html + javascript 实现网页录制音频与下载
简介
在这个数字化的时代,网页端的音频处理能力已经成为一个非常热门的需求。本文将详细介绍如何利用 getusermedia 和 mediarecorder 这两个强大的 api,实现网页端音频的录制、处理和播放等功能。
getusermedia
getusermedia 和 mediarecorder 是 html5 中两个非常重要的 api,用于访问设备媒体输入流并对其进行操作。
getusermedia 允许网页端访问用户设备的媒体输入设备,比如摄像头和麦克风。通过该 api,在获得用户授权后,我们可以获取这些媒体流的数据,并用于各种网页应用场景中。
典型的使用方式如下:
// 请求获取音频流
navigator.mediadevices.getusermedia({
audio: true
})
.then(stream => {
// 在此处理音频流
})getusermedia 接受一个 constraints 对象作为参数,通过设置配置来请求获取指定的媒体类型,常见的配置有:
- audio:boolean 值,是否获取音频输入。
- video:boolean 值,是否获取视频输入。
- 以及更详细的各种音视频参数设置。
mediarecorder
mediarecorder api 可以获取由 getusermedia 生成的媒体流,并对其进行编码和封装,输出可供播放和传输的媒体文件。
典型的用法如下:
// 获取媒体流
const stream = await navigator.mediadevices.getusermedia({ audio: true })
// 创建 mediarecorder 实例
const mediarecorder = new mediarecorder(stream);
// 注册数据可用事件,以获取编码后的媒体数据块
mediarecorder.ondataavailable = event => {
audiochunks.push(event.data);
}
// 开始录制
mediarecorder.start();
// 录制完成后停止
mediarecorder.stop();
// 将录制的数据组装成 blob
const blob = new blob(audiochunks, {
type: 'audio/mp3'
});简单来说,getusermedia 获取输入流,mediarecorder 对流进行编码和处理,两者结合就可以实现强大的音视频处理能力。
获取和处理音频流
了解了基本 api 使用方法后,我们来看看如何获取和处理音频流。
首先需要调用 getusermedia 来获取音频流,典型的配置是:
const stream = await navigator.mediadevices.getusermedia({
audio: {
channelcount: 2,
samplerate: 44100,
samplesize: 16,
echocancellation: true
}
});我们可以指定声道数、采样率、采样大小等参数来获取音频流。
ps:这似乎不管用。
使用 navigator.mediadevices.enumeratedevices() 可以获得所有可用的媒体设备列表,这样我们就可以提供设备选择功能给用户,而不仅仅是默认设备。
举例来说,如果我们想要让用户选择要使用的录音设备:
// 1. 获取录音设备列表
const audiodevices = await navigator.mediadevices.enumeratedevices();
const mics = audiodevices.filter(d => d.kind === 'audioinput');
// 2. 提供设备选择 ui 供用户选择
const selectedmic = mics[0];
// 3. 根据选择配置进行获取流
const constraints = {
audio: {
deviceid: selectedmic.deviceid
}
};
const stream = await navigator.mediadevices.getusermedia(constraints);这样我们就可以获得用户选择的设备录音了。
获得原始音频流后,我们可以利用 web audio api 对其进行处理。
例如添加回声效果:
// 创建音频环境
const audiocontext = new audiocontext();
// 创建流源节点
const source = audiocontext.createmediastreamsource(stream);
// 创建回声效果节点
const echo = audiocontext.createconvolver();
// 连接处理链
source.connect(echo);
echo.connect(audiocontext.destination);
// 加载回声冲击响应并应用
const impulseresponse = await fetch('impulse.wav');
const buffer = await impulseresponse.arraybuffer();
const audiobuffer = await audiocontext.decodeaudiodata(buffer);
echo.buffer = audiobuffer;通过这样的音频处理链,我们就可以在录音时添加回声、混响等音效了。
实现音频的录制和播放
录制音频的步骤:
- 调用 getusermedia 获取音频流。
- 创建 mediarecorder 实例,传入音频流。
- 注册数据可用回调,以获取编码后的音频数据块。
- 调用 recorder.start() 开始录制。
- 录制完成后调用 recorder.stop()。
代码:
let recorder;
let audiochunks = [];
// 开始录音 handler
const startrecording = async () => {
const stream = await navigator.mediadevices.getusermedia({
audio: true
});
recorder = new mediarecorder(stream);
recorder.ondataavailable = event => {
audiochunks.push(event.data);
};
recorder.start();
}
// 停止录音 handler
const stoprecording = () => {
if(recorder.state === "recording") {
recorder.stop();
}
}录音完成后,我们可以将音频数据组装成一个 blob 对象,然后赋值给一个 <audio> 元素的 src 属性进行播放。
代码:
// 录音停止后
const blob = new blob(audiochunks, { type: 'audio/ogg' });
const audiourl = url.createobjecturl(blob);
const player = document.queryselector('audio');
player.src = audiourl;
// 调用播放
player.play();这样就可以播放刚刚录制的音频了。
后续也可以添加下载功能等。
音频效果的处理
利用 web audio api,我们可以添加各种音频效果,进行音频处理。
例如添加回声效果:
const audiocontext = new audiocontext();
// 原始音频节点
const source = audiocontext.createmediastreamsource(stream);
// 回声效果节点
const echo = audiocontext.createconvolver();
// 连接处理链
source.connect(echo);
echo.connect(audiocontext.destination);
// 加载冲击响应作为回声效果
const impulseresponse = await fetch('impulse.wav');
const arraybuffer = await impulseresponse.arraybuffer();
const audiobuffer = await audiocontext.decodeaudiodata(arraybuffer);
echo.buffer = audiobuffer;这样在录制时音频流就会经过回声效果处理了。
此外,我们还可以添加混响、滤波、均衡器、压缩等多种音频效果,使得网页端也能处理出专业级的音频作品。
实时语音通话的应用
利用 getusermedia 和 webrtc 技术,我们还可以在网页端实现实时的点对点语音通话。
简述流程如下:
- 通过 getusermedia 获取本地音视频流。
- 创建 rtcpeerconnection 实例。
- 将本地流添加到连接上。
- 交换 ice 候选信息,建立连接。
- 当检测到连接后,渲染远端用户的音视频流。
这样就可以实现类似 skype 的网页端语音通话功能了。
代码:
// 1. 获取本地流
const localstream = await navigator.mediadevices.getusermedia({
audio: true,
video: true
});
// 2. 创建连接对象
const pc = new rtcpeerconnection();
// 3. 添加本地流
localstream.gettracks().foreach(track => pc.addtrack(track, localstream));
// 4. 交换 ice 等信令,处理 onaddstream 等事件
// ...
// 5. 收到远端流,渲染到页面
pc.ontrack = event => {
remotevideo.srcobject = event.streams[0];
}获取本地输入流后,经过编码和传输就可以实现语音聊天了。
兼容性和 latency 问题
尽管 getusermedia 和 mediarecorder 在现代浏览器中已经得到了较好的支持,但由于不同厂商和版本实现存在差异,在实际应用中还是需要注意一些兼容性问题:
- 检测 api 支持情况,提供降级方案。
- 注意不同浏览器对 codec、采样率等参数支持的差异。
- 封装浏览器差异,提供统一的 api。
此外,录音和播放也存在一定的延迟问题。我们需要针对 latency 进行优化,比如使用更小的 buffer 大小,压缩数据包大小等方法。
项目代码
record.html:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>record page</title>
<link rel="stylesheet" type="text/css" href="css/record.css" rel="external nofollow" >
</head>
<body>
<div class="app">
<audio controls class="audio-player"></audio>
<button class="record-btn">录音</button>
<a id="download" download="record.aac"></a>
</div>
</body>
<script src="js/record.js"></script>
</html>record.css:
.app {
display: flex;
justify-content: center;
align-items: center;
}
.record-btn {
margin: 0 10px;
}record.js:
const recordbtn = document.queryselector(".record-btn")
const player = document.queryselector(".audio-player")
const download = document.queryselector('#download')
if (navigator.mediadevices.getusermedia) {
let audiochunks = []
// 约束属性
const constraints = {
// 音频约束
audio: {
samplerate: 16000, // 采样率
samplesize: 16, // 每个采样点大小的位数
channelcount: 1, // 通道数
volume: 1, // 从 0(静音)到 1(最大音量)取值,被用作每个样本值的乘数
echocancellation: true, // 开启回音消除
noisesuppression: true, // 开启降噪功能
},
// 视频约束
video: false
}
// 请求获取音频流
navigator.mediadevices.getusermedia(constraints)
.catch(err => serverlog("error mediadevices.getusermedia: ${err}"))
.then(stream => {// 在此处理音频流
// 创建 mediarecorder 实例
const mediarecorder = new mediarecorder(stream)
// 点击按钮
recordbtn.onclick = () => {
if (mediarecorder.state === "recording") {
// 录制完成后停止
mediarecorder.stop()
recordbtn.textcontent = "录音结束"
}
else {
// 开始录制
mediarecorder.start()
recordbtn.textcontent = "录音中..."
}
}
mediarecorder.ondataavailable = e => {
audiochunks.push(e.data)
}
// 结束事件
mediarecorder.onstop = e => {
// 将录制的数据组装成 blob(binary large object) 对象(一个不可修改的存储二进制数据的容器)
const blob = new blob(audiochunks, { type: "audio/aac" })
audiochunks = []
const audiourl = window.url.createobjecturl(blob)
// 赋值给一个 <audio> 元素的 src 属性进行播放
player.src = audiourl
// 添加下载功能
download.innerhtml = '下载'
download.href = audiourl
}
},
() => {
console.error("授权失败!");
}
);
} else {
console.error("该浏览器不支持 getusermedia!");
}运行实例
打开 record.html,首先获取麦克风权限:

点击“允许”。
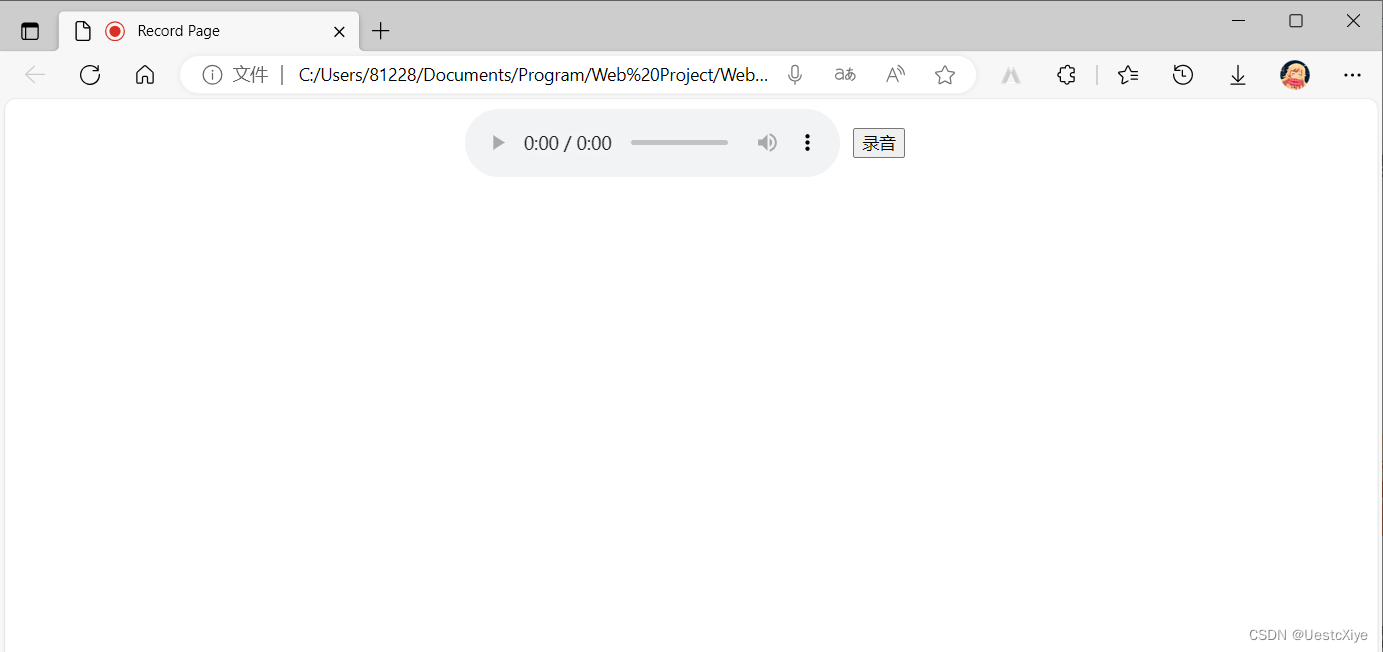
页面有一个 audio-player 和一个 buttom。
点击“录音”按钮,就开始录音了。
再点一次按钮,停止录音,数据传回给 audio-player,可以在网页上播放录音。
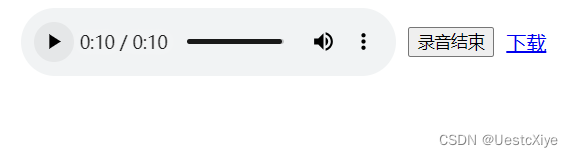
点击“下载”,可以下载录制的音频。
ps:音频文件名称设置为 record.aac,文件格式为 webm,音频格式为 opus,单声道,采样率 48khz,位深 32bit。
参考资料
源码下载
百度网盘下载地址
链接: https://pan.baidu.com/s/1vs--_5o7flbuss0vaern-q?pwd=8s43
提取码: 8s43
github:web-record
到此这篇关于javascript+html 实现网页录制音频与下载的文章就介绍到这了,更多相关js网页录制音频内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论