milvus是一款开源向量数据库,主要用于在大模型领域做向量查询的相关操作。milvus支持的语言比较多,支持python, java, go,node等开发语言。本文主要介绍如何使用java语言,采用springboot框架集成和调用milvus数据库。
本文示例使用的milvus版本是 v2.5.4,关于如何安装部署milvus向量数据,请参考上一篇文章:https://lowcode.blog.csdn.net/article/details/145552128
本文使用java sdk操作milvus实现数据的增删改查,需要先对milvus的基本概念有个初步的了解,便于对后面代码的更好理解。milvus更多帮助请参考官方文档:https://milvus.io/docs/overview.md
1、milvus基本概念
- 数据库database:与传统的数据库引擎mysql类似,你也可以在 milvus 中创建数据库,并为特定用户分配权限来管理它们。然后,此类用户有权管理数据库中的集合。一个 milvus 集群最多支持 64 个数据库。milvus 集群附带一个名为 'default' 的默认数据库。除非另有指定,否则将在 default 数据库中创建集合。
- 集合collection :在 milvus 中,你可以创建多个集合来管理数据,并将数据作为实体插入到集合中。collection 和 entity 类似于关系数据库中的 table 和 records。集合是具有固定列和变体行的二维表。每列表示一个字段,每行表示一个实体。collection 是具有固定列和变体行的二维表。每列表示一个字段,每行表示一个实体。需要schema来实现此类结构数据管理,要插入的每个实体都必须满足schema中定义的约束。
- 实体entity :在 milvus 中,entity 是指 collection 中共享相同 schema 的数据记录,一行中每个字段的数据构成一个 entity。因此,同一 collection 中的 entities 具有相同的属性(例如字段名称、数据类型和其他约束)。将 entity 插入 collection 时,要插入的 entity 只有在包含 schema 中定义的所有字段时才能成功添加。milvus 还支持动态字段,以保持 collection 的可扩展性。启用动态字段后,您可以将 schema 中未定义的字段插入到 collection 中。这些字段和值将作为键值对存储在名为 $meta 的保留字段中。
2、添加maven依赖
创建springboot工程后,在pom.xml文件里引入milvus的sdk
<dependency>
<groupid>io.milvus</groupid>
<artifactid>milvus-sdk-java</artifactid>
<version>2.5.4</version>
</dependency>本示例使用的是milvus2.5.4最新版本,java sdk 接口参考文档:https://milvus.io/api-reference/java/v2.5.x/about.md
注意使用sdk版本跟milvus版本的对应关系,milvus2.5.x版本建议使用sdk2.5.2以上版本,否则可能会出现一些诡异问题。
3、配置yml文件
#配置milvus向量数据库的ip和端口,后面构建milvusclient时需要
server: port: 8080 milvus: host: 192.168.3.17 port: 19530
4、创建milvusclient初始化类
import io.milvus.v2.client.connectconfig;
import io.milvus.v2.client.milvusclientv2;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
@configuration
public class milvusconfig {
@value("${milvus.host}")
private string host;
@value("${milvus.port}")
private integer port;
@bean
public milvusclientv2 milvusclientv2() {
string uri = "http://"+host+":"+port;
connectconfig connectconfig = connectconfig.builder()
.uri(uri)
.build();
return new milvusclientv2(connectconfig);
}
}5、创建操作向量库的seivce
import com.google.gson.gson;
import com.google.gson.jsonobject;
import com.yuncheng.milvus.testrecord;
import io.milvus.v2.client.milvusclientv2;
import io.milvus.v2.common.datatype;
import io.milvus.v2.common.indexparam;
import io.milvus.v2.service.collection.request.addfieldreq;
import io.milvus.v2.service.collection.request.createcollectionreq;
import io.milvus.v2.service.vector.request.getreq;
import io.milvus.v2.service.vector.request.insertreq;
import io.milvus.v2.service.vector.request.searchreq;
import io.milvus.v2.service.vector.request.data.floatvec;
import io.milvus.v2.service.vector.response.getresp;
import io.milvus.v2.service.vector.response.insertresp;
import io.milvus.v2.service.vector.response.searchresp;
import org.slf4j.logger;
import org.slf4j.loggerfactory;
import org.springframework.stereotype.component;
import java.util.arraylist;
import java.util.collections;
import java.util.list;
@component
public class milvusdemoservice {
private static final logger log = loggerfactory.getlogger(milvusdemoservice.class);
//类似于mysql中的表,定义一个名称为collection_01的集合
private static final string collection_name = "collection_01";
//为了测试验证方便,向量维度定义2
private static final int vector_dim = 2;
private final milvusclientv2 client;
public milvusdemoservice(milvusclientv2 client) {
this.client = client;
}
/**
* 创建一个collection
*/
public void createcollection() {
createcollectionreq.collectionschema schema = client.createschema();
schema.addfield(addfieldreq.builder()
.fieldname("id")
.datatype(datatype.varchar)
.isprimarykey(true)
.autoid(false)
.build());
schema.addfield(addfieldreq.builder()
.fieldname("title")
.datatype(datatype.varchar)
.maxlength(10000)
.build());
schema.addfield(addfieldreq.builder()
.fieldname("title_vector")
.datatype(datatype.floatvector)
.dimension(vector_dim)
.build());
indexparam indexparam = indexparam.builder()
.fieldname("title_vector")
.metrictype(indexparam.metrictype.cosine)
.build();
createcollectionreq createcollectionreq = createcollectionreq.builder()
.collectionname(collection_name)
.collectionschema(schema)
.indexparams(collections.singletonlist(indexparam))
.build();
client.createcollection(createcollectionreq);
}
/**
* 往collection中插入一条数据
*/
public void insertrecord(testrecord record) {
jsonobject vector = new jsonobject();
vector.addproperty("id", record.getid());
vector.addproperty("title", record.gettitle());
list<float> vectorlist = new arraylist<>();
//为了模拟测试,向量写死2个
vectorlist.add(2.8f);
vectorlist.add(3.9f);
gson gson = new gson();
vector.add("title_vector", gson.tojsontree(vectorlist));
insertreq insertreq = insertreq.builder()
.collectionname(collection_name)
.data(collections.singletonlist(vector))
.build();
insertresp resp = client.insert(insertreq);
}
/**
* 通过id获取记录
*/
public getresp getrecord(string id) {
getreq getreq = getreq.builder()
.collectionname(collection_name)
.ids(collections.singletonlist(id))
.build();
getresp resp = client.get(getreq);
return resp;
}
/**
* 按照向量检索,找到相似度最近的topk
*/
public list<list<searchresp.searchresult>> queryvector() {
searchresp searchr = client.search(searchreq.builder()
.collectionname(collection_name)
.data(collections.singletonlist(new floatvec(new float[]{0.9f, 2.1f})))
.topk(3)
.outputfields(collections.singletonlist("*"))
.build());
list<list<searchresp.searchresult>> searchresults = searchr.getsearchresults();
for (list<searchresp.searchresult> results : searchresults) {
for (searchresp.searchresult result : results) {
log.info("id="+(string)result.getid() + ",score="+result.getscore() + ",result="+result.getentity().tostring());
}
}
return searchresults;
}
}这里使用到的一个简单的pojo类
public class testrecord {
private string id;
private string title;
public string getid() {
return id;
}
public void setid(string id) {
this.id = id;
}
public string gettitle() {
return title;
}
public void settitle(string title) {
this.title = title;
}
}6、创建controller类
import com.yuncheng.milvus.service.milvusdemoservice;
import io.milvus.v2.service.vector.response.getresp;
import io.milvus.v2.service.vector.response.searchresp;
import org.slf4j.logger;
import org.slf4j.loggerfactory;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.web.bind.annotation.getmapping;
import org.springframework.web.bind.annotation.requestmapping;
import org.springframework.web.bind.annotation.requestparam;
import org.springframework.web.bind.annotation.restcontroller;
import java.io.ioexception;
import java.util.list;
@restcontroller
@requestmapping("/milvus")
public class milvuscontroller {
private static final logger log = loggerfactory.getlogger(milvuscontroller.class);
@autowired
private milvusdemoservice milvusdemoservice;
@getmapping("/createcollection")
public void createcollection() {
milvusdemoservice.createcollection();
}
@getmapping("/insertrecord")
public void insertrecord() throws ioexception {
testrecord record = new testrecord();
record.setid("5");
record.settitle("北京是中国的首都,人口有3000多万人");
milvusdemoservice.insertrecord(record);
}
@getmapping("/getrecord")
public getresp getrecord(@requestparam(name = "id") string id){
getresp resp = milvusdemoservice.getrecord(id);
log.info("resp = " + resp.getresults);
return resp;
}
@getmapping("/queryvector")
public list<list<searchresp.searchresult>> queryvector() {
list<list<searchresp.searchresult>> searchresults = milvusdemoservice.queryvector();
return searchresults;
}
}7、测试验证crud
确保milvus2.5.4向量数据库正常运行,然后启动springboot工程,进行对milvus向量数据库测试验证。
7.1、创建collection
http://localhost:8080/milvus/createcollection
执行后,登录milvus控制台webui查看
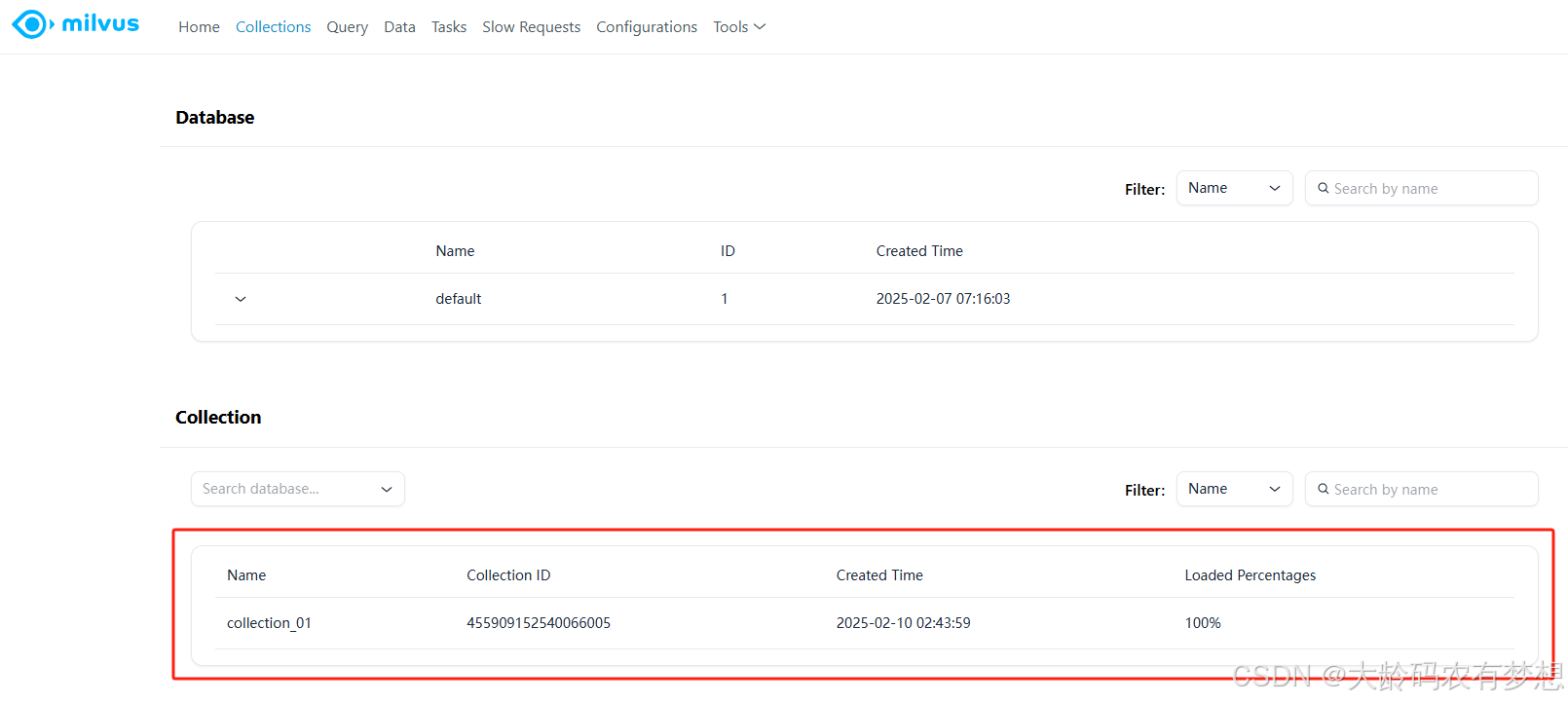
点击collection名称,查看详细的结构定义,类似于mysql中的表结构定义:
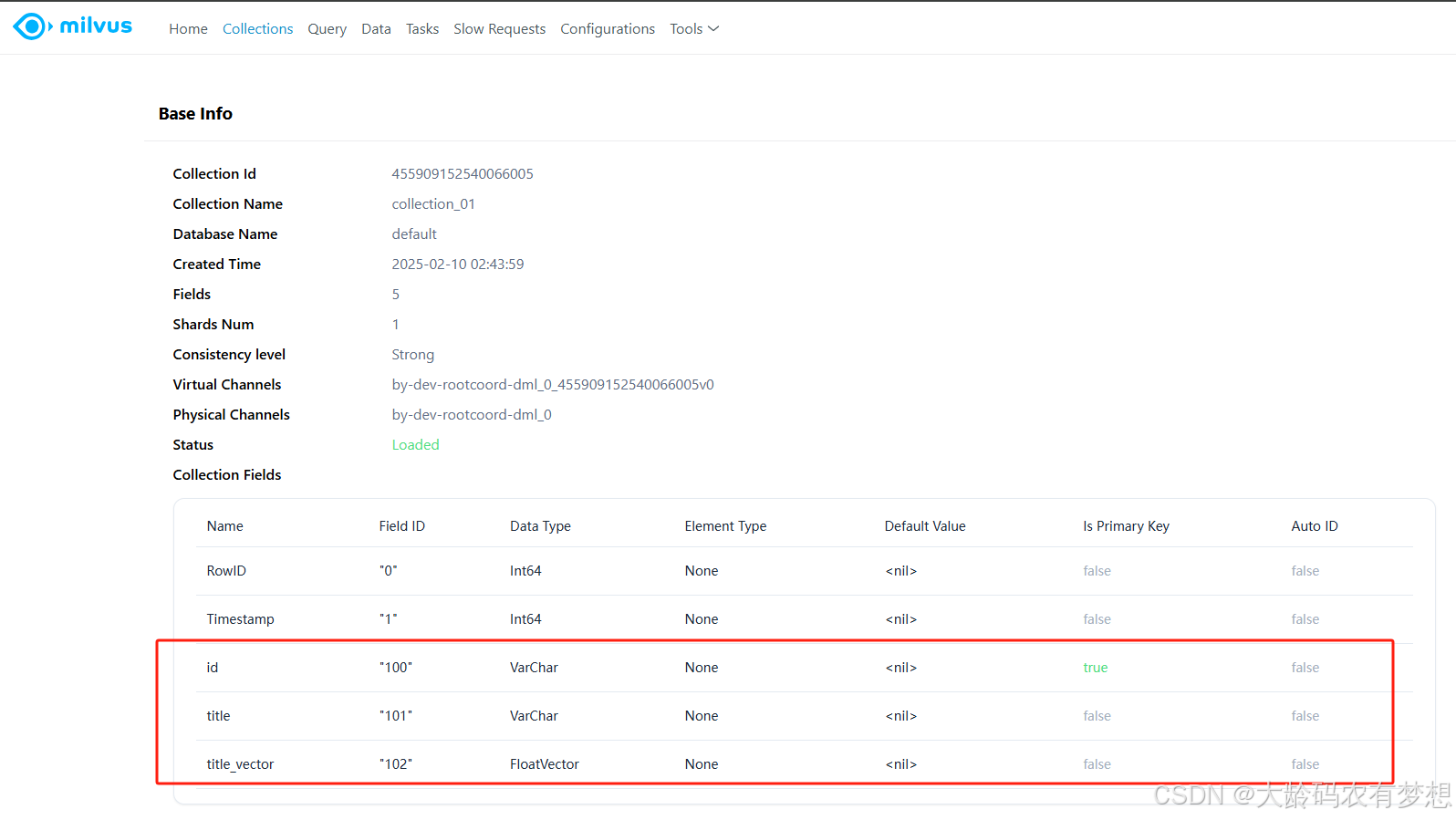
其中,id、title、title_vector字段是程序里定义的字段,另外rowid和timestamp字段是collection默认自带的字段。
7.2、插入数据
http://localhost:8080/milvus/insertrecord
为了测试方便,本示例写死了测试数据,往milvus中插入了5条数据
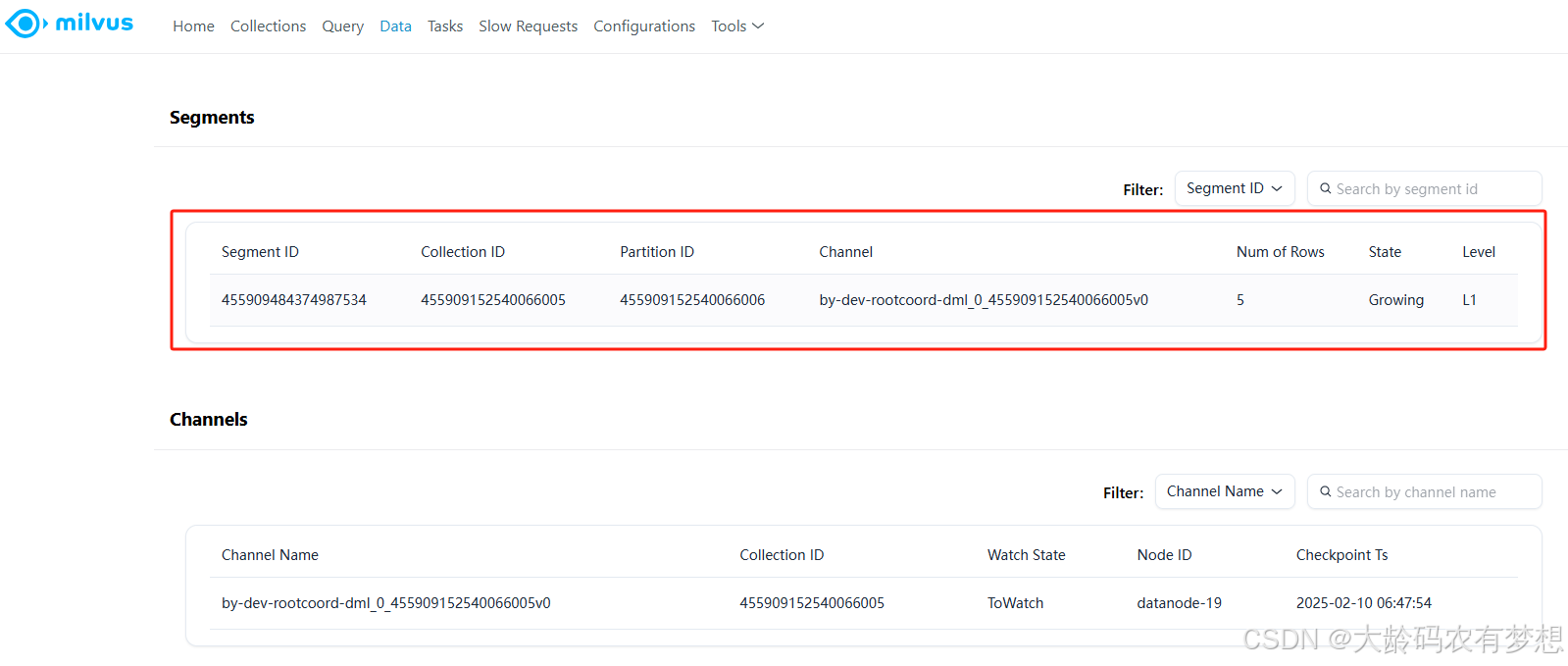
7.3、查询单条记录
http://localhost:8080/milvus/getrecord?id=2
返回json结果集
{
"getresults": [
{
"entity": {
"title_vector": [1, 2],
"id": "2",
"title": "张三是英国人,他喜欢吃中国火锅"
}
}
]
}7.4、按向量检索相似度
http://localhost:8080/milvus/queryvector
返回结果集:
[
[
{
"entity": {
"title_vector": [0.8, 1.9],
"id": "4",
"title": "王五是老师,她教学ai算法"
},
"score": 0.9999797,
"id": "4"
},
{
"entity": {
"title_vector": [1, 2],
"id": "2",
"title": "张三是英国人,他喜欢吃中国火锅"
},
"score": 0.99827427,
"id": "2"
},
{
"entity": {
"title_vector": [1, 2],
"id": "1",
"title": "我是中国人,我喜欢吃火锅"
},
"score": 0.99827427,
"id": "1"
}
]
]其中,score为向量相似度分值,如果score=1,则表示完全一样,score小于1,表示接近。这里为了测试方面,插入数据时,在向量字段里写死了几个固定的list<float>值,真实的业务场景中,要通过embedding模型计算生成,后续文章中介绍如何调用ai中的embedding服务,生成向量化的float值。
到此这篇关于springboot集成milvus,实现数据增删改查的文章就介绍到这了,更多相关springboot集成milvus内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论