在当今,数据隐私保护变得尤为重要。随着越来越多的个人信息以电子形式存储和传输,确保这些信息的安全至关重要。本文将介绍如何使用python及其相关库来检测pdf文件中的隐私信息,如姓名、身份证号、手机号和邮箱等。
项目背景
我们的目标是开发一个简单的桌面应用程序,该程序能够加载pdf文件,并检查其中是否包含特定的隐私信息。如果检测到这些信息,程序将显示它们的具体位置(页码和行号)。
技术栈
python: 作为主要编程语言。
wxpython: 用于创建图形用户界面。
pdfplumber: 用于从pdf文件中提取文本。
正则表达式(re): 用于匹配隐私信息的模式。
代码解析
首先,我们需要安装必要的库:
pip install wxpython pdfplumber
接下来是核心代码部分:
import wx
import pdfplumber
import re
class pdfprivacychecker(wx.frame):
def __init__(self):
super().__init__(none, title="pdf 个人隐私检查", size=(600, 400))
panel = wx.panel(self)
vbox = wx.boxsizer(wx.vertical)
# 选择文件按钮
self.btn_select = wx.button(panel, label="选择 pdf 文件")
self.btn_select.bind(wx.evt_button, self.on_select_file)
vbox.add(self.btn_select, flag=wx.expand | wx.all, border=5)
# 结果显示框(memo)
self.memo = wx.textctrl(panel, style=wx.te_multiline | wx.te_readonly)
vbox.add(self.memo, proportion=1, flag=wx.expand | wx.all, border=5)
panel.setsizer(vbox)
self.show()
def on_select_file(self, event):
""" 选择 pdf 文件并分析隐私信息 """
with wx.filedialog(self, "选择 pdf 文件", wildcard="pdf 文件 (*.pdf)|*.pdf",
style=wx.fd_open | wx.fd_file_must_exist) as filedialog:
if filedialog.showmodal() == wx.id_cancel:
return
pdf_path = filedialog.getpath()
self.memo.setvalue(f"已选择文件: {pdf_path}\n\n正在分析...\n")
wx.calllater(100, self.analyze_pdf, pdf_path)
def analyze_pdf(self, pdf_path):
""" 分析 pdf 文档中的隐私信息 """
results = []
# 定义隐私信息匹配规则
patterns = {
"姓名": r"[\u4e00-\u9fa5]{2,4}",
"身份证": r"\b\d{18}|\d{17}x\b",
"手机号": r"\b1[3-9]\d{9}\b",
"邮箱": r"[a-za-z0-9_.+-]+@[a-za-z0-9-]+\.[a-za-z0-9-.]+",
"公司": r"[\u4e00-\u9fa5]+公司"
}
with pdfplumber.open(pdf_path) as pdf:
for page_num, page in enumerate(pdf.pages, start=1):
text = page.extract_text()
if not text:
continue
lines = text.split("\n")
for line_num, line in enumerate(lines, start=1):
for label, pattern in patterns.items():
matches = re.findall(pattern, line)
for match in matches:
results.append(f"第 {page_num} 页,第 {line_num} 行:{label} - {match}")
# 显示结果
if results:
self.memo.setvalue("\n".join(results))
else:
self.memo.setvalue("未检测到隐私信息。")
if __name__ == "__main__":
app = wx.app(false)
frame = pdfprivacychecker()
app.mainloop()功能说明
用户界面: 使用wxpython创建一个简单的gui,包括一个按钮用于选择pdf文件和一个多行文本框用于显示检测结果。
文件选择: 用户点击“选择pdf文件”按钮后,会弹出一个文件对话框让用户选择要分析的pdf文件。
隐私信息检测: 使用pdfplumber库读取pdf内容,并利用正则表达式匹配预定义的隐私信息模式。支持的隐私信息包括姓名、身份证号、手机号、邮箱和公司名称。
结果显示: 如果在pdf中检测到隐私信息,会在文本框中显示每条信息的详细位置(页码和行号)。如果没有检测到任何信息,则显示“未检测到隐私信息”。
运行结果
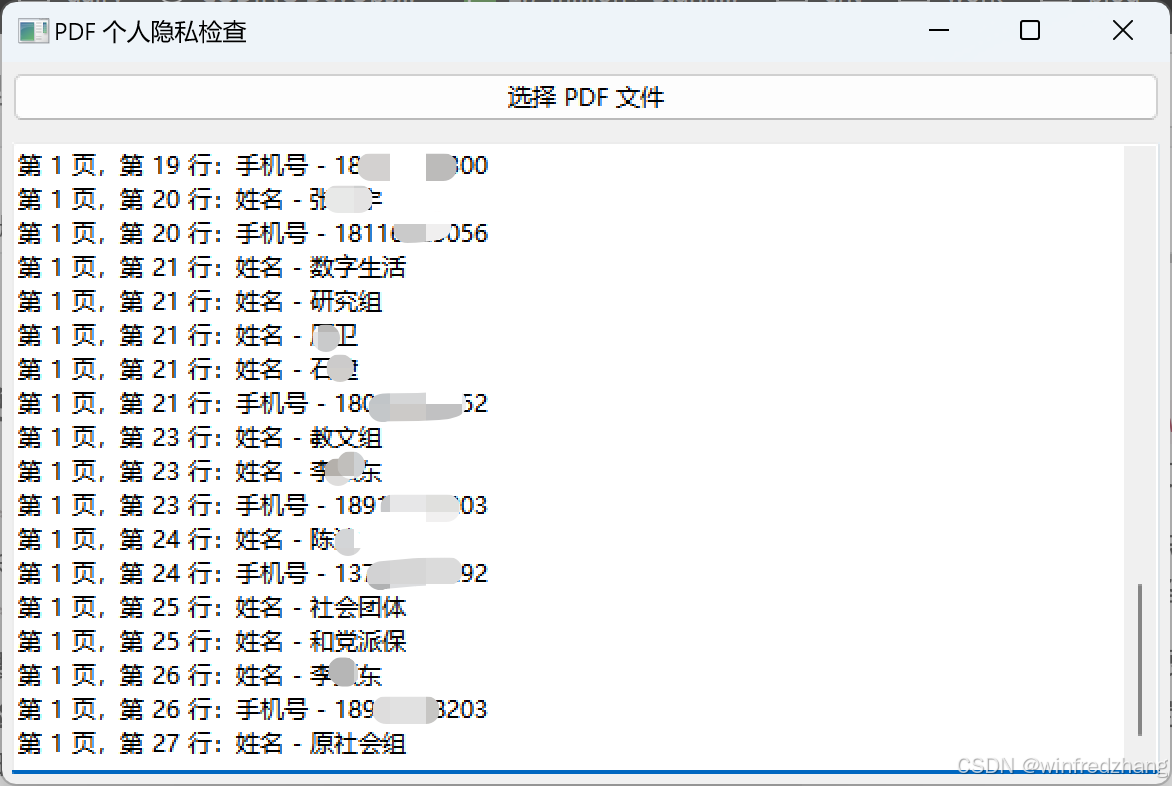
到此这篇关于python如何实现pdf隐私信息检测的文章就介绍到这了,更多相关python pdf隐私信息检测内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论