要手动调取api
http://ip-api.com/json/27.219.61.123?lang=zh-cn
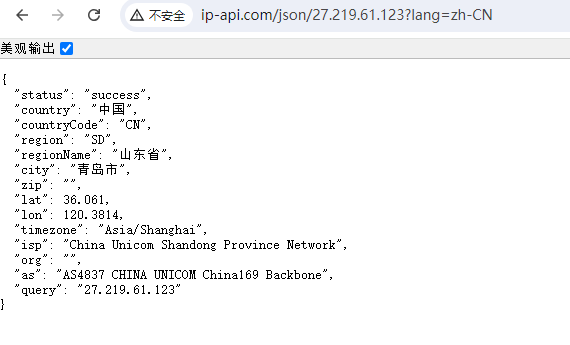
http://whois.pconline.com.cn/ipjson.jsp?ip=27.219.61.123&json=true

以上就是java根据ip地址实现归属地获取的详细内容,更多关于java ip地址获取归属地的资料请关注代码网其它相关文章!





发表评论