mysql数据库连接池
1、概念
jdbc数据连接池:在做开发是不会单独写一个连接,都是使用数据库连接池。
2、为什么会出现数据库连接池
一个项目中,会有很多的用户访问,如果是和之前一样单次连接,那么每次连接数据库都要创建数据库连接对象,来n个用户九创建n个,这样的高并发,服务器受不了。而且用完后关闭连接,浪费资源,如果在关闭的时候出现异常未能关闭连接,就会出现内存泄漏(对象无法回收)
如果没有池化技术,就相当于银行开门,然后业务员服务你一个人,然后关门,下个人来了再开门,这样很浪费资源
使用了数据库连接池之后,我们在开发中就不需要写连接数据库代码了
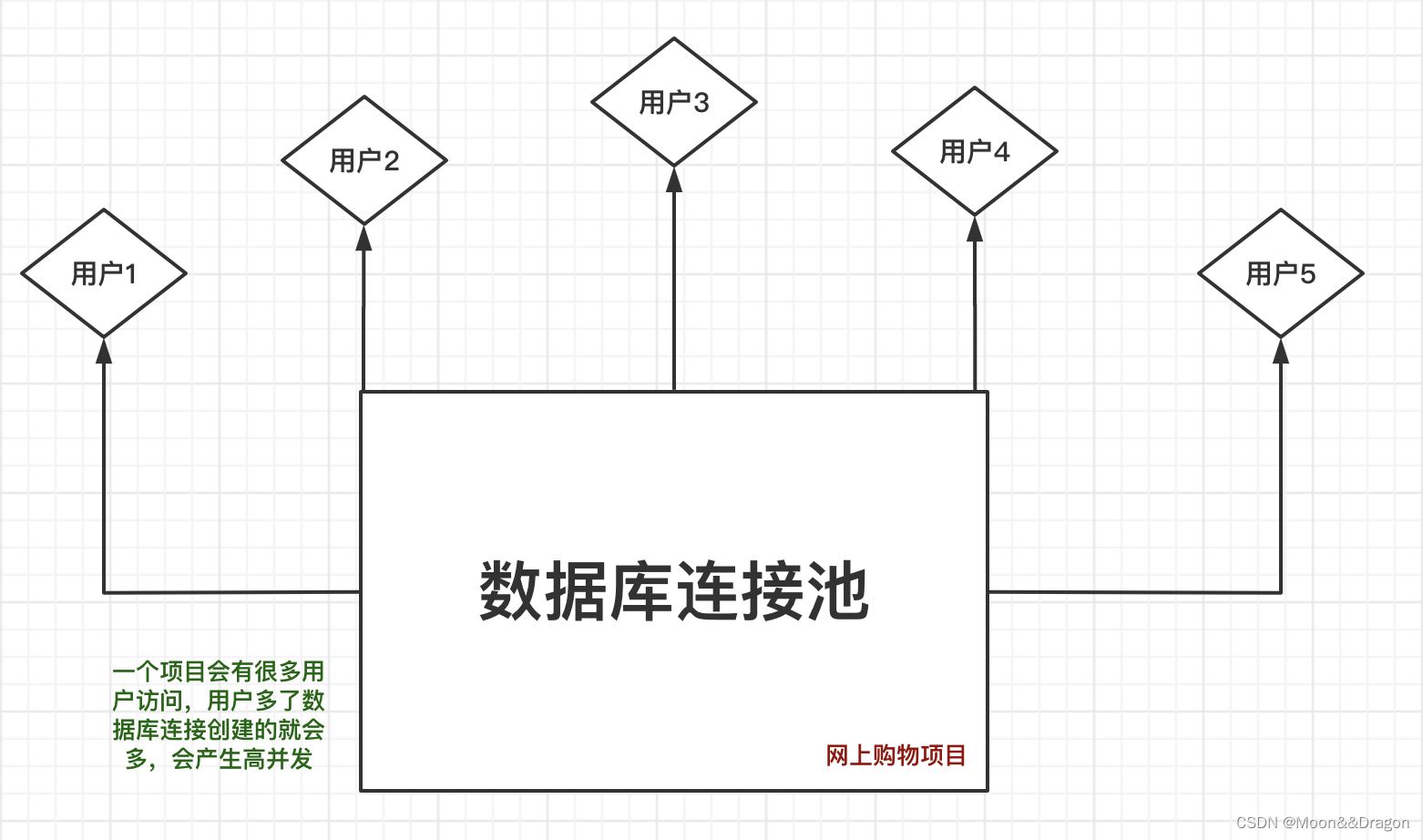
3、原理
- 和线程池类似,规定了最大的承载量,比如有留出了5个连接对象,那么第六个人就需要排队
- 如果使用完毕去关闭数据库连接对象,不会真的关闭,只是被连接池回收,然后给排队的下一个人使用
- 相当于银行开门,开门以后业务员服务客户,没有客户的时候就等待,然后到点关门,业务员不再工作
4、数据库连接池的提供商
数据库连接池的有很多,比较热门的有:
- dbcp
- 是tomcat自带的,相对于c3p0来说速率较快,但是不稳定
- c3p0
- 速率比较慢,但是非常稳定
- druid(德鲁伊)
- 是阿里提供,最常用的,它结合了dbcp和c3p0各自的优点
5、datasource数据源
- 实现接口datasource就可以编写数据源
- 通过datasource替换了drivermanager,相当于在各个数据库厂商提供的驱动的基础上,再次进行包装
6、dbcp
- 导入jar包
- java中使用
public class dbcptest {
private static datasource datasource = null;
public static void dbcptest() {
try {
// 读取文件配置
inputstream config = dbcptest.class.getclassloader().getresourceasstream("resources/config.properties");
properties prop = new properties();
prop.load(config);
// 创建数据源 工厂模式
datasource = basicdatasourcefactory.createdatasource(prop);
// 从数据源中获取连接
connection connection = datasource.getconnection();
} catch (ioexception e) {
// todo auto-generated catch block
e.printstacktrace();
} catch (exception e) {
// todo auto-generated catch block
e.printstacktrace();
}
}
}- 配置文件
driverclassname=com.mysql.cj.jdbc.driver url=jdbc:mysql://localhost:3306/school?useunicode=true&characterencoding=utf8&usessl=true username=root password=19981104
7、c3p0
- 导入jar包
- java中使用
public static void main(string[] args) throws propertyvetoexception, sqlexception {
// 实例化c3p0提供的连接池
combopooleddatasource cpds = new combopooleddatasource();
// 加载当前使用的数据库
cpds.setdriverclass("com.mysql.cj.jdbc.driver");
cpds.setjdbcurl("jdbc:mysql://localhost:3306/school?useunicode=true&characterencoding=utf8&usessl=true");
cpds.setuser("root");
cpds.setpassword("19981104");
// 通过datasource数据源获得连接对象
connection connection = cpds.getconnection();
// 设置初始化连接池中的连接对象
cpds.setinitialpoolsize(2);
// 也可以通过加载配置文件使用数据库
// 在实例化时,去加载配置文件
// 这里的配置文件名是xml中的named-config的name
combopooleddatasource cpds2 = new combopooleddatasource("intergalactoapp");
connection connection2 = cpds2.getconnection();
system.out.println(connection2);
}配置xml
- xml是一个文本标记语言,就是使用标签对组成的语言,进行记录文本信息
- xml文件主要的作用就是标记存储内容的
<?xml version="1.0" encoding="utf-8"?>
<c3p0-config>
<!-- 在这下面配置数据库信息 -->
<named-config name="intergalactoapp">
<!-- 配置驱动,url,user和password -->
<property name="driverclass">com.mysql.cj.jdbc.driver</property>
<property name="jdbcurl">jdbc:mysql://localhost:3306/school?usessl=true</property>
<property name="user">root</property>
<property name="password">password</property>
<property name="acquireincrement">50</property>
<property name="initialpoolsize">100</property>
<property name="minpoolsize">50</property>
<property name="maxpoolsize">1000</property>
<!-- intergalactoapp adopts a different approach to configuring statement caching -->
<property name="maxstatements">0</property>
<property name="maxstatementsperconnection">5</property>
</named-config>
</c3p0-config>8、druid(德鲁伊)
- 导入jar包
- java中使用
public static void main(string[] agrs) throws exception {
druiddatasource datasource = new druiddatasource();
// 不管是谁想要连接数据库服务器,都需要用户名,密码,url,driver
// datasource.setdriverclassname(driverclass);
// datasource.seturl(jdbcurl);
// 读取配置文件
inputstream config = druidtest.class.getclassloader().getresourceasstream("resources/config.properties");
properties prop = new properties();
prop.load(config);
// 使用工厂模式 -- 提供了生产数据源对象的工厂
// 读取druid读取配置文件
datasource datasource2 = druiddatasourcefactory.createdatasource(prop);
// 获得连接对象
connection connection = datasource2.getconnection();
}总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论