前言
在生产实践中,你的mysql数据库可能面临下面这些情况:
- 不可抗力的因素,数据库所在服务器被回收,或者服务器磁盘损坏,数据库必须得迁移?
- 单点数据库读写压力越来越大,需要扩展一个或多个节点分摊读写压力?
- 单表数据量太大了,需要进行水平或垂直拆分怎么搞?
- 数据库需要从mysql迁移到其他数据库,比如pg,ob…
以上的这些场景,对于不少同学来讲,或多或少的在所处的业务中可能会涉及到,没有碰到还好,一旦发生了这样的问题,该如何处理呢?在这里我通过提供一个思路来解决单表数据量太大了,进行水平拆分,将历史数据归档保证热点数据查询。
归档流程示意图
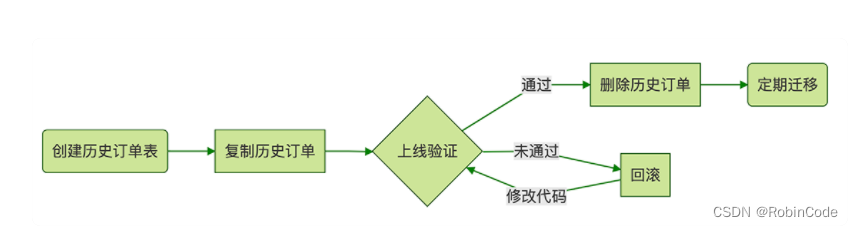
实现步骤
controller 层
@slf4j
@restcontroller
@requestmapping("/backdoor")
public class cleanhistorydatacontroller {
@autowired
private icleanhistorydataservice cleanhistorydataservice;
/**
* 把指定过期时间的订单表数据迁移到历史表中
*/
@postmapping("/cleanbytablenameandendtime")
public resp<string> cleanbytablenameandendtime(@requestbody cleantablereq cleantablereq) {
try {
cleantablebo cleantablebo = objectutils.mapvalue(cleantablereq, cleantablebo.class);
cleanhistorydataservice.cleanbytablenameandendtime(cleantablebo);
} catch (exception e) {
log.error(cleantablereq.gettablename() + " 数据迁移异常", e);
}
return resp.success("success");
}
}
service 层
public interface icleanhistorydataservice {
void cleanhistorytabledata();
}
import com.alibaba.fastjson.jsonobject;
import com.photon.union.risk.clean.service.icleanhistorydataservice;
import com.photon.union.risk.repo.mapper.clean.masterdbmapper;
import lombok.extern.slf4j.slf4j;
import org.apache.commons.collections4.collectionutils;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.service;
import org.springframework.util.stopwatch;
import java.util.list;
import java.util.stream.collectors;
/**
* @author robin
*/
@service
@slf4j
public class cleanhistorydataservice implements icleanhistorydataservice {
@autowired
private masterdbmapper masterdbmapper;
@override
public void cleanhistorytabledata() {
stopwatch stopwatch = new stopwatch();
stopwatch.start();
int logint = 0;
long startid = 0l;
while (true) {
logint ++;
list<jsonobject> hashmaplist = masterdbmapper.selecthistorytabledataids(startid);
if (collectionutils.isempty(hashmaplist)){
break;
}
list<long> allids = hashmaplist.stream().map(o -> o.getlong("id")).collect(collectors.tolist());
startid = allids.get(allids.size()-1);
if (logint % 100 == 0 ){
log.info("id 已经处理到-->" + allids.get(allids.size()-1));
}
try {
// 往归档历史数据表写入数据
masterdbmapper.insertoldhistorytabledatabatchbyids(allids);
// 把归档的数据从目前业务表中删除
masterdbmapper.deletehistorytabledatabatchbyids(allids);
}catch (exception e){
log.error("数据迁移异常,ids:{}", allids, e);
}
}
stopwatch.stop();
log.info("数据迁移到历史表处理完成时间:{}s", (long)stopwatch.gettotaltimeseconds());
}
}
mapper 层
import com.alibaba.fastjson.jsonobject;
import org.apache.ibatis.annotations.param;
import org.springframework.stereotype.repository;
import java.util.list;
/**
* @author robin
*/
@repository
public interface masterdbmapper {
list<jsonobject> selecthistorytabledataids( @param("id") long startid);
void insertoldhistorytabledatabatchbyids(@param("ids") list<long> allids);
void deletehistorytabledatabatchbyids(@param("ids") list<long> allids);
}
sql mapper
<?xml version="1.0" encoding="utf-8"?>
<!doctype mapper public "-//mybatis.org//dtd mapper 3.0//en" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.test.masterdbmapper">
<insert id="insertoldhistorytabledatabatchbyids">
insert ignore into t_order_old
select null,order_no,created_at
from t_order where id in
<foreach collection="ids" item="item" open="(" close=")" separator=",">
#{item}
</foreach>
</insert>
<delete id="deletehistorytabledatabatchbyids">
delete from t_order where id in
<foreach collection="ids" item="item" open="(" close=")" separator=",">
#{item}
</foreach>
</delete>
<select id="selecthistorytabledataids" resulttype="com.alibaba.fastjson.jsonobject">
select id from t_order
where id > #{id} and created_at lt;= date_sub(now(), interval 6 month)
order by id limit 1000
</select>
</mapper>
核心说明
- 根据 t_order订单表结构创建 t_order_old历史订单表用于历史数据备份存放。
- 整个流程基于主键 id 处理,避免慢 sql 产生,做到不影响当前线上业务处理。
- 1000 条记录一个批次,避免长期抢占锁资源,同时每个批次执行不影响下个批次处理,出现异常后,打印 error 日志再人工跟进处理。
总结
上述方案是处理历史数据归档的一种方式,到此这篇关于mysql大表数据归档实现方案的文章就介绍到这了,更多相关mysql大表数据归档内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论