概述
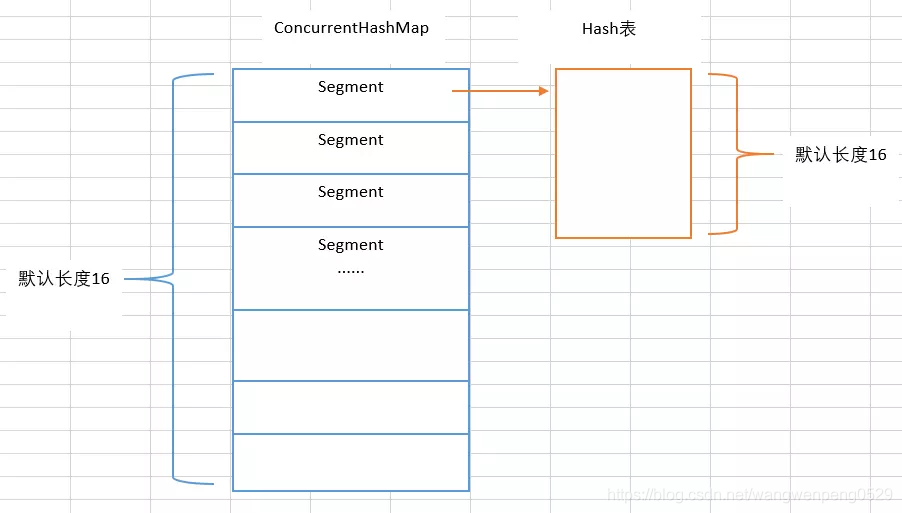
锁分段机制concurrenthashmap
线程安全的hash表 每一段都是一个独立的锁
java 5.0 在 java.util.concurrent 包中提供了多种并发容器类来改进同步容器的性能。
concurrenthashmap 同步容器类是java 5 增加的一个线程安全的哈希表。对与多线程的操作,介于 hashmap 与 hashtable 之间。内部采用“锁分段”机制替代 hashtable 的独占锁。进而提高性能。
此包还提供了设计用于多线程上下文中的 collection 实现:concurrenthashmap、 concurrentskiplistmap、 concurrentskiplistset、copyonwritearraylist 和 copyonwritearrayset。当期望许多线程访问一个给定 collection 时, concurrenthashmap 通常优于同步的 hashmap,concurrentskiplistmap 通常优于同步的 treemap。当期望的读数和遍历远远大于列表的更新数时, copyonwritearraylist 优于同步的 arraylist。
concurrenthashmap就是一个线程安全的hash表。我们知道hashmap是线程不安全的,hashtable加了锁,是线程安全的,因此它效率低。
hashtable加锁就是将整个hash表锁起来,当有多个线程访问时,同一时间只能有一个线程访问,并行变成串行,因此效率低。所以jdk1.5后提供了concurrenthashmap,它采用了锁分段机制。
1.8以后底层又换成了cas,把锁分段机制放弃了。cas基本就达到了无锁的境界。
详解
concurrenthashmap 是 java 中的一个线程安全的哈希表,它在多线程环境下提供了高效的读取和更新操作。
从 java 8 开始,concurrenthashmap 引入了一种新的机制,称为“锁分段”(segmentation with locks),以提高并发性能。
锁分段机制详解
在 java 8 之前的版本中,concurrenthashmap 使用分段锁(segmentation with segments)来实现线程安全。每个段相当于一个小型的哈希表,拥有自己的锁。当多个线程访问不同段的数据时,它们可以并发进行,从而减少了锁的竞争。
然而,java 8 引入的锁分段机制进一步优化了这一点。在新的实现中:
- cas 操作:
concurrenthashmap使用了更多的无锁编程技术,如原子操作(compare-and-swap, cas),来减少锁的使用。 - node 继承结构:内部结构由
node、treenode、treebin等类组成,这些类继承自node,形成了一个复杂的继承结构。 - synchronized 粒度:在某些操作上,如扩容和部分更新操作上,仍然使用了
synchronized块来保证线程安全。 - 减少锁的竞争:通过减少锁的使用,
concurrenthashmap允许更高的并发性,因为线程可以在没有锁的情况下进行大部分操作。
示例
下面是一个简单的 concurrenthashmap 使用示例:
import java.util.concurrent.concurrenthashmap;
public class concurrenthashmapexample {
public static void main(string[] args) {
// 创建一个 concurrenthashmap 实例
concurrenthashmap<string, integer> map = new concurrenthashmap<>();
// 插入数据
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
// 读取数据
system.out.println(map.get("two")); // 输出 2
// 并发更新数据
for (int i = 0; i < 10; i++) {
int finali = i;
new thread(() -> map.put("key" + finali, finali)).start();
}
// 等待所有线程完成
while (thread.activecount() > 1) {
thread.yield();
}
// 输出更新后的数据
system.out.println(map.get("key9")); // 输出 9
}
}在这个示例中,我们创建了一个 concurrenthashmap 实例,并插入了一些数据。然后,我们启动了多个线程来并发地更新数据。
由于 concurrenthashmap 是线程安全的,即使在多线程环境下,这些操作也不会导致数据不一致的问题。
注意事项
concurrenthashmap在高并发环境下比hashtable或collections.synchronizedmap有更好的性能。concurrenthashmap适用于读多写少的场景。- 在使用
concurrenthashmap时,仍然需要注意避免长时间持有迭代器,因为在迭代过程中可能会有结构性修改(如扩容)。
concurrenthashmap 是 java 并发包 java.util.concurrent 中的一个重要组件,它通过锁分段机制提供了高效的并发访问能力。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论