一、关于java.util包
1.1简介
java.util 包是java标准类库中的一个非常重要的组成部分,它提供了一系列对程序开发非常有用的类和接口。这个包主要包含集合框架、日期时间类、事件模型、随机数生成器以及其他实用工具类。
1.2常用类及接口
集合框架 - 集合框架是
java.util包中最重要的部分之一,它提供了一系列的数据结构和算法,帮助开发者存储和操作数据集合。collection - 集合框架的根接口,代表一组对象,这些对象称为元素。list - 有序集合,每个元素都有其在集合中的特定位置。set - 不允许重复元素的集合。map - 键值对的集合,也称为字典或哈希表。arraylist - 实现了list接口的动态数组。linkedlist - 实现了list接口的双向链表。hashset - 实现了set接口的哈希表集合。linkedhashset - 继承自hashset,维护元素插入顺序的集合。treeset - 实现了set接口的基于红黑树的集合,元素按自然顺序或自定义顺序排序。hashmap - 实现了map接口的哈希表。linkedhashmap - 继承自hashmap,维护元素插入顺序或访问顺序的映射。treemap - 实现了map接口的基于红黑树的映射,键按自然顺序或自定义顺序排序。
日期时间类 - 提供了操作日期和时间的类。
date - 表示特定的瞬间,精确到毫秒。calendar - 可以用于日期的计算,比如添加或减少天数、获取星期等。timezone - 表示时区。locale - 表示特定的语言、国家和区域的设置。
事件模型 - 用于处理事件和监听器模式。
eventobject - 所有事件的超类。eventlistener - 所有事件监听器接口的标记接口。eventsource - 能够生成事件的对象。
随机数生成器 - 提供随机数生成的功能。
random - 基于线性同余生成器的随机数生成器。java.security.securerandom - 提供更安全的随机数生成。
其他实用工具类 - 提供了一系列静态方法,用于执行各种任务。
arrays - 提供静态方法来操作数组,如排序、搜索等。collections - 提供静态方法来操作集合,如排序、搜索等。objects - 提供静态方法来操作对象,如空安全的比较、计算哈希码等。timer - 可以调度任务在将来的某个时间点执行。uuid - 用于生成uuid(通用唯一标识符)。
1.3时间
1.3.1date类
简介
java.util.date 类在java中用于表示特定的瞬间,精确到毫秒。
构造方法
date类提供了多个构造方法,其中比较常用的有:
date(): 创建一个表示当前日期和时间的date对象。date(long date): 根据指定的毫秒数创建一个date对象,该毫秒数表示自1970年1月1日00:00:00 gmt以来的毫秒数。
方法
gettime(): 返回自1970年1月1日00:00:00 gmt以来的毫秒数。tostring(): 将date对象转换为string类型。before(date when): 比较两个日期,如果当前日期早于参数日期,则返回true。after(date when): 比较两个日期,如果当前日期晚于参数日期,则返回true。
示例
import java.util.date;
public class main {
public static void main(string[] args) {
// 创建表示当前日期和时间的date对象
date currentdate = new date();
system.out.println("当前日期和时间:" + currentdate);
// 创建一个指定日期和时间的date对象
date specificdate = new date(1630454400000l); // 对应2022年9月2日12:00:00
system.out.println("指定日期和时间:" + specificdate);
// 判断日期先后
if (currentdate.after(specificdate)) {
system.out.println("当前日期晚于指定日期");
} else {
system.out.println("当前日期早于指定日期");
}
}
}
1.3.2timezone类
简介
在java中,timezone类用于表示时区信息,并提供了对时区进行操作的方法。它可以帮助我们在处理日期和时间时,将时间转换为特定时区下的时间,并进行时区之间的转换。
构造方法
timezone类是一个抽象类,不能直接实例化,但它提供了一些静态方法来获取timezone对象:
gettimezone(string id): 返回指定id对应的timezone对象,例如:“gmt+08:00”。getdefault(): 返回默认的timezone对象,通常是系统默认的时区。
方法
timezone类提供了一些常用的方法,包括但不限于:
getdisplayname(): 返回时区的名称。getid(): 返回时区的id。getoffset(long date): 返回指定日期的偏移量,单位为毫秒。indaylighttime(date date): 判断指定日期是否在夏令时时段内。getavailableids(): 返回所有可用的时区id数组。
示例
import java.util.date;
import java.util.timezone;
public class main {
public static void main(string[] args) {
// 获取默认的时区
timezone defaulttimezone = timezone.getdefault();
system.out.println("默认时区:" + defaulttimezone.getdisplayname());
// 获取指定id的时区
timezone gmt8timezone = timezone.gettimezone("gmt+08:00");
system.out.println("gmt+08:00时区:" + gmt8timezone.getdisplayname());
// 进行时区转换
date currentdate = new date();
system.out.println("当前日期和时间:" + currentdate);
system.out.println("当前日期和时间在gmt+08:00时区:" + formatdateintimezone(currentdate, gmt8timezone));
}
// 将日期转换为指定时区下的日期
private static date formatdateintimezone(date date, timezone timezone) {
long timeinutc = date.gettime() - timezone.getrawoffset();
return new date(timeinutc);
}
}
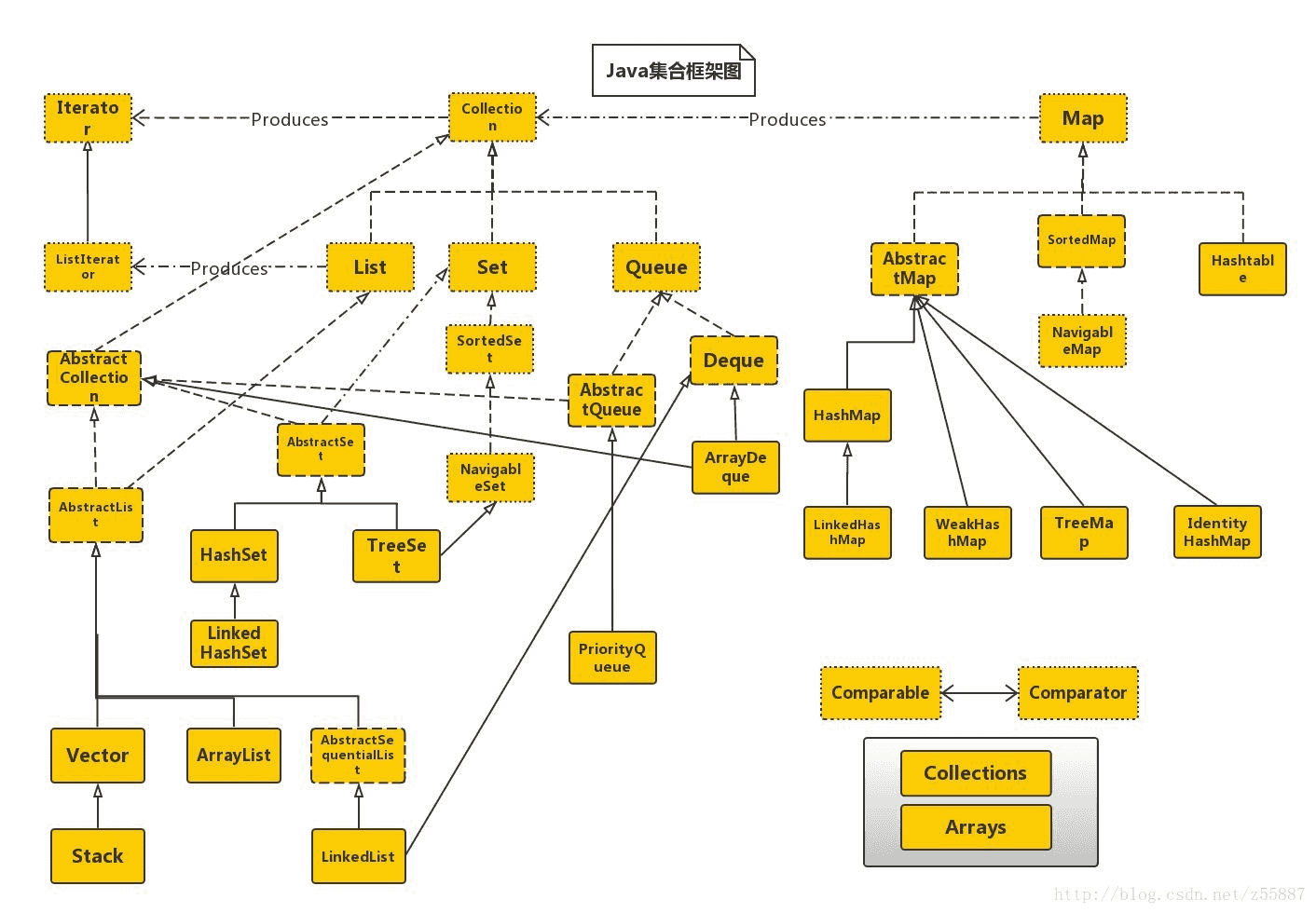
1.4集合框架
集合框架 - 集合框架是java.util包中最重要的部分之一,它提供了一系列的数据结构和算法,帮助开发者存储和操作数据集合。
collection - 集合框架的根接口,代表一组对象,这些对象称为元素。list - 有序集合,每个元素都有其在集合中的特定位置。set - 不允许重复元素的集合。map - 键值对的集合,也称为字典或哈希表。arraylist - 实现了list接口的动态数组。linkedlist - 实现了list接口的双向链表。hashset - 实现了set接口的哈希表集合。linkedhashset - 继承自hashset,维护元素插入顺序的集合。treeset - 实现了set接口的基于红黑树的集合,元素按自然顺序或自定义顺序排序。hashmap - 实现了map接口的哈希表。linkedhashmap - 继承自hashmap,维护元素插入顺序或访问顺序的映射。treemap - 实现了map接口的基于红黑树的映射,键按自然顺序或自定义顺序排序。
在之前章节有详细介绍,这里不再赘述
1.5接口
1.5.1comparator
简介
java.util.comparator 接口是一个用于定义对象比较规则的接口。它允许开发者自定义对象比较逻辑,这在排序集合或者对对象进行排序操作时非常有用。comparator 接口提供了一种灵活的比较机制,使得可以对任何对象进行排序,而不仅仅是实现了特定比较方法的对象。
方法
reversed(): 返回与当前比较器相反的比较器(逆序排列)。thencomparing(): 返回一个复合比较器,用于对两个对象进行多重比较。nullsfirst(): 返回一个可将null元素排在非null元素之前的比较器。nullslast(): 返回一个可将null元素排在非null元素之后的比较器。compare(t o1, t o2) - 比较两个对象
o1 和o2。返回值是一个整数,它表示第一个参数相对于第二个参数是小于、等于还是大于:如果
o1 小于o2,返回负整数;如果
o1 等于o2,返回零;如果
o1 大于o2,返回正整数。
示例
import java.util.arraylist;
import java.util.collections;
import java.util.comparator;
import java.util.list;
class student {
private int id;
private string name;
public student(int id, string name) {
this.id = id;
this.name = name;
}
public int getid() {
return id;
}
public string getname() {
return name;
}
}
public class main {
public static void main(string[] args) {
list<student> studentlist = new arraylist<>();
studentlist.add(new student(1, "alice"));
studentlist.add(new student(2, "bob"));
studentlist.add(new student(3, "charlie"));
// 使用comparator进行排序
collections.sort(studentlist, comparator.comparing(student::getname));
// 输出排序后的结果
for (student student : studentlist) {
system.out.println("id: " + student.getid() + ", name: " + student.getname());
}
}
}
在这个示例中,首先定义了一个student类,然后创建了一个包含student对象的列表studentlist。接着,我们使用comparator.comparing方法根据学生姓名对列表进行排序,最终输出排序后的结果。
1.5.2iterator
简介
在java中,iterator接口提供了一种用于遍历集合元素的统一方式。通过实现iterator接口,我们可以对集合中的元素进行迭代访问,而不需要了解集合的具体实现方式。
方法
boolean hasnext(): 如果仍有元素可以迭代,则返回true,否则返回false。e next(): 返回迭代的下一个元素。void remove(): 从迭代器指向的集合中移除迭代器最后返回的元素(可选操作)。
示例
import java.util.arraylist;
import java.util.iterator;
import java.util.list;
public class main {
public static void main(string[] args) {
list<string> names = new arraylist<>();
names.add("alice");
names.add("bob");
names.add("charlie");
// 获取iterator对象并进行迭代
iterator<string> iterator = names.iterator();
while (iterator.hasnext()) {
string name = iterator.next();
system.out.println(name);
}
}
}
在这个示例中,首先创建了一个包含字符串元素的arraylist names。然后,我们通过调用names的iterator()方法获得了一个iterator对象,并使用while循环和next()方法对集合进行迭代访问,最终输出了每个元素的值。这种方式能够适用于任何实现了iterable接口的集合类,如list、set等。
1.5.3eventlistener
简介
在java中,eventlistener接口是用于实现事件监听器的接口,用于处理各种类型的事件。通过实现eventlistener接口,可以创建自定义的事件监听器,用于监听和响应特定类型的事件。
方法
eventlistener 接口本身不定义任何方法,但是它有很多子接口,这些子接口定义了事件处理方法。例如:
actionlistener:用于处理动作事件,如按钮点击。changelistener:用于监听changeevent,当事件源的状态发生变化时触发。mouselistener:用于处理鼠标事件,如鼠标点击、移动等。mousemotionlistener:用于处理鼠标移动和拖动事件。keylistener:用于处理键盘事件,如按键和释放。
示例
import java.awt.event.mouseevent;
import java.awt.event.mouselistener;
public class mymouselistener implements mouselistener {
@override
public void mouseclicked(mouseevent e) {
system.out.println("mouse clicked at: (" + e.getx() + ", " + e.gety() + ")");
}
@override
public void mousepressed(mouseevent e) {
// 实现鼠标按下时的处理逻辑
}
@override
public void mousereleased(mouseevent e) {
// 实现鼠标释放时的处理逻辑
}
@override
public void mouseentered(mouseevent e) {
// 实现鼠标进入组件时的处理逻辑
}
@override
public void mouseexited(mouseevent e) {
// 实现鼠标退出组件时的处理逻辑
}
}
在这个示例中,创建了一个名为mymouselistener的类,实现了mouselistener接口,该接口定义了处理鼠标事件的方法。我们重写了mouselistener接口中的几个方法,比如mouseclicked,在该方法中实现了鼠标点击事件发生时的逻辑。通过这种方式,我们可以自定义事件监听器来响应特定的事件。
1.6工具类
1.6.1uuid类
简介
java.util.uuid 类是用于生成通用唯一标识符(uuid)的工具类。uuid是一种标准化的32位字符格式,用于在分布式系统中唯一标识信息。uuid的设计目的是在所有计算机和系统上都能生成高度唯一的标识符,即使在不同的时间和空间中也是如此。
构造方法
uuid类提供了两种构造方法:
uuid(long mostsignificantbits, long leastsignificantbits): 使用指定的最高有效位和最低有效位创建一个uuid对象。uuid(string name): 根据指定的字符串名称创建一个uuid对象。该字符串必须遵循uuid的标准格式,如 “550e8400-e29b-41d4-a716-446655440000”。- uuid() - 生成一个随机生成的uuid。
uuid randomuuid = new uuid();
方法
static uuid randomuuid(): 静态方法,用于生成一个随机的uuid。string tostring(): 将uuid转换为字符串表示形式。int hashcode(): 返回此uuid的哈希码值。boolean equals(object obj): 比较两个uuid对象是否相等。
示例
import java.util.uuid;
public class main {
public static void main(string[] args) {
// 生成一个随机的uuid
uuid uuid = uuid.randomuuid();
// 将uuid转换为字符串表示形式
string uuidstring = uuid.tostring();
system.out.println("random uuid: " + uuidstring);
}
}
在这个示例中,通过调用uuid.randomuuid()方法生成一个随机的uuid对象,然后通过调用tostring()方法将其转换为字符串表示形式,并最终输出到控制台上。这样我们就可以生成一个唯一的标识符,用于在系统中标识对象或实体。
1.6.2random类
简介
java.util.random 类是java标准库中提供的一个随机数生成器。它用于生成伪随机数流,这些随机数在足够长的时间内看起来是随机的,但实际上是可以重现的,因为它们是由一个初始种子值(seed)确定的。
构造方法
random(): 创建一个新的随机数生成器。random(long seed): 使用指定的种子创建一个新的随机数生成器。使用相同的种子创建的random对象将生成相同的随机数序列。
方法
int nextint(): 返回一个随机的int值。int nextint(int bound): 返回一个大于等于0且小于bound的随机int值。double nextdouble(): 返回一个随机的double值。void nextbytes(byte[] bytes): 生成随机字节并将其放入提供的byte数组中。boolean nextboolean(): 返回一个随机的boolean值。
示例
import java.util.random;
public class randomexample {
public static void main(string[] args) {
// 使用默认构造方法创建random对象
random random = new random();
// 生成一个随机整数
int randomint = random.nextint();
system.out.println("random integer: " + randomint);
// 生成一个0到99之间的随机整数
int randomintwithinrange = random.nextint(100);
system.out.println("random integer within range (0-99): " + randomintwithinrange);
// 生成一个随机double值
double randomdouble = random.nextdouble();
system.out.println("random double: " + randomdouble);
// 生成一个随机float值
float randomfloat = random.nextfloat();
system.out.println("random float: " + randomfloat);
// 生成一个随机long值
long randomlong = random.nextlong();
system.out.println("random long: " + randomlong);
// 生成一个随机boolean值
boolean randomboolean = random.nextboolean();
system.out.println("random boolean (true or false): " + randomboolean);
// 使用自定义种子值创建random对象
random randomwithseed = new random(123456l);
// 再次生成随机整数,由于种子值相同,结果也将相同
int samerandomint = randomwithseed.nextint();
system.out.println("same random integer with seed 123456: " + samerandomint);
// 生成一个随机高斯分布值
double randomgaussian = random.nextgaussian();
system.out.println("random gaussian (normal distribution) value: " + randomgaussian);
}
}
在这个示例中,首先创建了一个默认的 random 对象,并使用它来生成不同类型的随机数。 接着,我们创建了一个带有自定义种子值的 random 对象,并展示了如何通过指定种子值来重现相同的随机数序列。 最后,我们打印了生成的随机数,展示了 random 类的各种用途。
1.6.3scanner类
简介
在java中,scanner类是用于读取用户输入的一个方便的类,它可以从标准输入流(如键盘输入)、文件或字符串中获取输入数据。scanner类提供了多种方法来解析基本数据类型和字符串。
构造方法
scanner(inputstream source): 通过指定输入流创建一个scanner对象,通常用于从标准输入流(system.in)读取用户输入。scanner(file source): 通过指定文件创建一个scanner对象,用于从文件中读取数据。scanner(string source): 通过指定字符串创建一个scanner对象,用于从字符串中读取数据。
方法
int nextint(): 读取下一个输入项并将其解释为int类型。double nextdouble(): 读取下一个输入项并将其解释为double类型。string nextline(): 读取下一行输入。boolean hasnext(): 检查是否还有输入项可读。void close(): 关闭scanner对象。
示例
import java.util.scanner;
public class scannerexample {
public static void main(string[] args) {
// 创建scanner实例,使用system.in作为输入源
scanner scanner = new scanner(system.in);
system.out.println("请输入一个整数:");
int integer = scanner.nextint();
system.out.println("您输入的整数是:" + integer);
system.out.println("请输入一个浮点数:");
double doublevalue = scanner.nextdouble();
system.out.println("您输入的浮点数是:" + doublevalue);
system.out.println("请输入一个布尔值(true/false):");
boolean booleanvalue = scanner.nextboolean();
system.out.println("您输入的布尔值是:" + booleanvalue);
system.out.println("请输入一个字符串:");
string string = scanner.nextline();
system.out.println("您输入的字符串是:" + string);
// 关闭scanner实例
scanner.close();
}
}
在这个示例中,首先创建了一个 scanner 实例,它默认使用 system.in 作为输入源。 接着,我们使用 nextint()、nextdouble()、nextboolean() 和 nextline() 方法从用户那里读取不同类型的输入,并打印出来。 最后,我们调用 close() 方法关闭 scanner 实例,释放与它关联的资源。
1.7java.util.concurrent包
1.7.1简介
java.util.concurrent 包提供了在并发编程中使用的工具类和框架。它包含了一系列用于处理并发任务的实用工具,使得在多线程环境中编写高效、安全的代码变得更加简单。
以下是 java.util.concurrent 包中一些常用的类和接口:
- executor 框架:包括 executor、executorservice 和 scheduledexecutorservice 接口,以及 executors 工厂类。这些类允许你实现异步执行任务和控制执行过程。
- 线程安全集合:java.util.concurrent 包中提供了一系列线程安全的集合类,如 concurrenthashmap、copyonwritearraylist、copyonwritearrayset 等。这些集合类能够在多线程环境中安全地进行读写操作,避免了传统集合类在并发情况下可能出现的线程安全问题。
- 同步器和锁:该包中还包含了一些同步器和锁的实现,如 reentrantlock、readwritelock、condition 等,它们提供了更灵活的锁机制,能够满足不同的并发控制需求。
- 并发工具类:java.util.concurrent 包还提供了一些并发编程中常用的工具类,比如 countdownlatch、cyclicbarrier、semaphore 等。这些工具类可以帮助协调多个线程之间的执行顺序和资源的访问。
总的来说,java.util.concurrent 包为 java 程序员提供了丰富的并发编程工具,帮助开发者更加轻松地处理多线程编程中的挑战,提高了并发程序的性能和可靠性。通过合理地利用这些工具和框架,可以写出高效、可靠的并发程序。
1.7.2completablefuture类
简介
在java中,completablefuture类提供了一种异步编程的方式,可以用于实现异步操作和构建复杂的异步流水线。它是java 8引入的一个重要特性,用于简化并发编程。
java.util.concurrent 包中的 completablefuture 类是 java 8 引入的一个类,用于支持异步编程和构建异步操作链。completablefuture 提供了一种简洁而强大的方式来处理异步任务的结果,以及对多个异步任务进行组合、串联和并发控制。
以下是 completablefuture 类的一些主要特点和用法:
- 异步操作:completablefuture 可以表示一个异步计算的结果,通过 completablefuture 的方法可以注册回调函数,在异步任务执行完成后自动触发回调函数处理结果。
- 组合操作:completablefuture 支持对多个 completablefuture 进行组合操作,包括 thencombine、thencompose、thenapplyasync 等方法,可以串联多个异步任务,形成复杂的异步操作链。
- 异常处理:completablefuture 允许你通过 exceptionally 或 handle 方法来处理异步任务中产生的异常,使得异常处理变得更加灵活。
- 并发控制:completablefuture 提供了一些方法来实现并发控制,比如 allof、anyof 等,能够控制多个 completablefuture 的执行顺序和并发度。
- 超时处理:completablefuture 支持设置超时时间,并在超时时执行特定的操作,避免任务长时间阻塞。
使用 completablefuture 可以简化异步编程的复杂性,让开发者能够更加方便地处理异步任务的结果和操作。通过链式调用和组合不同的 completablefuture 对象,可以构建出复杂的异步任务流水线,实现高效的并发编程。
总的来说,completablefuture 是 java 中处理异步编程的重要工具,它提供了丰富的方法和功能,使得异步任务的管理和处理变得更加简单和高效。
构造方法
completablefuture类有多个静态工厂方法来创建completablefuture对象,其中最常用的包括:
static completablefuture<void> runasync(runnable runnable): 异步执行指定的runnable任务,并返回一个completablefuture对象。static <u> completablefuture<u> supplyasync(supplier<u> supplier): 异步执行指定的supplier任务,并返回一个completablefuture对象,该任务产生一个结果。
方法
completablefuture<t> thenapply(function<? super t,? extends u> fn): 当前completablefuture计算完成时,对其结果执行给定的函数。completablefuture<t> thencompose(function<? super t,? extends completionstage<u>> fn): 当前completablefuture计算完成时,对其结果执行给定的函数,该函数返回另一个completablefuture。completablefuture<t> exceptionally(function<throwable,? extends t> fn): 当当前completablefuture计算完成或者抛出异常时,执行给定的函数。static completablefuture<void> allof(completablefuture<?>... cfs): 等待所有的completablefuture对象执行完毕。
示例
import java.util.concurrent.completablefuture;
import java.util.concurrent.executionexception;
public class main {
public static void main(string[] args) throws executionexception, interruptedexception {
// 创建一个completablefuture对象,异步执行一个简单的任务
completablefuture<void> future = completablefuture.runasync(() -> {
system.out.println("async task running in the background...");
try {
thread.sleep(2000); // 模拟耗时操作
} catch (interruptedexception e) {
e.printstacktrace();
}
system.out.println("async task completed.");
});
// 等待异步任务执行完毕
future.get(); // 这里会阻塞直到任务完成
system.out.println("main thread continues to run...");
}
}
在这个示例中,首先使用completablefuture.runasync()方法创建了一个completablefuture对象,异步执行一个简单的任务。然后使用get()方法等待异步任务执行完毕。在主线程中,我们打印了一条消息表明主线程继续执行。这样我们就可以利用completablefuture类方便地实现异步编程。
1.8java.util.stream包
1.8.1简介
java.util.stream 包是 java 8 引入的用于支持流式处理(stream api)的包。该包提供了一组类和接口,用于对集合数据进行函数式操作,以实现更简洁、可读性更强的代码。
以下是 java.util.stream 包中一些常用的类和接口:
- stream:
stream 接口代表一个元素序列,可以支持各种操作来处理这个序列,如过滤、映射、归约等。 - collectors:
collectors 类包含了一系列静态工厂方法,用于生成常见的收集器实例,例如将流元素收集到列表、集合、映射等数据结构中。 - intstream, longstream, doublestream:这些接口分别表示原始类型的流,提供了针对基本数据类型的特定操作。
- parallelstream:
parallelstream 类支持并行流操作,可以加速处理大量数据的操作。
通过使用 java.util.stream 包中提供的类和接口,开发者可以利用流式处理来简化集合数据的操作、提高代码的可读性,并且能够更方便地进行并行处理以提升性能。这些功能使得 java 编程变得更加灵活和强大。
1.8.2collectors类
简介
collectors 类是 java 中 java.util.stream 包中的一个工具类,提供了一系列静态工厂方法,用于生成常见的收集器实例,以便在流式处理中对元素进行汇总和归约操作。
通过 collectors 类,可以方便地将流中的元素收集到不同类型的数据结构中,比如集合(list、set)、映射(map)、字符串(joining)、统计信息(summarizingint、summarizingdouble 等)等。这些收集器可以帮助简化代码,并支持并行处理以提高性能。
构造方法
在 java 中,collectors 类是一个工具类,它提供了一系列静态工厂方法来创建不同类型的收集器。因此,collectors 类并没有公开的构造方法。相反,它提供了诸如 tolist()、toset()、tomap() 等静态方法,用于创建对应的收集器实例。
这些静态方法返回的是 collector 接口的实例,collector 接口定义了用于执行归约操作的方式,并可用于对输入的元素进行汇总。collector 接口中有几个重要的方法,包括 supplier()、accumulator()、combiner() 和 finisher(),它们定义了收集器的行为和属性。
因此,我们通常不需要直接构造 collectors 类的实例,而是通过调用其提供的静态工厂方法来获取特定类型的收集器。这样可以更方便地对流中的元素进行汇总和归约操作。
方法
一些常用的 collectors 方法包括:
tolist(): 将流中的元素收集到一个 list 中。toset(): 将流中的元素收集到一个 set 中。tomap(keymapper, valuemapper): 将流中的元素根据 keymapper 和 valuemapper 转换为 map。joining(): 将流中的元素连接成一个字符串。groupingby(classifier): 根据分类函数对流中的元素进行分组。summarizingint(), summarizingdouble(), summarizinglong(): 用于统计流中元素的汇总信息,如 count、sum、min、max、average 等。- 将流中的元素收集到一个 list 中:
list<string> words = arrays.aslist("apple", "banana", "orange", "grape");
list<string> collectedlist = words.stream()
.collect(collectors.tolist());
system.out.println(collectedlist);
- 将流中的元素连接成一个字符串:
list<string> words = arrays.aslist("apple", "banana", "orange", "grape");
string concatenatedstring = words.stream()
.collect(collectors.joining(", "));
system.out.println(concatenatedstring);
- 根据字符串长度将元素分组:
list<string> words = arrays.aslist("apple", "banana", "orange", "grape");
map<integer, list<string>> groupedbylength = words.stream()
.collect(collectors.groupingby(string::length));
system.out.println(groupedbylength);
- 计算元素的数量、总和、最小值、最大值和平均值:
list<integer> numbers = arrays.aslist(1, 2, 3, 4, 5);
intsummarystatistics stats = numbers.stream()
.collect(collectors.summarizingint(integer::intvalue));
system.out.println("count: " + stats.getcount());
system.out.println("sum: " + stats.getsum());
system.out.println("min: " + stats.getmin());
system.out.println("max: " + stats.getmax());
system.out.println("average: " + stats.getaverage());
这些示例展示了如何使用 collectors 类中的一些常见方法来对流进行汇总操作。您可以根据具体的需求选择合适的收集器,并结合流操作来实现各种数据处理功能。
示例
import java.util.arrays;
import java.util.list;
import java.util.map;
import java.util.set;
import java.util.stream.collectors;
public class main {
public static void main(string[] args) {
// 创建一个包含一些整数的list
list<integer> numbers = arrays.aslist(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 使用collectors.tolist()方法将stream中的元素收集到list中
list<integer> evennumbers = numbers.stream()
.filter(num -> num % 2 == 0)
.collect(collectors.tolist());
system.out.println("even numbers: " + evennumbers);
// 使用collectors.toset()方法将stream中的元素收集到set中
set<integer> oddnumbers = numbers.stream()
.filter(num -> num % 2 != 0)
.collect(collectors.toset());
system.out.println("odd numbers: " + oddnumbers);
// 使用collectors.tomap()方法将stream中的元素收集到map中
map<integer, string> numbermap = numbers.stream()
.collect(collectors.tomap(
num -> num,
num -> "number: " + num
));
system.out.println("number map: " + numbermap);
}
}
在这个示例中,首先创建了一个包含一些整数的list。然后使用stream api对这个list进行操作,并利用collectors类的方法将stream中的元素收集到不同的数据结构中,包括list、set和map。最后我们打印出了收集到的结果。
1.8.3stream类
简介
在 java 中,stream 是 java 8 引入的一个全新的抽象概念,它提供了一种高效且功能强大的数据处理方式。stream 可以让你以一种声明式的方式处理集合数据,这种方式更加简洁、灵活,并且可以充分利用多核处理器的优势。
简单来说,stream 提供了一种对集合进行批量操作的高级抽象,它可以让你通过一系列的操作(如过滤、映射、排序、归约等)来处理集合中的元素,而无需写显式的循环。
构造方法
从集合创建
list<string> list = arrays.aslist("a", "b", "c");
stream<string> streamfromlist = list.stream(); // 从list创建stream
stream<string> parallelstreamfromlist = list.parallelstream(); // 从list创建并行stream
从数组创建
string[] array = {"a", "b", "c"};
stream<string> streamfromarray = arrays.stream(array); // 从数组创建stream
使用stream.of()
stream<string> streamofelements = stream.of("a", "b", "c"); // 使用stream.of()创建stream
使用stream.iterate()
stream<integer> streamiterate = stream.iterate(0, n -> n + 2).limit(5); // 使用stream.iterate()创建stream
使用stream.generate()
stream<double> streamgenerate = stream.generate(math::random).limit(3); // 使用stream.generate()创建stream
方法
stream 类提供了丰富的方法来支持对集合数据的高级操作,这些方法可以分为中间操作和终端操作两种类型。中间操作用于构建 stream 流水线,而终端操作则触发实际的处理过程并产生结果。以下是一些常用的 stream 方法:
中间操作:
- filter(predicate) :根据给定的条件过滤元素。
- map(function) :将元素按照指定规则转换。
- flatmap(function) :将流中的每个元素都转换成另一个流,然后把所有流连接成一个流。
- distinct() :去除流中重复的元素。
- sorted() :对流进行排序。
- limit(long maxsize) :截断流,使其最多只包含指定数量的元素。
- skip(long n) :跳过指定数量的元素,返回剩余的元素。
终端操作:
- foreach(consumer) :对流中的每个元素执行指定操作。
- collect(collector) :将流中的元素累积成一个结果容器,如 list、map 等。
- reduce(binaryoperator) :用指定的二元运算符对流中的元素进行归约操作,得到一个最终结果。
- count() :返回流中元素的总个数。
- anymatch(predicate) :检查流中是否至少有一个元素满足给定条件。
- allmatch(predicate) :检查流中是否所有元素都满足给定条件。
- nonematch(predicate) :检查流中是否没有元素满足给定条件。
- findfirst() :返回流中的第一个元素。
- findany() :返回流中的任意一个元素。
除了上述方法之外,stream 还提供了很多其他的操作,这些方法可以根据具体的需求进行组合和使用,以实现对集合数据的灵活处理。
示例
import java.util.arrays;
import java.util.list;
public class streamexample {
public static void main(string[] args) {
list<string> names = arrays.aslist("alice", "bob", "charlie", "david", "emma");
// 创建一个 stream 对象,并通过 filter 操作筛选出包含字母“a”的名字
names.stream()
.filter(name -> name.contains("a"))
.foreach(system.out::println);
}
}
在这个示例中,首先创建了一个包含几个名字的 list。然后使用 stream() 方法将其转换为 stream 对象,在 stream 上调用 filter 方法,传入一个 lambda 表达式作为条件,筛选出包含字母“a”的名字。最后,我们使用 foreach 方法打印筛选出的结果。
除了 filter 和 foreach 操作之外,stream 还提供了很多其他的操作,如 map、reduce、sorted 等,通过这些操作,可以非常方便地进行数据处理和转换。
需要注意的是,stream 的操作通常是惰性求值的,也就是说,在调用终结操作(如 foreach)之前,中间操作(如 filter、map)不会立即执行,而是等到终结操作触发时才会执行。这种特性使得 stream 在处理大规模数据时更加高效。
总结
到此这篇关于java学习常用包(类)之java.util包详解的文章就介绍到这了,更多相关java java.util包内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论