一、savedata函数
import csv
def savedata(filepath, data):
with open(filepath, 'w+', newline='') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)如果data是一个list,savedata函数会将list中的每个元素保存在csv文件中的一行。
但是存在一个问题:
csv文件中保存的数据如果直接读取出来是str类型,需要进行转换
二、将dataframe写入csv文件
情况1
将list写入csv文件
init_configs = []
for i, cluster in enumerate(clusters):
init_configs.append([f"cluster {i}:"])
for _, row in cluster.iterrows():
config = row.tolist()
init_configs.append(config)
savedata('filepath', init_configs)config = row.tolist()会将df中每一行数据都转变为list,然后append到init_configs中,通过调用savedata函数可以将每一行数据表示的list都写到csv文件中的一行。
这种情况生成的csv文件中每一行的各个元素之间都是用逗号隔开。

情况2
将嵌套list写入csv文件
init_configs = []
for i, cluster in enumerate(clusters):
init_configs.append([f"cluster {i}:"])
for _, row in cluster.iterrows():
config = row.tolist()
init_configs.append([config])
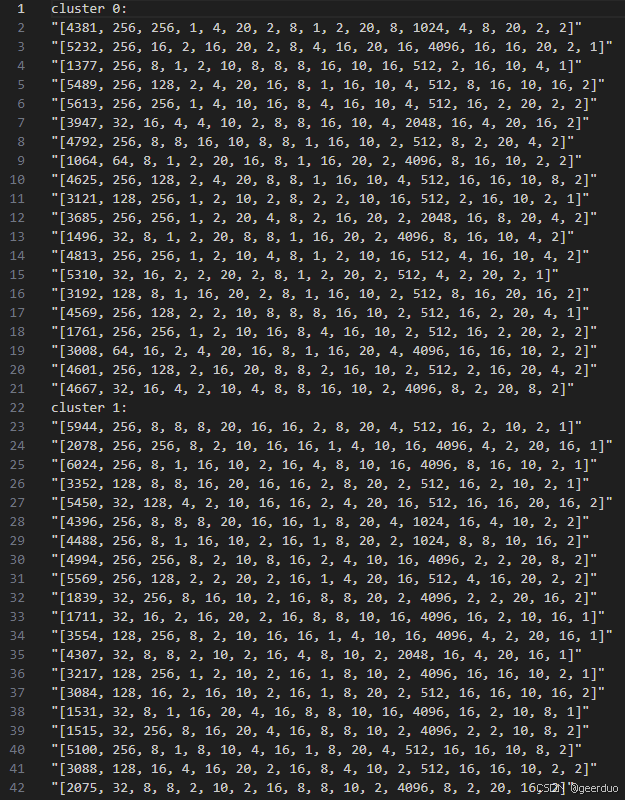
savedata('filepath', init_configs)这种情况下init_configs中每个元素是一个二维list,由于csv 文件是一种纯文本格式,它无法直接存储列表或其他复杂的数据结构。
当尝试将 [[1, 2, 3, 4, 5]] 这个二维嵌套list写入csv文件时,它会被自动转换为字符串形式。
如下:
三、读取csv文件
情况1
如果按照上面的方法1写csv文件,可以按照如下方式将内容读出来:
import pandas as pd
with open(filepath, 'r') as f:
lines = f.readlines()
filtered_lines = [line for line in lines if not line.startswith('cluster')]
configs = []
for line in filtered_lines:
config = [int(x) for x in line.strip().split(',')]
configs.append(config)
df = pd.dataframe(configs)可以用列表表达式的方式将csv文件中每一行的数据转为一个list。
情况2
如果将整个list当作字符串写到了csv文件中,可以按照如下方式将内容正确地读出来:
import pandas as pd
import ast
with open(filepath, 'r') as f:
lines = f.readlines()
filtered_lines = [line for line in lines if not line.startswith('cluster')]
configs = []
for line in filtered_lines:
config = ast.literal_eval(eval(line))
configs.append(config)
df = pd.dataframe(configs)通过config = ast.literal_eval(eval(line))可以将变为字符串的list还原成原本的数据形式。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论