一:背景
1. 讲故事
前几个月有位朋友找到我,说他们的的web程序没有响应了,而且监控发现线程数特别高,内存也特别大,让我帮忙看一下怎么回事,现在回过头来几经波折,回味价值太浓了。
二:程序到底经历了什么
1. 在线程上找原因
这个程序内存高,线程高,无响应,尼玛是一个复合态问题,那怎么入手呢?按经验推测,大概率是由于高线程数引发的,相信大家都知道每个线程都有自己的栈空间,所以众人拾柴火焰高,可以用 !address -summary 观察下线程栈空间。
0:000> !address -summary --- usage summary ---------------- rgncount ----------- total size -------- %ofbusy %oftotal free 329 7df9`d4b93000 ( 125.976 tb) 98.42% <unknown> 994 205`2ae2e000 ( 2.020 tb) 99.81% 1.58% stack 7215 0`e0d00000 ( 3.513 gb) 0.17% 0.00% heap 956 0`1695f000 ( 361.371 mb) 0.02% 0.00% image 1468 0`07b34000 ( 123.203 mb) 0.01% 0.00% teb 2405 0`012ca000 ( 18.789 mb) 0.00% 0.00% other 10 0`001d1000 ( 1.816 mb) 0.00% 0.00% peb 1 0`00001000 ( 4.000 kb) 0.00% 0.00% ... --- state summary ---------------- rgncount ----------- total size -------- %ofbusy %oftotal mem_free 329 7df9`d4b93000 ( 125.976 tb) 98.42% mem_reserve 3132 203`e925c000 ( 2.015 tb) 99.56% 1.57% mem_commit 9917 2`42201000 ( 9.033 gb) 0.44% 0.01%
从卦中可以清晰的看到,提交内存是9g,同时stack吃掉了3.5g,一般来说 stack 不会有这么大,所以此事必有妖,在 teb 中可以看到线程数高达 2405 个,这个确实不少哈,可以用 !t 做一个验证。
0:000> !t
threadcount: 2423
unstartedthread: 0
backgroundthread: 2388
pendingthread: 0
deadthread: 34
hosted runtime: no
lock
dbg id osid threadobj state gc mode gc alloc context domain count apt exception
0 1 3344 00000032972b2d90 202a020 preemptive 0000000000000000:0000000000000000 0000003297125a30 -00001 mta
11 2 1d28 00000037a43b9140 2b220 preemptive 000000364bc5ad90:000000364bc5c328 0000003297125a30 -00001 mta (finalizer)
12 5 2a00 00000037a52bf4d0 102a220 preemptive 00000036527ebde8:00000036527edd90 0000003297125a30 -00001 mta (threadpool worker)
13 7 3168 00000037a52c1b40 302b220 preemptive 00000034d1136688:00000034d1137fd0 0000003297125a30 -00001 mta (threadpool worker)
15 14 13b8 00000037a542ea50 202b220 preemptive 00000036527ebca8:00000036527ebd90 0000003297125a30 -00001 mta
...有了这个入口点,接下来观察每一个线程的线程栈,使用 ~*e !clrstack发现有大量的线程在 postmethod 方法中的 task.result 上等待,看样子是在做网络请求,这里做了一下提前截断,截图如下:

由于是知名券商,这里就尽量模糊了哈。。。请见谅,知道了在 task.result 上,一下子就开心起来了,自此也被误入歧途。。。。
2. 误入歧途
- 是上下文导致的吗?
过往经验告诉我,很多时候的 task.result 卡死是因为上下文的关系所致,所以重点看下是不是 asp.net 的程序,使用 !eeversion 观察便知。
0:000> !eeversion 6.0.422.16404 free 6,0,422,16404 @commit: be98e88c760526452df94ef452fff4602fb5bded server mode with 8 gc heaps sos version: 7.0.8.30602 retail build
从卦中数据看当前是 .net6 写的程序,就不存在上下文一说了,这个情况可以排除,只能继续寻找其他突破口。。。
- 下游处理过慢导致的吗?
是不是下游处理过慢,一个突破点就是观察下 线程池队列 是不是有任务积压,这个可以用 !tp 观察下队列即可。
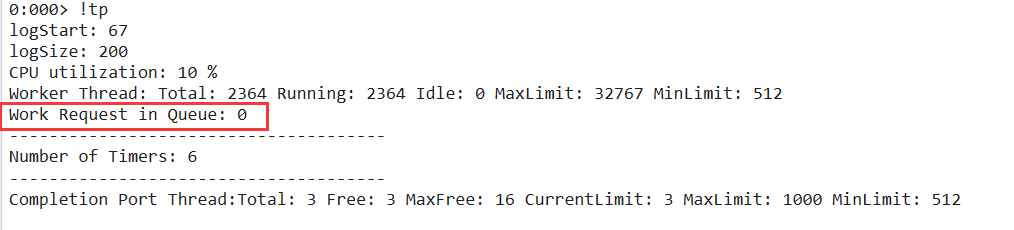
从卦中数据看当前队列无任何积压,说明也不是下游处理过慢导致的,我去,太难了。。。
- 代理或者服务器有问题吗?
既然无上下文,无积压,接下来只能怀疑是不是server方有问题或者用了什么代理软件?要想找这个信息,需要用 !dso 观察线程栈中的对象。
0:000> ~34s ntdll!ntwaitformultipleobjects+0xa: 00007ffe`115c0cba c3 ret 0:034> !dso os thread id: 0x1ef4 (34) rsp/reg object name 00000037b56ac688 000000351f9e4918 system.threading.thread 00000037b56ac700 0000003317bb6160 system.net.http.diagnosticshandler 00000037b56ac708 000000351f9e4918 system.threading.thread 00000037b56ac748 0000003617b743c8 system.net.http.httpwindowsproxy ... 00000037b56ad0d0 00000034c8283750 system.string http://xxx/article/xxx 00000037b56acf30 0000003317bb5ad8 system.net.http.httpclient ...
看了下卦中的请求地址:http://xxx/article/xxx, 同时在 httpwindowsproxy 和 httpclient 中也没有看到所谓的代理ip,这就陷入了迷茫。
事已至此,只能怀疑是网络的问题,让朋友在程序卡死的那个期间段用 wireshark 或者 tcpdump 去抓下包,看看是不是网络出了问题,tcp握手挥手怎么样,事情也就这样不了了之了。
3. 迷途知返
前些天在给训练营的朋友准备课件时,优化了一个例子来演示 线程池队列 的堆积情况,结果意外发现 sos 吐出来的数据是假的,尼妈,如梦初醒,分析dump已经够难了,为什么 sos 还要欺骗我,天真的塌下来了。。。
其实在分析 .net core 的dump时,每每发现线程池队列都是 0 ,虽然有一丝奇怪,但也不敢怀疑sos吐出来的数据权威性。
既然 sos 吐出来的数据是假的,只能自己去线程池中把队列挖出来,即 threadpoolworkqueue.workitems 字段,如下所示:
0:034> !dumpobj /d 0000003517b9c1c0
name: system.threading.threadpoolworkqueue
methodtable: 00007ffd8416d260
eeclass: 00007ffd84196ab8
tracked type: false
size: 168(0xa8) bytes
file: c:\program files\dotnet\shared\microsoft.netcore.app\6.0.4\system.private.corelib.dll
fields:
mt field offset type vt attr value name
00007ffd83ddbf28 4000c61 18 system.boolean 1 instance 0 loggingenabled
00007ffd83ddbf28 4000c62 19 system.boolean 1 instance 0 _dispatchtimesensitiveworkfirst
00007ffd8416dc78 4000c63 8 ...private.corelib]] 0 instance 0000003517b9c268 workitems
00007ffd8416e458 4000c64 10 ...private.corelib]] 0 instance 0000003517b9eea0 timesensitiveworkqueue
00007ffd8416d1f0 4000c65 20 ...achelineseparated 1 instance 0000003517b9c1e0 _separated
...
0:034> !ext dcq 0000003517b9c268
system.collections.concurrent.concurrentqueue<system.object>
1 - dumpobj 0x00000032c93b7ce0
2 - dumpobj 0x00000032c93b8ae8
3 - dumpobj 0x00000032c93b98d8
...
54346 - dumpobj 0x00000034d12fb2e8
54347 - dumpobj 0x0000003652805b40
---------------------------------------------
54347 items从卦中数据看当前线程池堆积了 5.3w 的任务,很显然是属于第二种情况,即下游处理不及,既然处理不急,是不是遇到了什么高峰期呢?这个可以用 .time 观察下当前时段。

从卦中数据看,看样子是快到 收盘时间 了,结合今年的大盘形式,看样子是出现了暴跌,股民们在发泄情绪,哈哈。。。
找到了问题的根,解决方案就比较多了。
做 postmethod 请求的异步化,不要用 result 去硬等待。
尽量做批量化提交,降低请求接口的单次时间。
三:总结
这次生产事故的分析峰回路转,本来是一个很容易就能定位出的问题,可我认为权威的sos居然吐出了假数据欺骗了我,让我误入歧途,浪费了很多的人力物力,真的很无语。。。再也不相信 sos 了!
到此这篇关于.net 某券商论坛系统卡死问题分析的文章就介绍到这了,更多相关.net 某券商论坛系统卡死内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论