在word文档中,超链接是一种将文本或图像连接到其他文档、网页或同一文档中不同部分的功能。通过添加超链接,用户可以轻松地导航到相关信息,从而增强文档的互动性和可读性。本文将介绍如何使用python在word中添加超链接、或删除word文档中的超链接。
要实现通过python操作word文档,我们需要安装 spire.doc for python 库。该库的pip安装命令如下:
pip install spire.doc
python 在word中添加超链接
spire.doc for python 库提供了 appendhyperlink() 方法来添加超链接,其中三个参数:
• link – 代表超链接地址
• text – 代表显示文本 (也可传入picture来为图片添加超链接)
• type – 代表超链接类型 (包括网页链接weblink、邮件链接emaillink、书签链接bookmark、文件链接filelink)
示例代码如下:
from spire.doc import *
from spire.doc.common import *
# 创建word文档
doc = document()
# 添加一节
section = doc.addsection()
# 添加一个段落
paragraph = section.addparagraph()
# 添加一个简单网页链接
paragraph.appendhyperlink("https://abcd.com/", "主页", hyperlinktype.weblink)
# 添加换行符
paragraph.appendbreak(breaktype.linebreak)
paragraph.appendbreak(breaktype.linebreak)
# 添加一个邮箱链接
paragraph.appendhyperlink("mailto:support@e-iceblue.com", "邮箱地址", hyperlinktype.emaillink)
# 添加换行符
paragraph.appendbreak(breaktype.linebreak)
paragraph.appendbreak(breaktype.linebreak)
# 添加一个文档链接
filepath = "c:\\users\\administrator\\desktop\\排名.xlsx"
paragraph.appendhyperlink(filepath, "点击查看文件", hyperlinktype.filelink)
# 添加换行符
paragraph.appendbreak(breaktype.linebreak)
paragraph.appendbreak(breaktype.linebreak)
# 添加一个新节并创建书签
section2 = doc.addsection()
bookmarkparagrapg = section2.addparagraph()
bookmarkparagrapg.appendtext("添加一个新段落")
start = bookmarkparagrapg.appendbookmarkstart("书签")
bookmarkparagrapg.items.insert(0, start)
bookmarkparagrapg.appendbookmarkend("书签")
# 链接到书签
paragraph.appendhyperlink("书签", "点击跳转到文档指定位置", hyperlinktype.bookmark)
# 添加换行符
paragraph.appendbreak(breaktype.linebreak)
paragraph.appendbreak(breaktype.linebreak)
# 添加一个图片超链接
image = "c:\\users\\administrator\\desktop\\work1.jpg"
picture = paragraph.appendpicture(image)
paragraph.appendhyperlink("https://abcd.com/", picture, hyperlinktype.weblink)
# 保存文档
doc.savetofile("word超链接.docx", fileformat.docx2019);
doc.dispose()
生成文档:
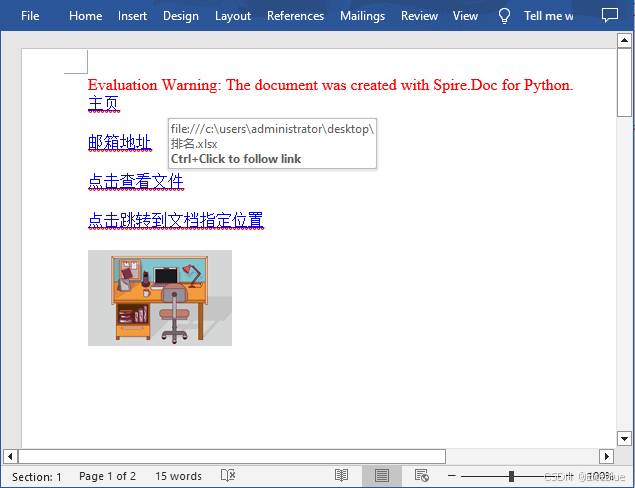
python 删除word中的超链接
要删除 word 文档中的所有超链接,先用到了自定义方法 findallhyperlinks() 来查找文档中的所有超链接,然后再通过自定义方法 flattenhyperlinks() 来扁平化超链接。
示例代码如下:
from spire.doc import *
from spire.doc.common import *
# 查找文档中的所有超链接
def findallhyperlinks(document):
hyperlinks = []
for i in range(document.sections.count):
section = document.sections.get_item(i)
for j in range(section.body.childobjects.count):
sec = section.body.childobjects.get_item(j)
if sec.documentobjecttype == documentobjecttype.paragraph:
for k in range((sec if isinstance(sec, paragraph) else none).childobjects.count):
para = (sec if isinstance(sec, paragraph)
else none).childobjects.get_item(k)
if para.documentobjecttype == documentobjecttype.field:
field = para if isinstance(para, field) else none
if field.type == fieldtype.fieldhyperlink:
hyperlinks.append(field)
return hyperlinks
# 扁平化超链接域
def flattenhyperlinks(field):
ownerparaindex = field.ownerparagraph.ownertextbody.childobjects.indexof(
field.ownerparagraph)
fieldindex = field.ownerparagraph.childobjects.indexof(field)
sepownerpara = field.separator.ownerparagraph
sepownerparaindex = field.separator.ownerparagraph.ownertextbody.childobjects.indexof(
field.separator.ownerparagraph)
sepindex = field.separator.ownerparagraph.childobjects.indexof(
field.separator)
endindex = field.end.ownerparagraph.childobjects.indexof(field.end)
endownerparaindex = field.end.ownerparagraph.ownertextbody.childobjects.indexof(
field.end.ownerparagraph)
formatfieldresulttext(field.separator.ownerparagraph.ownertextbody,
sepownerparaindex, endownerparaindex, sepindex, endindex)
field.end.ownerparagraph.childobjects.removeat(endindex)
for i in range(sepownerparaindex, ownerparaindex - 1, -1):
if i == sepownerparaindex and i == ownerparaindex:
for j in range(sepindex, fieldindex - 1, -1):
field.ownerparagraph.childobjects.removeat(j)
elif i == ownerparaindex:
for j in range(field.ownerparagraph.childobjects.count - 1, fieldindex - 1, -1):
field.ownerparagraph.childobjects.removeat(j)
elif i == sepownerparaindex:
for j in range(sepindex, -1, -1):
sepownerpara.childobjects.removeat(j)
else:
field.ownerparagraph.ownertextbody.childobjects.removeat(i)
# 将域转换为文本范围并清除文本格式
def formatfieldresulttext(ownerbody, sepownerparaindex, endownerparaindex, sepindex, endindex):
for i in range(sepownerparaindex, endownerparaindex + 1):
para = ownerbody.childobjects[i] if isinstance(
ownerbody.childobjects[i], paragraph) else none
if i == sepownerparaindex and i == endownerparaindex:
for j in range(sepindex + 1, endindex):
if isinstance(para.childobjects[j], textrange):
formattext(para.childobjects[j])
elif i == sepownerparaindex:
for j in range(sepindex + 1, para.childobjects.count):
if isinstance(para.childobjects[j], textrange):
formattext(para.childobjects[j])
elif i == endownerparaindex:
for j in range(0, endindex):
if isinstance(para.childobjects[j], textrange):
formattext(para.childobjects[j])
else:
for j, unuseditem in enumerate(para.childobjects):
if isinstance(para.childobjects[j], textrange):
formattext(para.childobjects[j])
# 设置文本样式
def formattext(tr):
tr.characterformat.textcolor = color.get_black()
tr.characterformat.underlinestyle = underlinestyle.none
# 加载word文档
doc = document()
doc.loadfromfile("word超链接.docx")
# 获取所有超链接
hyperlinks = findallhyperlinks(doc)
# 扁平化超链接
for i in range(len(hyperlinks) - 1, -1, -1):
flattenhyperlinks(hyperlinks[i])
# 保存文件
doc.savetofile("删除超链接.docx", fileformat.docx)
doc.close()
生成文件:
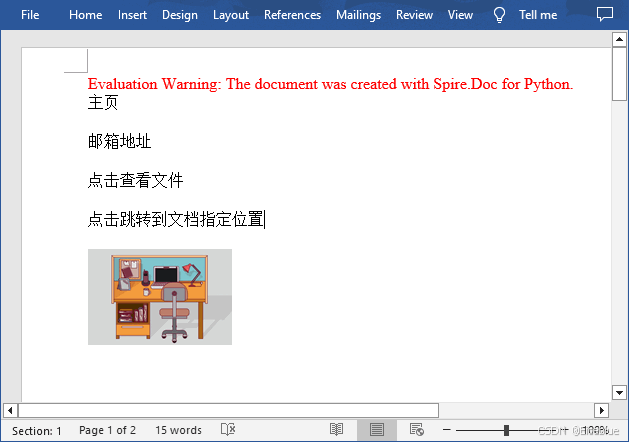
到此这篇关于使用python实现在word中添加或删除超链接的文章就介绍到这了,更多相关python word添加或删除超链接内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论