在处理扫描的pdf和图片时,文字信息往往无法直接编辑、搜索或复制,这给信息提取和分析带来了诸多不便。手动录入信息不仅耗时费力,还容易出错。光学字符识别(ocr)技术能够将图片中的文字转换为可编辑文本,使信息提取和处理更加高效。如今,ocr已广泛应用于扫描文件的转换、数字化文档的整理、以及自动化数据输入等领域。本文将介绍如何使用python及相关ocr库,实现对图片和扫描pdf中文字的识别。
工具与设置
要在python中实现从图片和扫描pdf中提取文本,我们需要选择一个适当的ocr库。本文所选择的库是spire.ocr for python。该库支持多种语言,包括英语、法语、德语、简体中文、繁体中文、日语、韩语等。在使用该库之前,我们需要完成以下两个步骤:
步骤1:安装spire.ocr for python
在终端中运行以下命令安装spire.ocr for python:
pip install spire.ocr
步骤2:下载ocr模型
spire.ocr for python提供了支持windows(64位)、linux(64位)和macos(10.15及以上)操作系统的三种模型。我们需要根据自己的系统下载适合的模型:
下载完成后,将它解压并保存到特定的目录下。
完成以上两个步骤后,我们就可以使用该库实现识别图片和扫描pdf中的文字。
python 识别图片中的文字
从图片中提取文本的过程比较简单。首先,需要配置 ocr 扫描器的相关设置(例如:文本识别语言和ocr模型的路径);然后对图片进行扫描;最后将识别的文字保存为文本文件。
以下是从图片中提取文本的关键步骤:
- 初始化 ocr 扫描器:创建 ocrscanner 对象。
- 配置 ocr 设置:通过 ocrscanner 对象的 configuredependencies 方法,设置 ocr 模型的路径和文本识别语言。
- 扫描图片:使用 ocrscanner 对象的 scan() 方法,从图片中识别文本。
- 保存文本:获取识别出的文本并保存为文本文件。
实现代码:
from spire.ocr import *
# 初始化ocrscanner对象
scanner = ocrscanner()
# 配置ocr设置(文本识别语言和ocr模型路径)
# 支持的语言包括英语、法语、德语、日语、韩语、简体中文、繁体中文等
configureoptions = configureoptions()
configureoptions.modelpath = r'd:\ocr\win-x64'
configureoptions.language = 'chinese'
scanner.configuredependencies(configureoptions)
# 扫描图片
scanner.scan(r'测试.png')
# 获取识别的文本
text = scanner.text.tostring() + '\n'
# 将文本保存到文本文件
with open('输出.txt', 'a', encoding='utf-8') as file:
file.write(text + '\n')原始图片和识别结果:
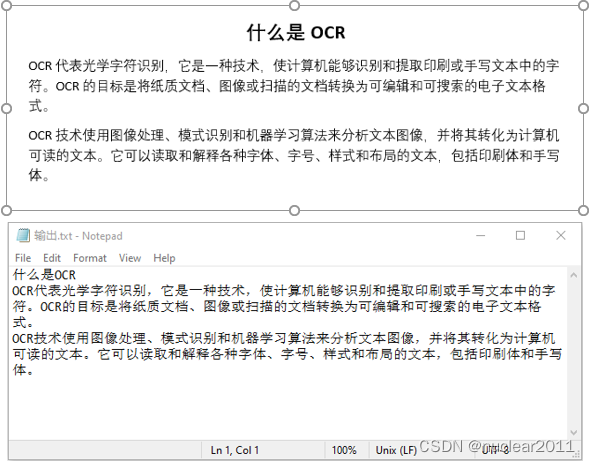
python 识别图片中的文字及其坐标位置
有时除了识别文本外,还需要获取文本在图片中的坐标位置。spire.ocr也支持提取这些信息。
以下是从图片中识别文本并获取其坐标位置的关键步骤:
- 初始化ocr扫描器:创建ocrscanner对象。
- 配置ocr设置:通过ocrscanner对象的configuredependencies方法设置ocr模型的路径和文本识别语言。
- 扫描图片:使用ocrscanner 对象的scan() 方法从图片中识别文本。
- 获取边框坐标:遍历识别的文本中的文本块,获取每个文本块的边框信息(x, y坐标及其宽度和高度)。
- 保存文本和坐标:将文本及其坐标保存到文本文件中。
实现代码:
from spire.ocr import *
# 初始化ocrscanner对象
scanner = ocrscanner()
# 配置ocr设置(文本识别语言和ocr模型路径)
# 支持的语言包括英语、法语、德语、日语、韩语、简体中文、繁体中文等
configureoptions = configureoptions()
configureoptions.modelpath = r'd:\ocr\win-x64'
configureoptions.language = 'chinese'
scanner.configuredependencies(configureoptions)
# 扫描图片
scanner.scan(r'测试.png')
# 遍历识别的文本中的文本块,提取每个文本块的文本和坐标位置等信息
text = ''
for block in scanner.text.blocks:
rectangle = block.box
positions = f'{block.text} -> x: {rectangle.x}, y: {rectangle.y}, w: {rectangle.width}, h: {rectangle.height}'
text += positions + '\n'
# 将文本和坐标保存到文本文件
with open('图片文字及坐标.txt', 'a', encoding='utf-8') as file:
file.write(text + '\n')python 识别扫描pdf中的文字
对于扫描的pdf文档,需先将每一页转换为图片格式。可以借助spire.pdf for python库来实现这一点。将pdf页面转换为图片后,即可对每张图片执行 ocr 处理。
在使用以下代码之前,请先通过以下命令安装spire.pdf:
pip install spire.pdf
以下是从扫描pdf中提取文本的关键步骤:
- 将pdf页面转换为图片:使用spire.pdf加载扫描的pdf文档,然后使用pdfdocument.saveasimage()方法将文档的每一页保存为图片。
- 执行ocr:使用spire.ocr识别每张图片中的文本。
- 保存识别的文本:将识别的文本保存到文本文件中。
实现代码:
from spire.pdf import *
from spire.ocr import *
import io
# 将pdf页面转换为图片
def convert_pdf_page_to_image(pdf, page_index):
return pdf.saveasimage(page_index)
# 从图片中识别文本
def recognize_text_from_image(imgname, language, model_path):
# 初始化ocr扫描器并配置ocr模型的路径和文本识别语言
scanner = ocrscanner()
configure_options = configureoptions()
configure_options.language = language
configure_options.modelpath = model_path
scanner.configuredependencies(configure_options)
# 执行ocr并返回识别的文本
scanner.scan(imgname)
data = scanner.text.tostring()
return data
# 加载扫描pdf文档
pdf = pdfdocument()
pdf.loadfromfile('扫描.pdf')
# 创建文本文件以保存提取的文本
with open('扫描pdf.txt', 'a', encoding='utf-8') as writer:
for page_index in range(pdf.pages.count):
# 将pdf页面转换为图片
image = convert_pdf_page_to_image(pdf, page_index)
imgname="toimage_"+str(page_index)+".png"
image.save(imgname)
# 从图片中识别文本
recognized_text = recognize_text_from_image(imgname, 'chinese', r'd:\ocr\win-x64')
# 将识别的文本写入文本文件
writer.write(f'page {page_index + 1}:\n')
writer.write(recognized_text)
writer.write('\n\n') # 在页面之间添加两个换行符
print('文本已成功保存到"扫描pdf.txt"。')注意事项
ocr的准确性很大程度上受到图片质量的影响。使用清晰、对比度良好,不模糊、倾斜的图片,可以提高识别结果的准确性。不同ocr库可能对不同语言和字体的支持程度不同,一些特定语言或字体可能识别效果较差。因此在识别完成后,最好再人工校对一遍。
到此这篇关于python实现识别图片和扫描pdf中的文字的文章就介绍到这了,更多相关python识别图片和pdf内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论