要知道,锐炫a750两年多前首发的时候,还是要289美元。
锐炫b570显卡则要等到明年1月16日才会开卖,定价219美元起。

其实,lunar lake即酷睿ultra 200v系列处理器中已经率先应用xe2架构的核显,也就是锐炫140v、锐炫130v,如今终于来到了桌面独立显卡,未来还会陆续进入笔记本独立显卡、车载方案、嵌入式方案等。
intel表示,xe2架构相对于初代,重点就是提升各方面的效率,包括更高的利用率、更好的负载分配、更好的软件开销等等。
同时,xe架构诞生两年多来,intel一直在努力完善驱动、游戏的生态支持,先后迭代了50多个版本的驱动,新游戏0日支持超过120款,游戏适配优化数量也比当初增加了2.5倍。


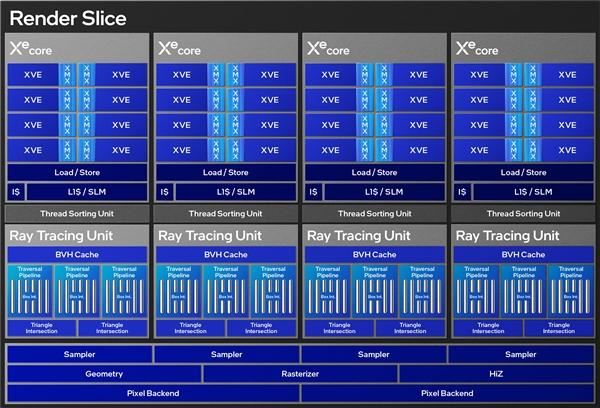
这就是xe2的整体架构图,主体依然是渲染切片,这是整个soc芯片的基本结构,配合指令前端、二级缓存构成一个整体,和第一代如出一辙,基本没啥变化。
每个渲染切片内包含4个xe核心(计算引擎)、4个光追单元,以及4个采样器、几何单元、光栅单元、hiz单元(层次z)、两个像素后端等模块。
各个部分的具体变化,下边拆开来讲。

二代xe2核心除了继续原生支持simd16指令,还增加了对simd32的支持,虽然不是原生,但执行simd32指令是没问题的,从而能够更好地分配计算资源,还支持64位原子操作。
每个xe核心内部,包含8个512位的矢量引擎(xve)、8个2048位的xmx引擎,比上代减少了足足一半,可能调度效率会更高、更灵活。
这一次,intel为每个xe核心加入了多达256kb容量的一级缓存、本地共享缓存(slm),大大减轻了对二级缓存的依赖。

xve矢量引擎除了支持simd16/simd32,还支持矩阵扩展,包括int2、int4、int8、fp16、bf16、tf32等数据类型,其中tf32是针对ai优化的数据格式还扩展了math、fp64支持。
另外,它还支持三路并发,包括fp、int/em、xmx,指令调度和执行效率更高。
对比初代,xve引擎现在更小巧(基本可以视为砍半),应该也会更灵活。

光追部分,intel也做了大刀阔斧地改进,整体结构没太大变化,但是规模和性能高得多,比如遍历流水线从2条增至3条、方盒相交增大1.5倍、三角形相交增大2倍、bvh(包围盒层次结构)缓存增大2倍来到16kb。
这样的规模当然远远没法和nvidia相比,甚至不如amd,但提升也是相当明显的,应该能够达到基本可用的水平,当然更有赖于游戏的适配和优化。

媒体引擎包含两个相同的多媒体解码器(mfx),但注意它和lunar lake里集成的核显媒体引擎略有不同,没有xmx硬件编解码单元,因此不支持vvc(h.266)硬解码。

这就是bmg-g21,二代锐炫显卡首发的gpu核心芯片。
它总共有5个渲染切片、20个xe2核心、20个光追单元、160个xmx引擎、20个纹理采样器、10个像素后端,以及2个多格式x编解码器,还有多达18mb二级缓存、192位显存。
各家的gpu架构设计不同,所以核心规模不具备直接可比性,但如果将这些与nvidia gpu类比,那就相当于80个rop光栅单元、160个tmu纹理单元。
这是因为,纹理采样器转换为tmu的比例是1:8,像素后端与rop的转换比例同样是1:8。
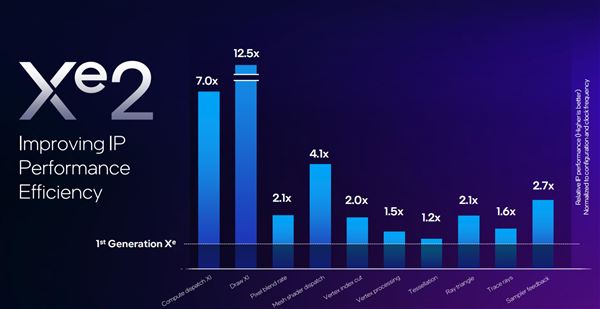
按照intel的首发,经过优化的第二代xe核心,性能提高了70%,能效提高了50%。
发表评论