引言
在java开发过程中,经常需要处理来自不同数据库的数据。为了高效地管理多个数据源,开发者常常需要借助一些工具或框架来实现。hutool是一个小而全的java工具类库,它封装了java中常见的操作,如文件、网络、数据库等,极大地简化了java开发。其中,hutool的dsfactory(数据源工厂)是操作多数据源的一个重要工具。本文将详细介绍如何在java项目中使用hutool的dsfactory来操作多数据源。
hutool简介
hutool是一个小而全的java工具类库,它简化了java开发中常见的操作,提高了开发效率。hutool的数据库操作模块(hutool-db)在jdbc基础上进行了封装,提供了更加灵活和便捷的数据库操作方法。dsfactory作为数据源工厂,支持多种数据源配置和连接池管理,使得多数据源操作变得简单高效。
引入hutool依赖
首先,你需要在你的java项目中引入hutool的hutool-db依赖。如果你使用的是maven,可以在pom.xml文件中添加如下依赖:
<dependency>
<groupid>cn.hutool</groupid>
<artifactid>hutool-db</artifactid>
<version>5.7.16</version> <!-- 请根据实际情况使用最新版本 -->
</dependency>确保使用的版本是最新版本,以便获得最新的功能和修复。
配置多数据源
在hutool中,你可以通过dsfactory来创建和管理多个数据源。dsfactory支持自动识别数据源和配置文件,支持多种连接池如hikaricp、druid等。你可以通过自定义配置文件来设置每个数据源的具体参数,或者直接在代码中配置。
自定义配置文件
hutool支持通过配置文件(如db.setting)来管理数据源配置。你可以在src/main/resources目录下创建db.setting文件,并配置多个数据源。下面是一个示例配置:
# 默认数据源 url = jdbc:mysql://localhost:3306/db1 username = root password = 123456 driver = com.mysql.cj.jdbc.driver # 第二个数据源 [db2] url = jdbc:mysql://localhost:3306/db2 username = root password = 123456 driver = com.mysql.cj.jdbc.driver # 第三个数据源(使用druid连接池) [db3] url = jdbc:mysql://localhost:3306/db3 username = root password = 123456 driver = com.mysql.cj.jdbc.driver # druid特有配置 initialsize = 5 maxactive = 10 minidle = 2 maxwait = 10000
注意:这里的配置格式是hutool支持的自定义格式,不是标准的jdbc url或连接池配置文件格式。hutool会根据这个配置文件自动创建和配置数据源。
代码中配置数据源
如果你不想使用配置文件,也可以在代码中直接配置数据源。使用dsfactory的newsimpledatasource方法可以创建一个简单的数据源,并设置其jdbc url、用户名和密码。然后,你可以使用dbutil.addconfig方法将这个数据源添加到hutool的数据源管理中。
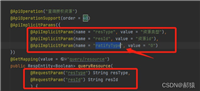
import cn.hutool.db.dsfactory;
import cn.hutool.db.dbutil;
import cn.hutool.db.ds.simpledatasource;
public class multidatasourceconfig {
public static void main(string[] args) {
// 创建数据源
simpledatasource ds1 = dsfactory.newsimpledatasource("jdbc:mysql://localhost:3306/db1", "username", "password");
simpledatasource ds2 = dsfactory.newsimpledatasource("jdbc:mysql://localhost:3306/db2", "username", "password");
// 添加数据源配置
dbutil.addconfig(ds1, "db1");
dbutil.addconfig(ds2, "db2");
}
}使用多数据源
在配置好多个数据源之后,你可以在代码中通过db.use方法来切换当前使用的数据源,并执行相应的数据库操作。
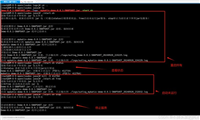
import cn.hutool.db.db;
public class multidatasourceexample {
public static void main(string[] args) {
// 切换到db1数据源并执行查询
db.use("db1").find("select * from table1");
// 切换到db2数据源并执行查询
db.use("db2").find("select * from table2");
}
}在上面的代码中,db.use("db1")会切换到名为db1的数据源,并执行后续的数据库操作。同样地,db.use("db2")会切换到db2数据源。
hutool多数据源的实现原理
hutool的多数据源功能是通过动态代理实现的。当你调用db.use方法切换数据源时,hutool会根据传入的数据源名称找到对应的数据源配置,并创建一个代理对象。这个代理对象会拦截所有的数据库操作方法,并在执行之前切换到正确的数据源。
具体来说,当你执行db.use("db1").find("select * from table1")时,hutool会首先通过db.use("db1")找到名为db1的数据源配置,并创建一个代理对象。然后,当你调用find方法执行sql查询时,这个代理对象会拦截这个调用,并在实际执行sql之前将数据库连接切换到db1数据源。
注意事项
- 数据源配置:确保你的数据源配置是正确的,包括jdbc url、用户名、密码等。如果配置错误,将无法成功连接到数据库。
- 连接池选择:hutool支持多种连接池,如hikaricp、druid等。你可以根据自己的需求选择合适的连接池。如果不指定连接池,hutool将使用内置的简易连接池,但这通常不推荐在生产环境中使用。
- 性能优化:在使用多数据源时,注意性能优化。例如,合理设置连接池的参数、优化sql查询等。
- 异常处理:在执行数据库操作时,注意异常处理。确保你的代码能够捕获并处理可能发生的sqlexception。
总结
通过使用hutool的dsfactory,java开发者可以轻松地实现多数据源的管理和操作。无论是通过配置文件还是直接在代码中配置数据源,hutool都提供了灵活和便捷的方式。同时,hutool的多数据源功能通过动态代理实现,使得在代码中切换数据源变得简单高效。希望本文能够帮助你更好地理解和使用hutool的多数据源功能。
到此这篇关于java中使用hutool的dsfactory操作多数据源的实现的文章就介绍到这了,更多相关java dsfactory操作多数据源内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论