一、基本概念
elasticsearch是一个基于lucene的开源、分布式、restful搜索引擎。它提供了全文搜索、结构化搜索、分析以及分布式索引等功能。elasticsearch sql是elasticsearch的扩展功能,允许用户使用sql语法查询elasticsearch数据。通过sql接口,开发者可以利用熟悉的sql语言,编写更直观、更易懂的查询,并且避免对大量复杂的原生rest请求的编写。

二、主要功能和优势
- 易用性:使用熟悉的sql语法,降低了学习成本。
- 灵活性:支持复杂的查询和聚合操作。
- 性能:elasticsearch本身的分布式架构和高效查询引擎保证了查询性能。
- 集成性:通过jdbc驱动,可以与各种sql工具和应用程序集成。
elasticsearch sql特点
1. 本地集成
elasticsearch sql是专门为elasticsearch构建的。每个sql查询都根据底层存储对相关节点有效执行。
2. 没有额外的要求
不依赖其他的硬件、进程、运行时库,elasticsearch sql可以直接运行在elasticsearch集群上
3. 轻量且高效
像sql那样简洁、高效地完成查询
三、启用和使用sql功能
要在elasticsearch中启用和使用sql功能,你需要安装x-pack插件。x-pack插件包含了许多扩展功能,包括sql接口。安装完成后,需要在elasticsearch配置文件中启用x-pack插件,并重启elasticsearch服务。
# 安装x-pack插件 ./bin/elasticsearch-plugin install x-pack # 启用x-pack插件 # 在elasticsearch.yml配置文件中添加以下配置 xpack.sql.enabled: true
在启用sql功能后,你可以通过rest api、命令行工具或jdbc驱动来执行sql查询。elasticsearch sql的语法与标准的sql语法非常相似,支持select、from、where、group by、having、order by等常见sql语句。
四、elasticsearch sql的使用
4.1 语法
select select_expr [, ...] [ from table_name ] [ where condition ] [ group by grouping_element [, ...] ] [ having condition] [ order by expression [ asc | desc ] [, ...] ] [ limit [ count ] ] [ pivot ( aggregation_expr for column in ( value [ [ as ] alias ] [, ...] ) ) ]
目前from只支持单表
4.2 sql查询
# 使用curl命令查询
curl -x get "localhost:9200/_sql?format=txt" -h 'content-type: application/json' -d'
{
"query": "select * from indexname where age > 30"
}'format=txt 是指查询返回结果的数据格式
4.3 将sql转换为dsl
get /_sql/translate
{
"query":"select * from es_order limit 1"
}结果如下:
{
"size" : 1,
"_source" : {
"includes" : [
"id",
"orderno",
"ordertime"
],
"excludes" : [ ]
},
"docvalue_fields" : [
{
"field" : "id"
},
{
"field" : "orderno"
},
{
"field" : "ordertime"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
4.4 全文检索
当使用match或query函数时,会启用全文搜索功能,score函数可以用来统计搜索评分。
match函数
match(
field_exp,
constant_exp
[, options])
field_exp:匹配字段
constant_exp:匹配常量表达式用法:
get /_sql?format=txt
{
"query":"select * from es_order where match(address, '武汉') or match(producttype, '手机') limit 10"
}query()
使用query函数查询address中包含street的记录。
post /_sql?format=txt
{
"query":"select id,orderno,name,address,score() from es_order where query('address: 武汉') limit 10"
}4.5 分组统计
get /_sql?format=txt
{
"query":"select city, count(*) as age_cnt from es_order group by city"
}这种方式要更加直观、简洁。
having
我们可以使用having语句对分组数据进行二次筛选,比如筛选分组记录数量大于1000的信息,查询语句如下。
post /_sql?format=txt
{
"query":"select city, count(*) as age_cnt from es_order group by city having count(*) > 1000"
}order by
使用order by语句对数据进行排序,比如按照统计字段从高到低排序,查询语句如下。
post /_sql?format=txt
{
"query":"select city, count(*) cc as age_cnt from es_order group by city having count(*) > 1000 order by cc "
}注意: 目前elasticsearch sql还存在一些限制。例如:不支持join、不支持较复杂的子查询。所以,有一些相对复杂一些的功能,还得借助于dsl方式来实现
4.6 describe
使用describe语句查看索引中有哪些字段,比如查看es_order索引的字段,查询语句如下。
post /_sql?format=txt
{
"query": "describe es_order"
}4.7 show tables
使用show tables查看所有的索引
post /_sql?format=txt
{
"query": "show tables"
}4.8 查询支持的函数
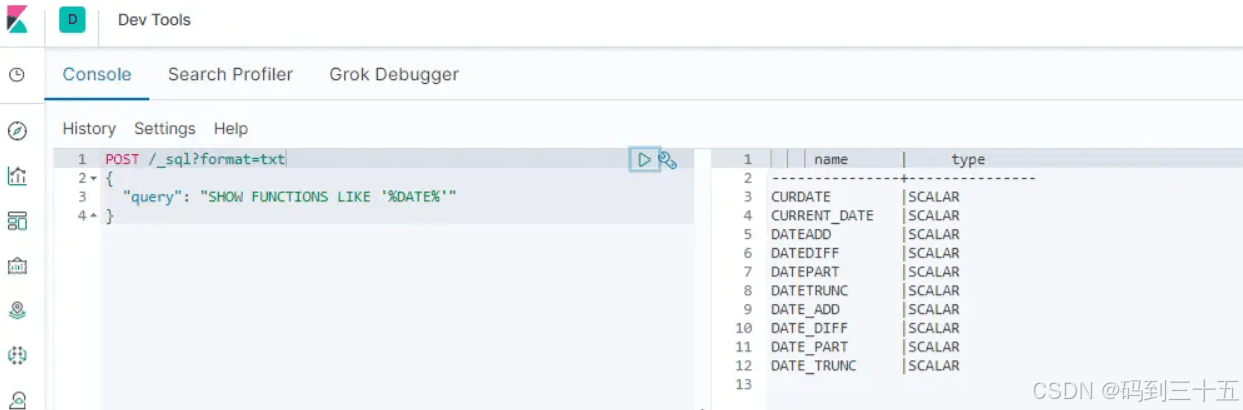
使用sql查询es中的数据,不仅可以使用一些sql中的函数,还可以使用一些es中特有的函数。show functions语句查看所有支持的函数,比如搜索所有带有date字段的函数可以使用如下语句。
post /_sql?format=txt
{
"query": "show functions like '%date%'"
}
五、适用场景及潜在限制
elasticsearch sql适用于需要对大量数据进行复杂查询的场景,如数据分析、报表生成、数据探索等。然而,由于sql查询的复杂性,它可能不适用于所有场景。例如,对于需要高并发、低延迟的场景,原生rest查询可能更合适。
此外,虽然elasticsearch sql提供了sql接口,但它并不是完全兼容sql。例如,它不支持所有的sql函数和特性。因此,在使用elasticsearch sql时,需要了解它的限制,并根据实际情况选择使用。
总结来说,elasticsearch sql提供了一种直观、易用的方式查询elasticsearch数据。它允许开发者利用熟悉的sql语言,编写更直观、更易懂的查询,并避免对大量复杂的原生rest请求的编写。然而,它的适用场景和性能特点需要在实际使用中仔细考虑。
到此这篇关于在elasticsearch中启用和使用sql功能的文章就介绍到这了,更多相关elasticsearch使用sql内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论