python调用df.to_csv()出现中文乱码
df = pd.dataframe(data=total_info, columns=[‘公司全名', ‘公司简称', ‘公司规模', ‘融资阶段', ‘区域', ‘职位名称', ‘工作经验', ‘学历要求', ‘薪资', ‘职位福利', ‘经营范围', ‘职位类型', ‘公司福利', ‘第二职位类型', ‘城市']) df.to_csv(‘c:/users/shinelon/desktop/python_development_engineer.csv', index=false)
结果出现乱码:
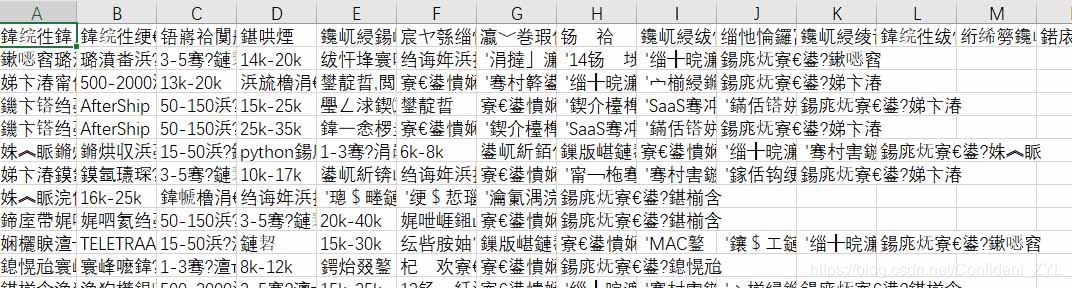
解决方案
加上**encoding=“utf_8_sig”**就好了。
df.to_csv(‘c:/users/shinelon/desktop/python_development_engineer.csv', encoding=“utf_8_sig”)

注意注意
‘utf-8’ 和 ‘utf_8_sig’ 的区别:
- ”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要bom,所以当用"utf-8"编码方式读取带有bom的文件时,它会把bom当做是文件内容来处理。
- “uft-8-sig"中sig( signature )是"带有签名的utf-8”, 所以"utf-8-sig"读取带有bom的"utf-8文件时"会把bom单独处理,与文本内容隔离开。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论