一、背景
上一篇文章介绍了在gpu主机部署deepseek大模型。并且deepseek使用到了gpu资源来进行推理和计算的过程,加速我们模型的回答速度。
由此,我们必须要关注主机gpu的监控指标情况,例如总的显卡显存大小、占用的显存大小、显卡的版本信息、驱动信息等等,才能对cpu运行情况、利用率等做到心中有数,便于后期的运维、高可用性等。
二、部署nvidia_gpu_exporter
1、nvidia_gpu_exporter介绍
地址: github - utkuozdemir/nvidia_gpu_exporter: nvidia gpu exporter for prometheus using nvidia-smi binary
我们可以使用nvidia_gpu_exporter本质原理是用过nvidia-smi指令采集gpu的信息,然后转换为prometheus metric。
所以部署nvidia_gpu_exporter之前,需要正常安装号nvidia-smi,并且安装好了nvidia驱动、cuda驱动等。
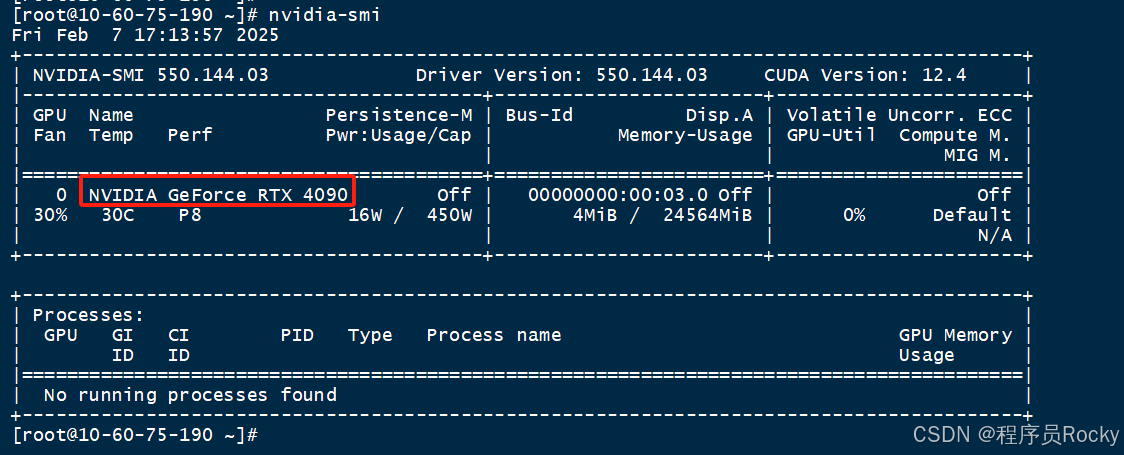
正常执行nvidia-smi如下:
nvidia-smi
2、docker部署,测试/metrics是否正常
执行docker命令:
docker run -d --gpus=all -p 32768:9835 utkuozdemir/nvidia_gpu_exporter:1.3.0-amd64

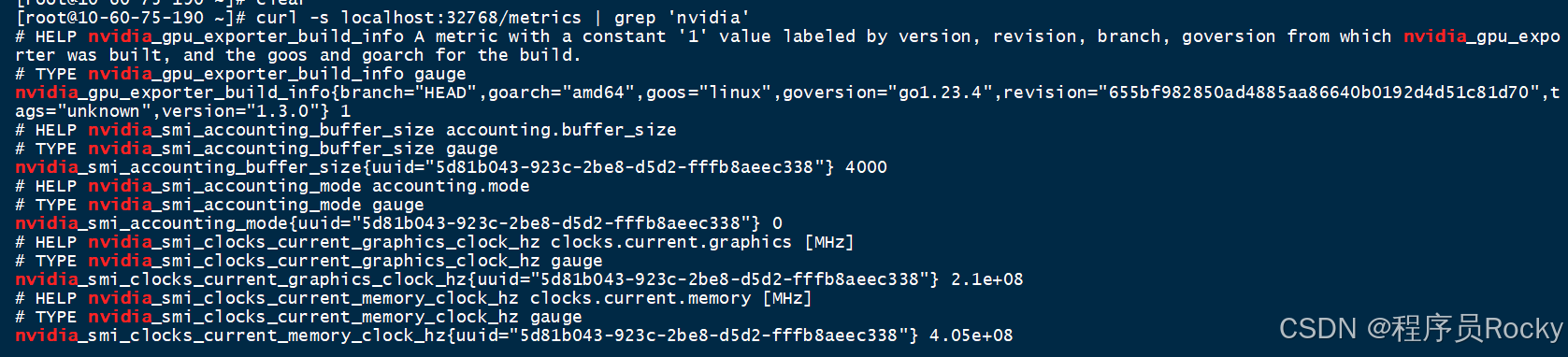
通过curl访问主机的32768(端口可以自己做映射), 访问/metrics接口看是否可以正常拿到指标数据:
curl -s localhost:32768/metrics | grep 'nvidia'
三、配置prometheus+grafana
1、配置prometheus进行采集
配置promethues.yml文件:

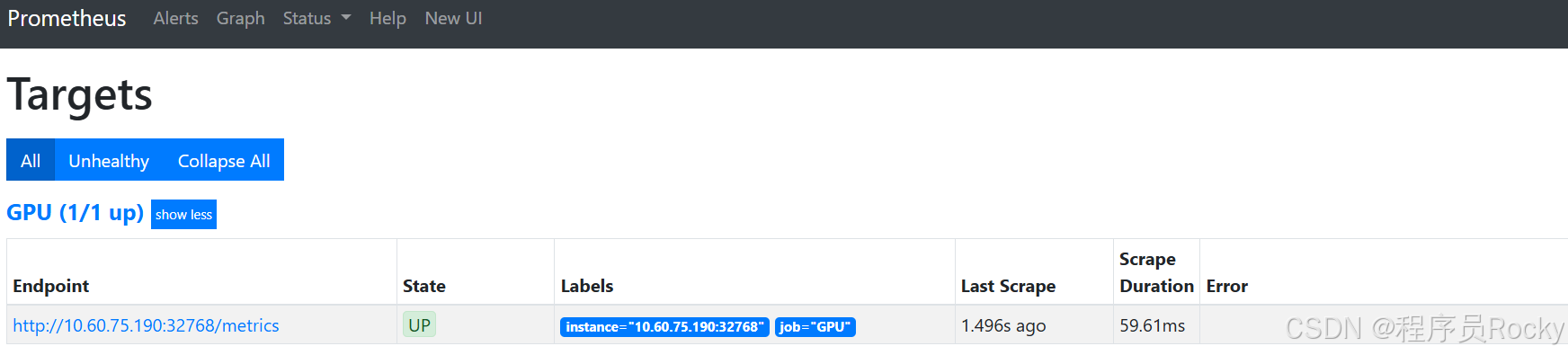
查看promethues的target是否正常能采集到数据:
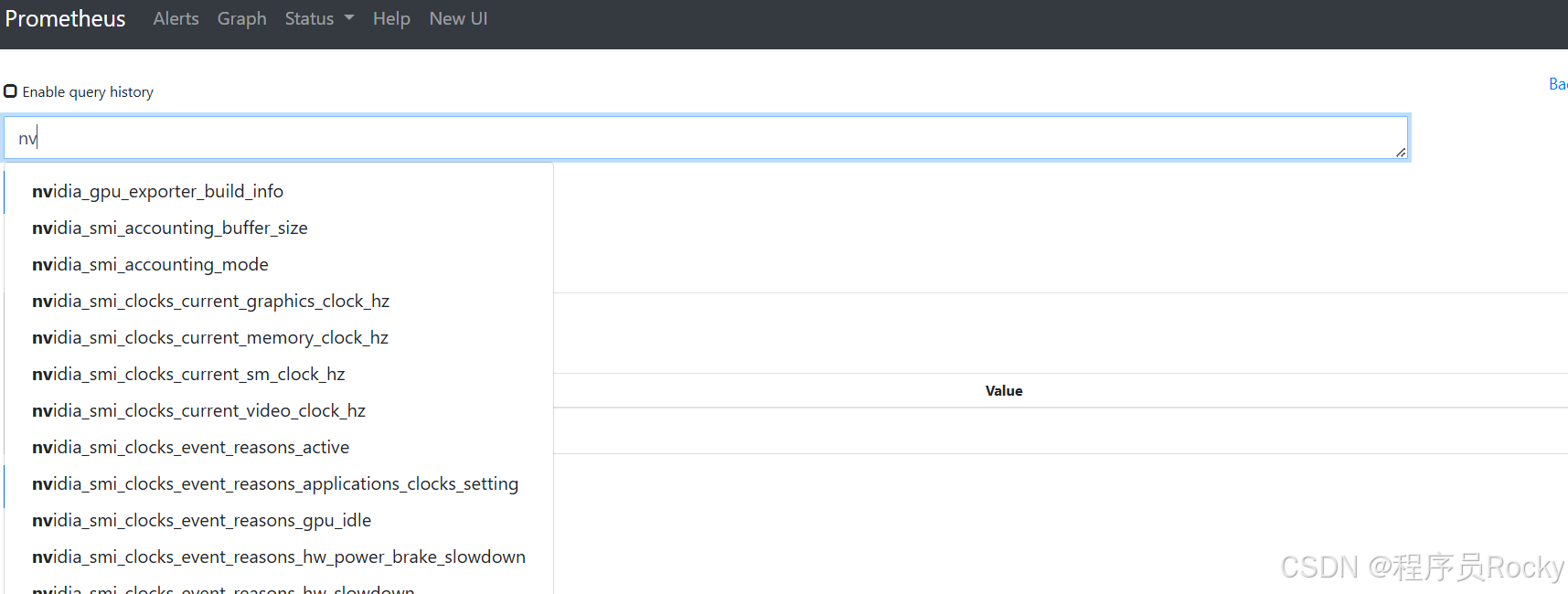
搜索指标是否已经入库:
2、grafana面板搜索并且导入面板
搜索gpu关键词,查询到面板id:
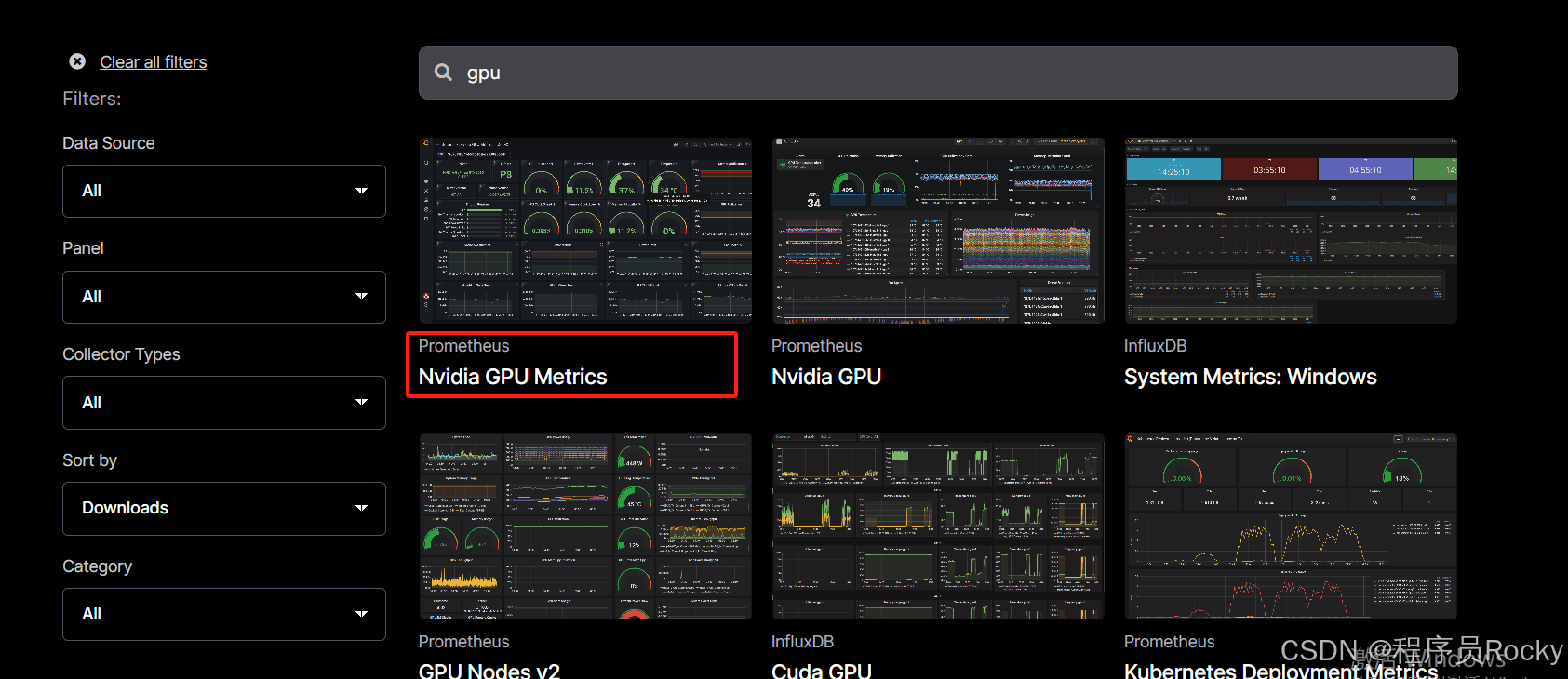
3、导入grafana面板id,查看效果
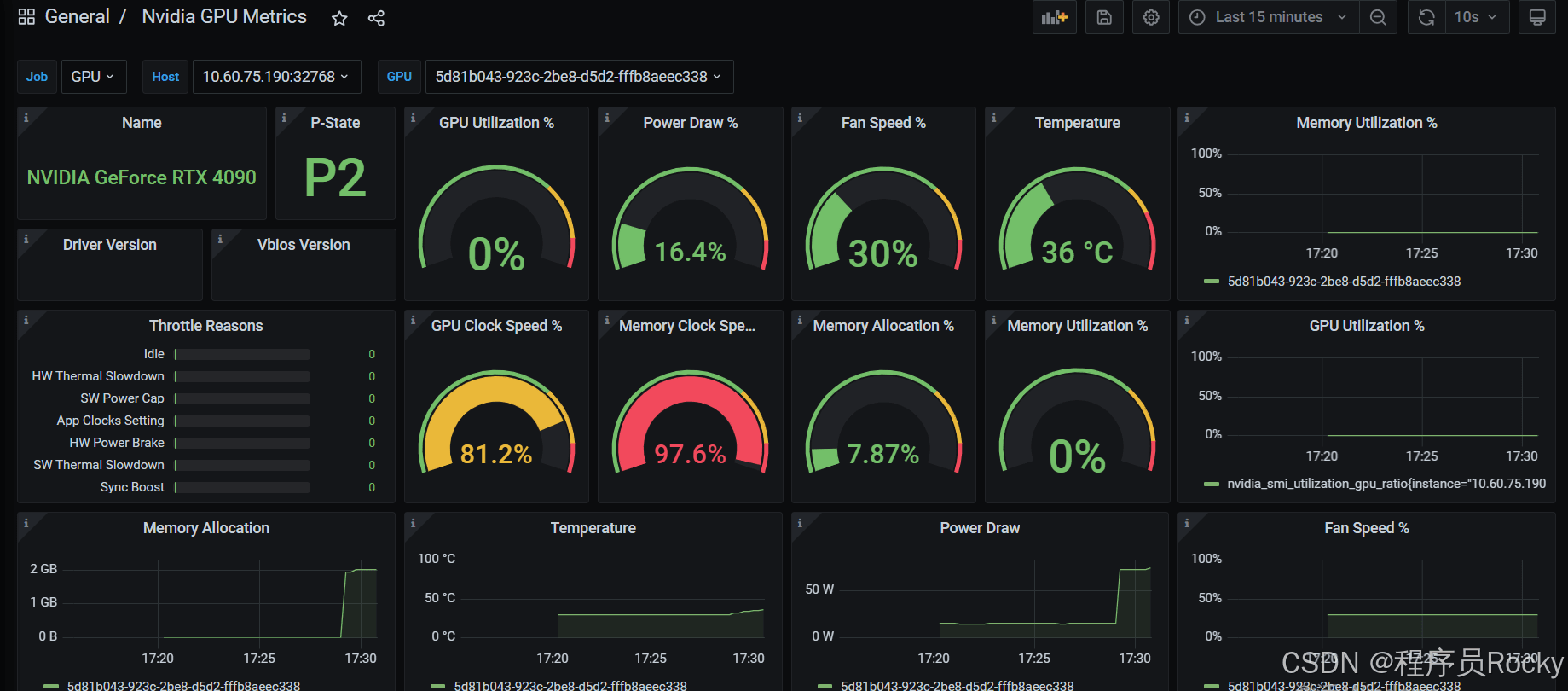
面板可以看到gpu的型号是rtx 4090、显存的使用情况等指标, 此时我正在服务器运行deepseek-r1:1.5b的模型,所以看到gpu的相关使用。如果将模型停止运行,则gpu基本上无占用
四、总结
ai人工智能、大模型等理论知识我们都能多少了解点,但是今天看了一些大佬的教程,稍微深入了一下使用pytorch进行了一些基础、简单模型的训练以及部署运行, 发现从零开始去尝试做机器学习的相关开发工作简直是天方夜谈,涉及到的就是各种概率学、统计学、线性代数、算法等等,门槛是相当高。
既然无法做开发,那么从运维工程师的角度出发,了解pytorch、tensorflow等深度学习框架的部署、模型的运行等等,继续在运维路上前进,扬长避短,才能发挥自我优势!
到此这篇关于deepseek部署之gpu监控指标接入prometheus的文章就介绍到这了,更多相关deepseek gpu接入prometheus内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



![使用python本地部署DeepSeek运行时报错 OSError: [WinError 193] %1 不是有效的 Win32 应用程序的问题及解决方法](https://images1.3wcode.com/3wcode/20250218/s_0_202502181200477570.png)
发表评论