一、spring bean 的生命周期,如何被管理的
对于普通的 java对象,当 new的时候创建对象,当它没有任何引用的时候被垃圾回收机制回收。而由 spring ioc容器托管的对象,它们的生命周期完全由容器控制。spring 中每个 bean的生命周期如下:
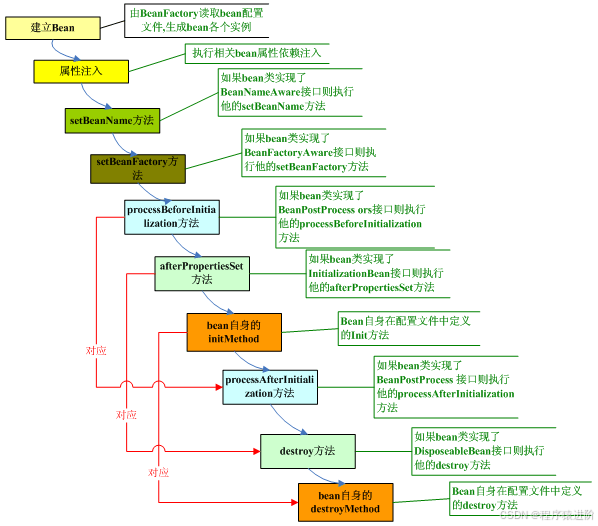
主要对几个重要的步骤进行说明:
【1】实例化 bean: 对于 beanfactory容器,当客户向容器请求一个尚未初始化的 bean时,或初始化 bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用 createbean进行实例化。对于 applicationcontext容器,当容器启动结束后,便实例化所有的单实例 bean。容器通过获取 beandefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。实例化对象被包装在 beanwrapper 对象中,beanwrapper 提供了设置对象属性的接口,从而避免了使用反射机制设置属性。通过工厂方法或者执行构造器解析执行即可:创建的对象是个空对象。
【2】设置对象属性(依赖注入): 实例化后的对象被封装在 beanwrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。紧接着获取所有的属性信息通过 populatebean(beanname,mbd,bw,pvs),spring 根据 beandefinition 中的信息进行依赖注入。并且通过 beanwrapper提供的设置属性的接口完成依赖注入。赋值之前获取所有的 instantiationawarebeanpostprocessor 后置处理器的 postprocessafterinstantiation() 第二次获取instantiationawarebeanpostprocessor 后置处理器;执行 postprocesspropertyvalues()最后为应用 bean属性赋值:为属性利用 setter 方法进行赋值 applypropertyvalues(beanname,mbd,bw,pvs)。
【3】bean 初始化: initializebean(beanname,bean,mbd)。
1)执行xxxaware 接口的方法,调用实现了beannameaware、beanclassloaderaware、beanfactoryaware接口的方法。
2)执行后置处理器之前的方法:applybeanpostprocessorsbeforeinitialization(wrappedbean, beanname)所有后置处理器的 beanpostprocessor.postprocessbeforeinitialization()。
3)执行初始化方法: initializingbean 与 init-methodinvoke 当 beanpostprocessor的前置处理完成后就会进入本阶段。先判断是否实现了 initializingbean接口的实现;执行接口规定的初始化。其次自定义初始化方法。
initializingbean 接口只有一个函数:afterpropertiesset()这一阶段也可以在 bean正式构造完成前增加我们自定义的逻辑,但它与前置处理不同,由于该函数并不会把当前 bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。若要使用它,我们需要让 bean实现该接口,并把要增加的逻辑写在该函数中。然后 spring会在前置处理完成后检测当前 bean是否实现了该接口,并执行 afterpropertiesset函数。当然,spring 为了降低对客户代码的侵入性,给 bean的配置提供了 init-method属性,该属性指定了在这一阶段需要执行的函数名。spring 便会在初始化阶段执行我们设置的函数。init-method 本质上仍然使用了initializingbean接口。
4)applybeanpostprocessorsafterinitialization(wrappedbean, beanname);执行初始化之后的后置处理器的方法。beanpostprocessor.postprocessafterinitialization(result, beanname);
【4】bean的销毁: disposablebean 和 destroy-method:和 init-method 一样,通过给 destroy-method 指定函数,就可以在bean 销毁前执行指定的逻辑。
bean 的管理就是通过 ioc容器中的 beandefinition信息进行管理的。
二、spring bean 的加载和获取过程
bean 的加载过程,主要是对配置文件的解析,并注册 bean 的过程 。
【1】根据注解或者 xml中 定义 bean 的基本信息。例如:spring-core.xml
<bean id="mybean" class="com.taobao.pojo"></bean>
【2】获取配置文件:这里使用最原始的方式获取。
resource resource = new classpathresource("spring-core.xml")【3】 利用 xmlbeanfactory 解析并注册 bean 定义:已经完成将配置文件包装成了 spring 定义的资源,并触发解析和注册。xmlbeanfactory 实际上是对 defaultlistablebeanfactory(非常核心的类,它包含了基本 ioc 容器所具有的重要功能,是一个 ioc 容器的基本实现。然后是调用了this.reader.loadbeandefinitions(resource),从这里开始加载配置文件) 和 xmlbeandefinitionreader 组合使用方式的封装,所以这里我们仍然将继续分析基于 xmlbeanfactory 加载 bean 的过程。
xmlbeanfactory beanfactory = new xmlbeanfactory(resource);
spring 使用了专门的资源加载器对资源进行加载,这里的 reader 就是 xmlbeandefinitionreader 对象,专门用来加载基于 xml 文件配置的 bean。这里的加载过程为:
①、利用 encodedresource 二次包装资源文件;
②、获取资源输入流,并构造 inputsource 对象:
// 获取资源的输入流 inputstream inputstream = encodedresource.getresource().getinputstream(); // 构造inputsource对象 inputsource inputsource = new inputsource(inputstream); // 真正开始从 xml文件中加载 bean定义 return this.doloadbeandefinitions(inputsource, encodedresource.getresource());
这里的 this.doloadbeandefinitions(inputsource, encodedresource.getresource()) 就是真正开始加载 xml 的入口,该方法源码如下:第一步获取 org.w3c.dom.document 对象,第二步由该对象解析得到 beandefinition 对象,并注册到 ioc 容器中。
protected intdoloadbeandefinitions(inputsource inputsource, resource resource){
try {
// 1. 加载xml文件,获取到对应的document(包含获取xml文件的实体解析器和验证模式)
document doc = this.doloaddocument(inputsource, resource);
// 2. 解析document对象,并注册bean
return this.registerbeandefinitions(doc, resource);
}
}③、获取 xml 文件的实体解析器和验证模式:this.doloaddocument(inputsource, resource) 包含了获取实体解析器、验证模式,以及 document 对象的逻辑,xml 是半结构化数据,xml 的验证模式用于保证结构的正确性,常见的验证模式有 dtd 和 xsd 两种。
④、加载 xml 文件,获取对应的 document 对象和验证模式与解析器,解析器就可以加载 document 对象了,这里本质上调用的是 defaultdocumentloader 的 loaddocument() 方法,源码如下:整个过程类似于我们平常解析 xml 文件的流程。
public documentloaddocument(inputsource inputsource, entityresolver entityresolver,
errorhandler errorhandler, int validationmode, boolean namespaceaware) throws exception {
documentbuilderfactory factory = this.createdocumentbuilderfactory(validationmode, namespaceaware);
documentbuilder builder = this.createdocumentbuilder(factory, entityresolver, errorhandler);
return builder.parse(inputsource);
}⑤、由 document 对象解析并注册 bean:完成了对 xml 文件的到 document 对象的解析,我们终于可以解析 document 对象,并注册 bean 了,这一过程发生在 this.registerbeandefinitions(doc, resource) 中,源码如下:
public intregisterbeandefinitions(document doc, resource resource)throwsbeandefinitionstoreexception{
// 使用defaultbeandefinitiondocumentreader构造
beandefinitiondocumentreader documentreader = this.createbeandefinitiondocumentreader();
// 记录之前已经注册的beandefinition个数
int countbefore = this.getregistry().getbeandefinitioncount();
// 加载并注册bean
documentreader.registerbeandefinitions(doc, createreadercontext(resource));
// 返回本次加载的bean的数量
return getregistry().getbeandefinitioncount() - countbefore;
}这里方法的作用是创建对应的 beandefinitiondocumentreader,并计算返回了过程中新注册的 bean 的数量,而具体的注册过程,则是由 beandefinitiondocumentreader 来完成的,具体的实现位于子类 defaultbeandefinitiondocumentreader 中:
publicvoidregisterbeandefinitions(document doc, xmlreadercontext readercontext){
this.readercontext = readercontext;
// 获取文档的root结点
element root = doc.getdocumentelement();
this.doregisterbeandefinitions(root);
}还是按照 spring 命名习惯,doregisterbeandefinitions 才是真正干活的地方,这也是真正开始解析配置的核心所在:
protectedvoiddoregisterbeandefinitions(element root){
beandefinitionparserdelegate parent = this.delegate;
this.delegate = this.createdelegate(getreadercontext(), root, parent);
// 处理profile标签(其作用类比pom.xml中的profile)
string profilespec = root.getattribute(profile_attribute);
// 解析预处理,留给子类实现
this.preprocessxml(root);
// 解析并注册beandefinition
this.parsebeandefinitions(root, this.delegate);
// 解析后处理,留给子类实现
this.postprocessxml(root);
}方法在解析并注册 beandefinition 前后各设置一个模板方法,留给子类扩展实现,而在this.parsebeandefinitions(root, this.delegate)中执行解析和注册逻辑:方法中判断当前标签是默认标签还是自定义标签,并按照不同的策略去解析。
protectedvoidparsebeandefinitions(element root, beandefinitionparserdelegate delegate){
if (delegate.isdefaultnamespace(root)) {
// 解析默认标签
nodelist nl = root.getchildnodes();
for (int i = 0; i < nl.getlength(); i++) {
node node = nl.item(i);
if (node instanceof element) {
element ele = (element) node;
if (delegate.isdefaultnamespace(ele)) {
// 解析默认标签
this.parsedefaultelement(ele, delegate);
} else {
// 解析自定义标签
delegate.parsecustomelement(ele);
}
}
}
} else {
// 解析自定义标签
delegate.parsecustomelement(root);
}
}到这里我们已经完成了静态配置到动态 beandefinition 的解析,这个时候 bean 的定义已经处于内存中。
【4】 从 ioc容器加载获取 bean:我们可以调用 beanfactory.getbean("mybean") 方法来获取目标对象。
mybean mybean = (mybean) beanfactory.getbean("mybean");到此这篇关于spring bean 的生命周期和获取方式详解的文章就介绍到这了,更多相关spring bean 生命周期内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论