有一个数据库应用程序存在过多的解析问题,因此需要找到产生大量硬解析的主要语句。
什么是硬解析
oracle数据库中的硬解析(hard parse)是指在执行sql语句时,数据库需要重新解析该sql语句,并创建新的执行计划的过程。这个过程涉及到对sql语句的完整解析、编译和生成执行计划,是数据库性能优化中的一个重要环节。以下是硬解析的详细过程:
- 语法、语义及权限检查:oracle首先会对sql语句进行语法检查,确保语句的拼写和结构正确无误。接着进行语义检查,验证语句中引用的对象是否存在以及执行语句的用户是否具有相应的权限。
- 查询转换:oracle会应用不同的转换技巧,将sql语句转换为语义上等价的其他形式。例如,
count(1)可能会被转换为count(*),以优化查询性能。 - 根据统计信息生成执行计划:这是硬解析中最耗时的步骤。oracle会根据数据库的统计信息,如表的大小、索引的统计数据等,来确定执行sql语句的最佳路径,即成本最低的执行计划。
- 将游标信息(执行计划)保存到库缓存:一旦执行计划生成,oracle会将这个执行计划保存在共享池(shared pool)的库缓存(library cache)中,以便后续相同的sql语句可以重用这个执行计划,减少硬解析的发生。
硬解析的触发条件包括:
- 首次执行某个sql语句时,因为数据库尚未为其生成解析结果,必须进行硬解析。
- 如果一个已经硬解析过的sql语句对应的解析结果在共享池中被替换或因其他原因失效(例如,相关的数据库对象元数据发生变化),那么下次执行该语句时需要重新进行硬解析。
- 即使对于相同的sql文本,如果其绑定变量值或会话环境(如当前用户的权限、nls设置等)发生变化,导致生成的解析树或执行计划与缓存中的不一致,也会触发硬解析。
- 某些类型的sql语句,如ddl(数据定义语言)语句,由于它们的操作通常是不可缓存的,因此总是进行硬解析。
硬解析对数据库性能有显著影响,因为它会消耗大量的cpu资源和内存,增加磁盘i/o,延长查询响应时间,降低用户体验。因此,在数据库性能优化中,通常建议尽量减少硬解析的发生,通过使用绑定变量、优化sql语句结构等方式来提高软解析的比例,从而提升数据库的整体性能。
当必须将 sql 语句加载到共享池中时,会发生硬解析。在这种情况下,oracle server 必须在共享池中分配内存并解析语句。
当共享池太小时,或者当您有没有绑定变量的不可重用 sql 语句时,可能会发生过多的硬解析。
我们可能会想到 awr 报告,其中有一节标题为“sql ordered by parse calls”,但是这里的数值不仅是硬解析调用,而且还包含了软解析。
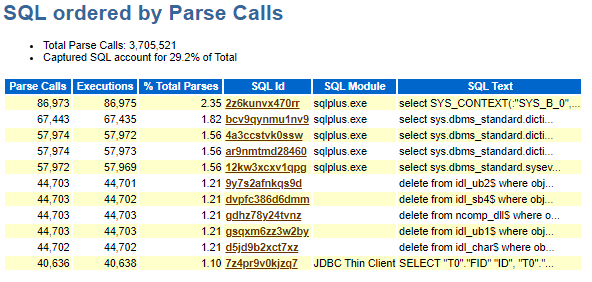
因此我们可以使用查询表中dba_hist_active_sess_history in_hard_parse='y' 的语句,查出真正的硬解析语句。
查询一段时间以来硬解析次数最高语句
select instance_number,top_level_sql_id,sql_id,count(*)
from dba_hist_active_sess_history
where in hard_parse='y'
and snap_id>=39072 and snap_id<=39073
and sample_time>to_date('20240814 09:09','yyyymmdd hh24:mi')
and sample_time<to_date('20240814 10:10','yyyymmdd hh24:mi')
group by instance_number,top_level_sql_id,sql_id
having count(*)>10
order by count(*) desc;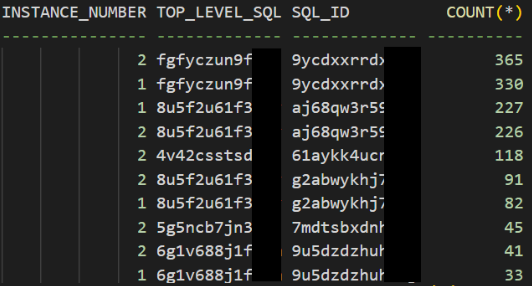
查询一段时间以来所有实例硬解析top语句
select top_level_sql_id,sql_id,count(*
from dba_hist_active_sess_history
where in_hard_parse='y'
and snap_id>=39072 and snap_id<=39093
and sample_time>to_date('20240814 09:08','yyyymmdd hh24:mi')
and sample_time<to_date('20240814 16:15','yyyymmdd hh24:mi')
group by top_level_sql_id,sql_id
having count(*)>10
order by count(*) desc;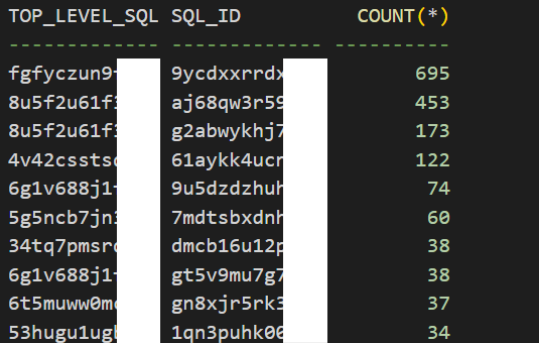
top_level_sql_id和sql_id
很多时候面对包或者存储过程,我们看到的"sql_id"仅仅是包或者存储过程本身的"sql_id",但对于包以及存储过程里面到底包含了哪些sql是不知道的,这时候就可以利用这一列,查出包或者存储过程里的一系列sql_id。
查询存储过程中那些sql语句慢
查询出硬解析语句为存储过程时,如何查看存储过程中的sql语句
###查询存储过程中那些语句慢
set verify on
set echo on
set lines 250
set head on
set tab off
with snaps as
(select /*+ materialize*/
snap_id, dbid
from dba_hist_snapshot
where begin_interval_time > sysdate - &days),
obj as
(select /*+ materialize*/
object_id, subprogram_id
from dba_procedures
where object_name = upper ('&package_name')
and procedure_name = upper('&procedure_name'))
select /*+ push_subq(snp) opt_param('_optimizer_use_feedback' 'false') */
t.*
from (select sql_id,
event,
a.sql_plan_hash_value,
count(distinct sql_exec_id || sql_exec_start) calls,
count(1) cnt
from dba_hist_active_sess_history a
where (plsql_entry_object_id, plsql_entry_subprogram_id) in
(select object_id, subprogram_id from obj)
and (dbid, snap_id) in (select /*+qb_name(snp)*/
dbid, snap_id
from snaps)
group by sql_id, sql_plan_hash_value, event) t
order by sql_id, sql_plan_hash_value, event, cnt desc
/
clear columns
到此这篇关于oracle数据库如何找到 top hard parsing sql 语句?的文章就介绍到这了,更多相关oracle top hard parsing sql 语句内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论