一、简介
pymupdf,简称fitz,是一个轻量级的python库,它基于mupdf的c++库,提供了丰富的功能,包括但不限于pdf的读取、编辑、转换和渲染。fitz作为pymupdf的子模块,简化和封装了pymupdf的功能,使得在python中处理pdf文件更加简单。
二、安装
pymupdf(包含fitz模块)可以通过python的包管理器pip来安装。
在命令行工具中输入以下命令:
pip install pymupdf
这将从python包索引下载并安装pymupdf及其依赖项。
或者


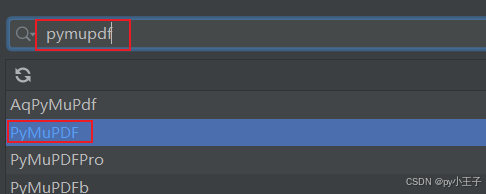

三、基本功能
1、打开pdf文件:
使用fitz.open()函数可以打开一个pdf文件,并返回一个表示该文件的对象。例如:
import fitz
doc = fitz.open("example.pdf")2、获取页面数量:
通过page_count属性可以获取pdf文件的总页数。例如:
page_count = doc.page_count
print("number of pages:", page_count)3、提取文本:
使用get_text()方法可以提取当前页面的所有文本。例如:
text = page.get_text()
print("extracted text:", text)此外,还可以遍历文档中的每一页,提取每一页的文本。
4、保存修改后的pdf:
使用save()方法可以保存对pdf文件所做的更改。例如:
doc.save("modified_example.pdf")
其他功能:
- 插入新的页面:使用
fitz.new_page()创建新页面,然后使用insert_pdf()方法将新页面插入到指定位置。 - 合并多个pdf文件:创建一个空的pdf文档对象,然后遍历要合并的pdf文件,将它们的页面插入到新的文档对象中,最后保存合并后的pdf。
- 提取pdf中的图片:遍历pdf的每一页,使用
get_images()方法获取页面上的所有图像,并保存它们。 - 提取pdf中的表格:使用
find_tables()方法获取页面上的表格,然后可以将表格数据保存为csv格式文件。 四、应用场景
四、应用场景
pymupdf(fitz)适用于需要处理pdf文件的各种场景,如文本提取、页面操作、pdf合并与分割等。它以其快速、高效和易于使用而著称,是处理pdf文件的理想选择。
例如:pdf文件拆分任意页数.py
import fitz
import os
def split_pdf(pdf_path):
# 检查输入的pdf文件是否存在
if not os.path.exists(pdf_path):
print("您输入的路径无pdf文件!")
return
# 打开pdf文件
doc = fitz.open(pdf_path)
page_count = len(doc)
print(f"该pdf文件页数为:{page_count}")
while true:
# 获取起始页码(0基索引)
page_num1 = none
while true:
try:
user_input = input("请输入您拆分的起始页码(输入q/q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num1 = int(user_input) - 1
if page_num1 < 0 or page_num1 >= page_count:
print("起始页码无效,请重新输入。")
else:
break
except valueerror:
print("请输入有效的起始页码或q/q退出。")
# 获取结束页码(0基索引)
page_num2 = none
while true:
try:
user_input = input("请输入您拆分的截止页码(输入q/q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num2 = int(user_input) - 1
if page_num2 < 0 or page_num2 >= page_count:
print("截止页码无效,请重新输入。")
else:
break
except valueerror:
print("请输入有效的截止页码或q/q退出。")
# 创建一个新的pdf文档并插入指定的页面范围
new_doc = fitz.open()
new_doc.insert_pdf(doc, from_page=page_num1, to_page=page_num2)
# 获取用户输入的pdf基础名字和保存目录
pdf_base_name = input("请输入您的pdf基础名字:")
if not pdf_base_name.lower().endswith('.pdf'):
pdf_name = f"{pdf_base_name}_{page_num1 + 1}-{page_num2 + 1}.pdf"
else:
pdf_name = f"{pdf_base_name[:-4]}_{page_num1 + 1}-{page_num2 + 1}.pdf"
save_dir = input("请输入您想要保存pdf的目录(例如:c:/users/yourname/documents/):")
# 确保目录末尾有斜杠,并检查目录是否存在
if not save_dir.endswith(os.sep) and save_dir != "":
save_dir += os.sep
os.makedirs(save_dir, exist_ok=true)
output_path = os.path.join(save_dir, pdf_name)
new_doc.save(output_path)
new_doc.close()
print(f"saved: {output_path}")
# 检查是否继续拆分或退出
is_continue = input("是否继续拆分其他页面范围(q/q退出)?").strip().lower()
if is_continue == 'q':
doc.close()
break
# 调用函数进行pdf拆分
pdf_path = input("请输入您需要拆分的pdf路径:")
split_pdf(pdf_path)
到此这篇关于python实现将pdf文件拆分任意页数的文章就介绍到这了,更多相关python pdf拆分内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论