一、整体目标
核心功能:自动将excel数据同步到飞书文档的末尾,并添加时间戳。
应用场景:
- 每日销售数据报表自动更新到团队文档
- 周报自动化生成
- 实时数据看板同步
二、代码结构拆解
# 基础设施层 import pandas as pd # 数据处理 import requests # 网络请求 import logging # 错误追踪 from datetime import datetime # 时间处理 # 配置层 logging配置 → api密钥配置 # 功能层 get_access_token() → 获取系统通行证 insert_to_feishu() → 内容插入逻辑 # 执行层 main() → 流程控制器
三、核心逻辑讲解(重点)
用「快递送货」做类比:
1. 建立安全连接(获取access_token)
好比:快递员需要先获取小区门禁卡
流程:
- 准备身份证(app_id)和密码(app_secret)
- 到门卫处(飞书认证接口)验证身份
- 获得临时通行证(tenant_access_token)
response = requests.post(url, json=data) # 发送验证请求 return response.json()["tenant_access_token"] # 提取通行证
2. 定位文档位置
好比:找到要送货的楼层和房间
两步作:
1.获取整栋楼结构(获取文档所有内容块)
blocks = requests.get(blocks_url).json()["data"]["items"]
2.找到最后一间房(定位最后一个内容块)
last_block_id = blocks[-1]["block_id"] # 列表末尾元素
3. 数据包装与投递
好比:打包货物并送货
包装阶段:
# 添加醒目时间标签 时间戳 = datetime.now().strftime(...) # 将excel转为markdown表格 markdown_table = df.to_markdown(index=false)
投递作:
requests.post(insert_url, json={
"content": "**时间标签** + 表格数据",
"position": "after" # 放在最后
})
四、异常处理机制
用「行车记录仪」做类比:
日志配置(相当于安装记录仪)
logging.basicconfig(
filename='feishu_sync.log', # 记录文件
level=logging.info, # 记录级别
format='时间-级别-信息' # 记录格式
)
关键节点监控(示例):
try:
发送请求...
except exception as e:
logging.error(f"插入失败: {e}") # 记录错误快照
五、函数讲解
get_access_token()
def get_access_token():
"""获取飞书api的access_token"""
# 定义api请求地址
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
# 设置http请求头(告诉服务器我们发送的是json数据)
headers = {"content-type": "application/json"}
"""
服务器会根据 content-type 的值,调用对应的解析方式。例如:
如果是 application/json,服务器会用 json 解析器处理数据。
如果是 application/x-www-form-urlencoded,服务器会按表单格式解析数据。
"""
# 准备请求数据(飞书应用的id和密钥)
data = {"app_id": app_id, "app_secret": app_secret}
try:
# 发送post请求到飞书服务器
response = requests.post(url, headers=headers, json=data)
# 检查响应状态码(如果不是200,会抛出异常)
response.raise_for_status()
# 解析返回的json数据,提取访问令牌
return response.json()["tenant_access_token"]
except exception as e:
# 记录错误日志
logging.error(f"获取access_token失败: {e}")
# 失败时返回none
return none关键概念解释
1. 飞书api访问令牌 (tenant_access_token)
- 这是飞书api的“通行证”,调用其他api(如发送消息、读取数据)时必须携带它。
- 令牌有效期通常为2小时,需要定期重新获取。
2. http请求
- post:一种http方法,表示向服务器提交数据(这里是提交和)。app_idapp_secret
- headers:请求头, 表示发送的数据是json格式。content-type: application/json
- data:实际发送的数据,包含飞书应用的凭证。
3. app_id 和 app_secret
- 这两个值需要从飞书开放平台注册应用后获取。
- 非常重要! 相当于你的应用账号密码,需严格保密
4. 异常处理 (try-except)
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response.json()["tenant_access_token"]
except exception as e:
logging.error(f"获取access_token失败: {e}")
return none
1. response = requests.post(url, headers=headers, json=data)
作用:向指定的 url 发送一个 http post 请求。
参数说明:
url: 目标 api 接口地址(例如飞书的 tenant_access_token 获取接口)。
headers: 请求头,通常包含 content-type 等信息(如之前设置的 application/json)。
json=data: 自动将 data 对象(字典)序列化为 json 字符串,并设置 content-type: application/json。
关键点:
使用 json=data 比手动转换数据更简洁(等价于 data=json.dumps(data) + 设置请求头)。
2. response.raise_for_status()
作用:检查 http 响应状态码,如果状态码表示错误(如 4xx 客户端错误、5xx 服务器错误),直接抛出异常。
常见状态码:
- 200 ok: 请求成功。
- 400 bad request: 请求参数错误。
- 401 unauthorized: 身份验证失败。
- 500 internal server error: 服务器内部错误。
意义:
如果服务器返回错误状态码(如飞书接口返回 {"code": 9999, "msg": "invalid params"}),此方法会抛出 httperror 异常,阻止后续代码执行,避免处理错误数据。
3. return response.json()["tenant_access_token"]
作用:
response.json(): 将 http 响应内容解析为 python 字典(前提是响应内容是 json 格式)。
["tenant_access_token"]: 从解析后的字典中提取 tenant_access_token 字段的值并返回。
关键点:
假设飞书接口返回的 json 结构为 {"code":0, "tenant_access_token":"xxx", "expire":7200}。
如果响应不是合法的 json,response.json() 会抛出 jsondecodeerror。
4.except exception as e:
作用:捕获所有类型的异常(包括 httperror、jsondecodeerror、网络超时等)。
细节:
logging.error(...): 记录错误日志(比 print 更规范,可输出到文件或监控系统)。
return none: 返回 none 表示获取 access_token 失败,调用方可通过判断返回值是否为 none 处理错误。
完整逻辑流程图
开始
│
├─ 发送 post 请求 → 成功?
│ ├─ 是 → 检查状态码 → 正常?
│ │ ├─ 是 → 解析 json → 返回 tenant_access_token
│ │ └─ 否 → 抛出 httperror
│ └─ 否 → 抛出异常(如网络错误)
│
└─ 捕获异常 → 记录日志 → 返回 none
insert_to_feishu()
1.获取访问令牌
access_token = get_access_token()
调用 get_access_token() 函数获取飞书api的访问令牌(需提前实现)。
若获取失败(如认证错误),直接返回 false。
2.获取文档块列表
blocks_url = f"https://open.feishu.cn/open-apis/docx/v1/documents/{document_id}/blocks"
headers = {"authorization": f"bearer {access_token}"}
blocks_response = requests.get(blocks_url, headers=headers)
通过飞书api获取文档的块(block)结构。块是文档内容的组成单元(如段落、标题、表格等)。
document_id 是目标文档的唯一标识,需提前从飞书后台获取。
headers = {"authorization": f"bearer {access_token}"}
这行代码用于构造一个 http 请求头(request headers),目的是向飞书api服务端证明当前请求的合法性。
认证机制
bearer token:这是现代api认证的常见方式,属于oauth 2.0协议的一部分。
功能:通过将 access_token(访问令牌)放在请求头中,告知飞书服务器“持有此令牌的用户/应用有权访问该api”。
类比:类似于现实中的“门禁卡”,只有持有有效卡(access_token)的人才能通过门禁(api权限校验)。
格式说明
键值对结构:
键(key): authorization
值(value): bearer {access_token}
(将 access_token 的值替换到 {access_token} 的位置)
示例:
# 假设 access_token = "abc123xyz"
headers = {"authorization": "bearer abc123xyz"}
技术细节
为什么必须用 bearer 前缀?
这是oauth 2.0的标准规范,用于明确令牌类型。服务端会根据前缀判断认证方式。
access_token 从何而来?
通常通过飞书开放平台的身份认证流程生成,例如:
- 用户登录后授权获取
- 应用自身体验的令牌(如机器人或服务端api调用
实际应用场景
在飞书api请求中,所有需要权限的操作(如读写文档、获取用户信息等)都必须携带此头。例如:
# 发送请求时附加 headers response = requests.get(url, headers=headers)
3.飞书文档中获取所有内容块
这三行代码用于 从飞书文档中获取所有内容块(blocks),是操作飞书文档的核心步骤。
发送http get请求
blocks_response = requests.get(blocks_url, headers=headers)
功能:
向飞书api发送一个 get请求,目标地址是 blocks_url(例如 https://open.feishu.cn/open-apis/docx/v1/documents/{document_id}/blocks)。
参数说明:
headers=headers:携带认证头(包含 authorization: bearer {access_token}),用于权限验证。
返回值:
blocks_response 是一个 response 对象,包含服务端返回的原始http响应。
检查http响应状态
blocks_response.raise_for_status()
功能:
自动检测http响应状态码。如果状态码是 4xx(客户端错误) 或 5xx(服务端错误),直接抛出异常(如 httperror),终止后续代码执行。
为什么需要它?
避免在请求失败时继续处理无效数据(例如令牌过期、url错误、权限不足等)。
典型错误场景:
- 401 unauthorized:access_token 失效或未传。
- 404 not found:blocks_url 地址错误或文档不存在。
解析json数据并提取内容块
blocks = blocks_response.json()["data"]["items"]
将http响应的原始内容(json格式)解析为python字典,并提取其中的文档块列表。
数据结构(以飞书文档api为例):
{
"code": 0,
"data": {
"items": [
{"block_id": "xxxx", "content": "文本内容1"},
{"block_id": "yyyy", "content": "文本内容2"}
]
}
}
它的操作可以拆解为以下步骤:
blocks_response.json():将 http 响应的原始内容(json 格式)转换为 python 的字典(dict)或列表(list)。
["data"]:从 json 字典中提取键为 "data" 的值(通常包含核心数据)。
["items"]:从 "data" 对应的字典中,进一步提取键为 "items" 的值(通常是一个列表,包含多个数据项)。
结果:
blocks 变量存储所有文档块的列表,后续可用于遍历、修改或插入新内容。
示例:
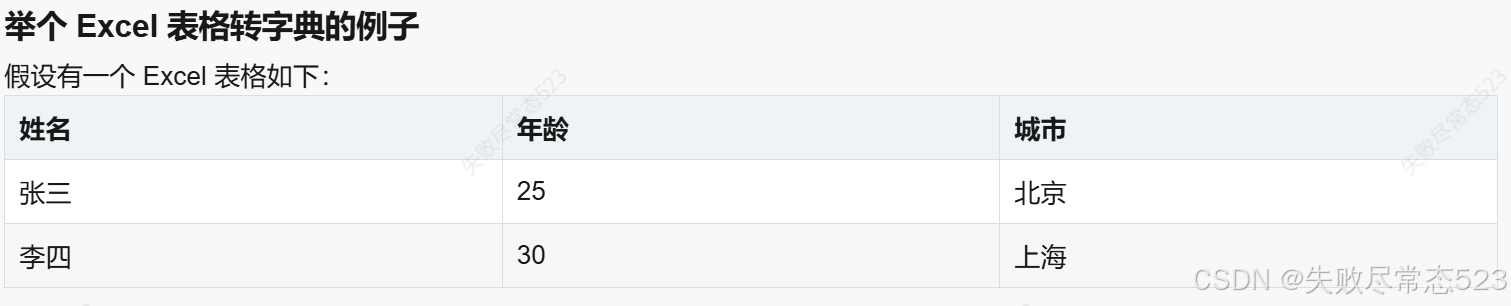
当我们将这个表格转换为 python 的字典列表时,结果如下:
data = {
"code": 0,
"message": "成功",
"data": {
"items": [
{"姓名": "张三", "年龄": 25, "城市": "北京"},
{"姓名": "李四", "年龄": 30, "城市": "上海"}
]
}
}
# 提取表格中的每一行(即 items 列表)
items = data["data"]["items"]
此时 items 的值是:
[
{"姓名": "张三", "年龄": 25, "城市": "北京"},
{"姓名": "李四", "年龄": 30, "城市": "上海"}
]
类比解释
data["data"]
类似于 excel 表格的整个数据区域(包含表头和所有行),对应代码中 data 字段的内容。
data["data"]["items"]
类似于 excel 表格中所有行的数据(每一行是一个字典),对应代码中的 items 列表。
最终结果 blocks
就是一个列表,每个元素代表一个独立的“块”(对应 excel 中的一行),例如:
blocks = [
{"block_id": "段落1", "text": "这是第一段内容"},
{"block_id": "图片1", "url": "https://example.com/image.jpg"}
]
4.定位最后一个块的id
last_block_id = blocks[-1]["block_id"] if blocks else none
从返回的块列表中提取最后一个块的 block_id。
若文档为空(无任何块),last_block_id 为 none,可能导致后续插入失败。
5.插入新内容
insert_url = f"https://open.feishu.cn/open-apis/docx/v1/documents/{document_id}/blocks/{last_block_id}/insert"
data = {
"content": f"**数据更新时间:{datetime.now().strftime('%y-%m-%d %h:%m:%s')}**\n{content}",
"position": "after"
}
insert_response = requests.post(insert_url, headers=headers, json=data)
在最后一个块之后插入新内容。
content 字段包含带时间戳的加粗标题(markdown语法)和传入的 content 参数。
飞书api支持富文本格式,此处使用 ** 表示加粗,实际可能需要根据api要求调整格式
- "content": f"**数据更新时间:{datetime.now().strftime('%y-%m-%d %h:%m:%s')}**\n{content}",
- "position": "after" # 在最后一个块后插入
这是**字典(dict)**中的两个键值对,通常用于配置内容插入逻辑(例如生成报告、更新文档等场景)。
(1) "content": ...
功能:定义要插入的文本内容,包含动态时间和原始内容。
细节:
- f"...":使用 python 的 f-string 动态生成字符串。
- datetime.now():获取当前时间。
- strftime('%y-%m-%d %h:%m:%s'):将时间格式化为 年-月-日 时:分:秒(例如 2023-10-05 14:30:00)。
- **数据更新时间:...**:用 markdown 的粗体语法包裹时间戳,使其突出显示。
- \n{content}:换行后追加原始内容(假设 content 是已定义的变量)。
(2) "position": "after"
功能:指定插入位置为目标位置之后(例如在文档的最后一个段落/区块后追加内容)。
常见值:
- "after":在指定位置后插入。
- "before":在指定位置前插入。
- "replace":替换原有内容。
实际输出示例
假设 content 的值为 "这是原始内容",则生成的 "content" 结果为:
效果:在原始内容前添加时间戳,并用粗体显示。
**数据更新时间:2023-10-05 14:30:00**
这是原始内容
insert_response = requests.post(insert_url, headers=headers, json=data)
insert_response.raise_for_status()
logging.info("数据插入成功!")
这段代码用于向指定的url发送http post请求,插入数据并处理响应。
6.异常处理
try:
# ...请求代码...
except exception as e:
logging.error(f"插入数据失败: {e}")
return false
捕获网络错误、api响应错误等异常,记录日志并返回 false。
六、main()
def main():
"""主函数:读取excel并同步到飞书"""
try:
# 读取excel数据
df = pd.read_excel("data.xlsx") # 替换为你的excel路径
markdown_table = df.to_markdown(index=false)
# 插入到飞书文档
if insert_to_feishu(markdown_table):
print("同步成功!")
else:
print("同步失败,请查看日志文件。")
except exception as e:
logging.error(f"主流程异常: {e}")
markdown_table = df.to_markdown(index=false)
代码功能
- 作用:将 pandas 的 dataframe (df) 转换为 markdown 格式的表格字符串,并保存到变量 markdown_table 中。
- 参数 index=false:表示生成的表格中不包含行索引列(默认会显示索引)。
示例与输出
假设有一个 dataframe:
import pandas as pd
data = {
"name": ["alice", "bob", "charlie"],
"age": [25, 30, 35],
"city": ["new york", "london", "tokyo"]
}
df = pd.dataframe(data)
执行代码:
markdown_table = df.to_markdown(index=false) print(markdown_table)
输出结果:
| name | age | city |
|---------|-------|----------|
| alice | 25 | new york |
| bob | 30 | london |
| charlie | 35 | tokyo |
七、相关库函数
1. import pandas as pd
用途:数据分析和处理(表格数据操作)。
常用函数/类:
- pd.read_csv('file.csv'):读取 csv 文件生成 dataframe。
- df.to_csv('output.csv'):将 dataframe 保存为 csv 文件。
- df.head(n):显示 dataframe 前 n 行(默认 5 行)。
df.merge(df2, on='key'):按列合并两个 dataframe。 - df.groupby('column').sum():按列分组聚合数据。 - pd.dataframe(data):从字典/列表创建 dataframe。
# 示例:读取 csv 并处理数据
data = pd.read_csv("data.csv")
filtered_data = data[data["age"] > 18]
filtered_data.to_csv("adults.csv")
2. import requests
用途:发送 http 请求(如 api 调用、网页抓取)。
常用函数/方法:
requests.get(url, params={}):发送 get 请求。
requests.post(url, data={}):发送 post 请求。 - response.json():将响应内容解析为 json。 - response.status_code:获取 http 状态码(如 200 表示成功)。 - response.text:获取原始文本响应内容。
# 示例:调用 api 获取数据
response = requests.get("https://api.example.com/data")
if response.status_code == 200:
data = response.json()
print(data["results"])
3. import logging
用途:记录程序运行日志(调试、警告、错误等)。
常用函数/配置:
- logging.basicconfig(level=logging.info):设置日志级别。
- logging.info('message'):记录一般信息。
- logging.warning('message'):记录警告。
- logging.error('message'):记录错误。
- logger = logging.getlogger(__name__):创建自定义日志记录器。
# 示例:记录程序运行状态
logging.basicconfig(level=logging.info)
logging.info("程序启动")
try:
# 某些操作
except exception as e:
logging.error(f"发生错误: {e}")
4. from datetime import datetime
用途:处理日期和时间。
常用函数/方法:
- datetime.now():获取当前时间。
- datetime.strftime('%y-%m-%d'):格式化时间为字符串。
- datetime.strptime('2023-10-05', '%y-%m-%d'):将字符串解析为时间对象。
- datetime.timestamp():获取时间戳(秒数)。
# 示例:生成带时间戳的日志
current_time = datetime.now().strftime("%y-%m-%d %h:%m:%s")
print(f"操作时间: {current_time}")
八、完整代码
import pandas as pd
import requests
import logging
from datetime import datetime
# 配置日志记录
logging.basicconfig(
filename='feishu_sync.log',
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s'
)
"""
1.logging.basicconfig(...)
logging 是 python 标准库中的日志模块,用于记录程序的运行状态,方便调试和排查问题。
basicconfig() 方法用于配置日志系统的基本设置。
2.filename='feishu_sync.log'
指定日志输出的文件名为 feishu_sync.log,所有日志信息都会被写入该文件。
这样可以在程序运行后,查看 feishu_sync.log 文件来了解程序的执行情况。
3.level=logging.info
设置日志的最低级别为 info,即只记录 info 及更高级别的日志(包括 warning、error 和 critical)。
低于 info 级别的 debug 级日志不会被记录。
4.format='%(asctime)s - %(levelname)s - %(message)s'
指定日志的输出格式,其中:
%(asctime)s:时间戳,表示日志记录的时间(格式如 2025-02-18 12:34:56)。
%(levelname)s:日志级别,如 info、error 等。
%(message)s:具体的日志消息内容。
"""
# 飞书api配置
app_id = "your_app_id"
app_secret = "your_app_secret"
document_id = "gu4lwf32ci0ouakzo50cq8p2njk" # 目标云文档的id
def get_access_token():
"""获取飞书api的access_token"""
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
headers = {"content-type": "application/json"}
data = {"app_id": app_id, "app_secret": app_secret}
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response.json()["tenant_access_token"]
except exception as e:
logging.error(f"获取access_token失败: {e}")
return none
"""
requests.post(url, headers=headers, json=data):使用 requests 库发送一个 post 请求到指定的 url,并携带请求头和请求体数据。json=data 会自动将字典 data 转换为 json 格式的字符串。
response.raise_for_status():检查响应的状态码,如果状态码不是 200(表示请求成功),则抛出 httperror 异常。
response.json()["tenant_access_token"]:将响应的内容解析为 json 格式,并返回其中的 tenant_access_token 字段,即获取到的租户访问令牌。
except exception as e::捕获所有异常,并将异常对象赋值给变量 e。
logging.error(f"获取access_token失败: {e}"):使用 logging 模块记录错误信息,方便后续排查问题。
return none:如果发生异常,返回 none 表示获取令牌失败。
"""
def insert_to_feishu(content):
"""向飞书文档插入内容"""
access_token = get_access_token()
if not access_token:
return false
# 步骤1:获取文档块列表,找到最后一个块的位置
blocks_url = f"https://open.feishu.cn/open-apis/docx/v1/documents/{document_id}/blocks"
headers = {"authorization": f"bearer {access_token}"}
try:
# 获取文档结构
blocks_response = requests.get(blocks_url, headers=headers)
blocks_response.raise_for_status()
blocks = blocks_response.json()["data"]["items"]
# 找到最后一个块的id(用于插入位置)
last_block_id = blocks[-1]["block_id"] if blocks else none
# 步骤2:插入新内容到文档末尾
insert_url = f"https://open.feishu.cn/open-apis/docx/v1/documents/{document_id}/blocks/{last_block_id}/insert"
data = {
"content": f"**数据更新时间:{datetime.now().strftime('%y-%m-%d %h:%m:%s')}**\n{content}",
"position": "after" # 在最后一个块后插入
}
insert_response = requests.post(insert_url, headers=headers, json=data)
insert_response.raise_for_status()
logging.info("数据插入成功!")
return true
except exception as e:
logging.error(f"插入数据失败: {e}")
return false
def main():
"""主函数:读取excel并同步到飞书"""
try:
# 读取excel数据
df = pd.read_excel("data.xlsx") # 替换为你的excel路径
markdown_table = df.to_markdown(index=false)
# 插入到飞书文档
if insert_to_feishu(markdown_table):
print("同步成功!")
else:
print("同步失败,请查看日志文件。")
except exception as e:
logging.error(f"主流程异常: {e}")
if __name__ == "__main__":
main()以上就是python实现excel数据同步到飞书文档的详细内容,更多关于python excel数据同步到飞书的资料请关注代码网其它相关文章!




发表评论