本文介绍一篇激光雷达监督视觉传感器的3d检测模型:cmkd,论文收录于 eccv2022。
- 在本文中,作者提出了用于单目3d检测的 跨模态知识蒸馏 (cmkd) 网络,使用激光雷达模型作为教师模型,监督图像模型(图像模型为caddn)。
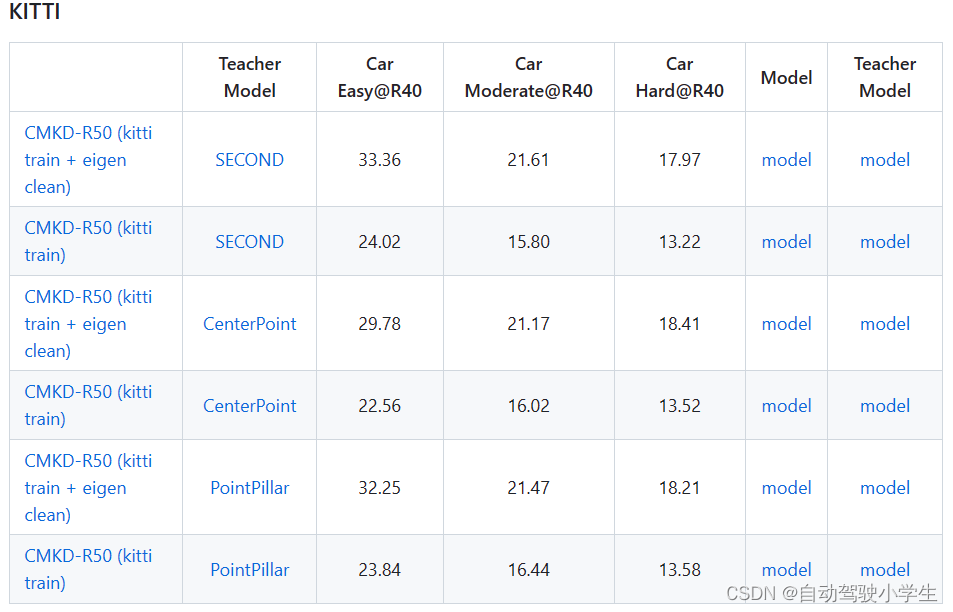
- 此外,作者通过从大规模未标注的数据中提取知识,进一步将cmkd扩展为半监督训练框架,大幅度的提高模型性能。在github上作者提供了三种不同的激光雷达教师模型(second、centerpoint、pointpillar)。可以看到使用大量未标注的原始数据(kitti train + eigen clean),单目图像检测性能取得了显著提高。
论文链接:https://arxiv.org/abs/2211.07171
项目链接:https://github.com/cc-hy/cmkd
文章目录
method
framework overview
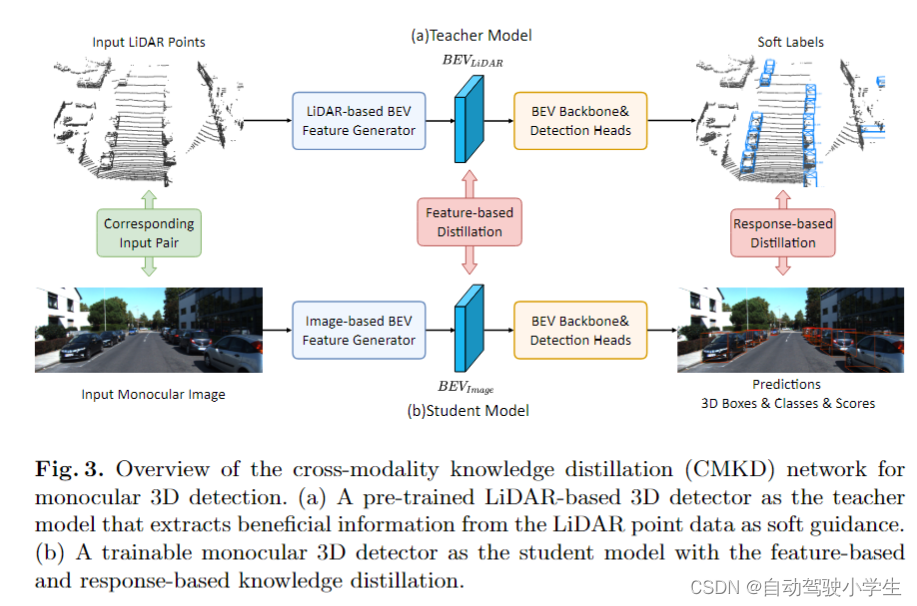
论文的引言和相关工作部分这里不介绍了,直接介绍论文方法。如下图所示,方法简单明了,关键是从 lidar 和单目图像中提取对应的特征和响应表示,并在两种模态之间执行知识蒸馏。 整个框架包括一个预训练的激光雷达3d检测器作为教师模型,在训练阶段从lidar中提取信息作为指导信息,学生模型为可训练的单目3d检测器,在特征和响应中进行跨模态知识蒸馏。
在训练阶段,单目图像和对应的lidar点云作为模型输入对。预训练的教师模型仅从输入 lidar 进行推理,提供 bev 特征图作为特征指导,并使用预测的 3d 框、对象类别及其对应的置信度分数作为响应指导。学生模型用于从单目图像生成bev特征图和3d目标检测结果,并使用教师模型的特征和响应表示作为软指导进行有用的知识蒸馏。在推理阶段,学生模型仅使用单目图像作为输入执行 3d 目标检测。
bev feature learning
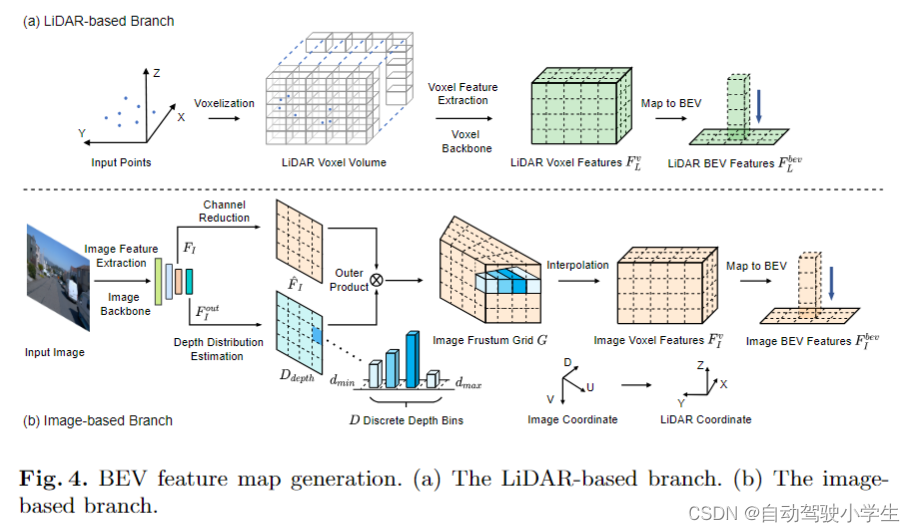
bev特征学习,对于激光雷达模型本文使用second检测模型作为教师模型,从lidar中提取bev特征。首先将输入点云划分为相等的 3d 体素,然后这些体素被输入到体素主干网提取体素特征 f l v ∈ r x × y × z × c f^{v}_l \in r^{x\times y \times \z \times c} flv∈rx×y×z×c ,其中 x 、 y 、 z x、y、z x、y、z 是体素特征的宽、长、高, c c c 是特征通道数量。然后,将体素特征 f l v f^{v}_l flv 沿着高度进行堆叠,压缩得到bev特征 f l b e v ∈ r x × y × z ∗ c f^{bev}_l \in r^{x\times y \times z*c} flbev∈rx×y×z∗c 。
对于图像模型,本文使用caddn模型获得图像bev特征。首先使用图像骨干网络从单目图像 i ∈ r w × h × c i \in r^{w\times h \times c} i∈rw×h×c 提取图像特征, f i ∈ r w i × h i × c f_i \in r^{w_i\times h_i \times c} fi∈rwi×hi×c 和 f i o u t ∈ r w i o u t × h i o u t × c f^{out}_i \in r^{w^{out}_i\times h^{out}_i \times c} fiout∈rwiout×hiout×c。对特征 f i f_i fi 使用一个通道减少网络得到特征 f i ^ ∈ r w i × h i × c ′ \hat{f_i} \in r^{w_i\times h_i \times c^{'}} fi^∈rwi×hi×c′。对于特征 f i o u t f^{out}_i fiout 使用深度估计网络预测特征图上每个像素的深度分布 d d e p t h ∈ r w i × h i × d d_{depth} \in r^{w_i\times h_i \times d} ddepth∈rwi×hi×d,然后将图像特征 f i ^ ∈ r w i × h i × c ′ \hat{f_i} \in r^{w_i\times h_i \times c^{'}} fi^∈rwi×hi×c′和深度特征图进行外积运算得到图像视锥网格张量 f g ∈ r w i × h i × d × c ′ f_g \in r^{w_i\times h_i \times d \times c^{'}} fg∈rwi×hi×d×c′。然后,通过已知外参进行插值操作,将图像视锥网格转换到lidar坐标,得到体素特征 f i v ∈ r x i × y i × z i × c ′ f^{v}_i \in r^{x_i\times y_i \times z_i \times c^{'}} fiv∈rxi×yi×zi×c′。然后对体素特征进行压缩得到bev特征 f ~ i bev ∈ r x i × y i × z i ∗ c ′ \tilde{f}_i^{\text {bev }} \in \mathbb{r}^{x_i \times y_i \times z_i * c^{\prime}} f~ibev ∈rxi×yi×zi∗c′,最后再使用一个图像压缩网络得到最终的bev特征 f i bev ∈ r x i × y i × c ′ f_i^{\text {bev }} \in \mathbb{r}^{x_i \times y_i \times c^{\prime}} fibev ∈rxi×yi×c′。
关于图像bev特征生成的细节,大家可以看caddn模型的源码。
domain adaptation via self-calibration
图像bev特征和lidar bev特征在空间和通道特征分布上是不同的,因为它们来自不同的模态和主干网。本文采用域自适应 (da) 模块将图像bev特征分布与lidar bev特征分布进行对齐同时增强图像bev特征。具体实现上,作者在得到图像bev特征之后又使用了卷积网络进行特征对齐:
f ^ i b e v = d a ( f i b e v ) \hat{f}_i^{b e v}=d a\left(f_i^{b e v}\right) f^ibev=da(fibev)
其中, f i b e v ^ ∈ r x i × y i × c ′ \hat{f^{bev}_i} \in r^{x_i\times y_i \times c^{'}} fibev^∈rxi×yi×c′为域自适应模块处理后的图像bev特征。
feature-based knowledge distillation
对于特征蒸馏,本文使用均方误差mse计算特征蒸馏损失:
l
feat
=
m
s
e
(
f
^
i
bev
,
f
l
b
e
v
)
\mathcal{l}_{\text {feat }}=m s e\left(\hat{f}_i^{\text {bev }}, f_l^{b e v}\right)
lfeat =mse(f^ibev ,flbev)
由于以下几个方面,本文的单目3d检测器受益于基于特征的知识蒸馏。首先, f l b e v f^{bev}_l flbev包含直接从 lidar 中提取的准确 3d 信息,例如深度和几何形状。lidar bev特征可以很好地用于训练 3d 目标检测器,同时对于低光照条件具有良好的鲁棒性,可以从lidar bev特征中提取这种模式转移到图像bev特征上。
如下图5所示,在使用所提出的da模块以及进行特征知识蒸馏后,图像bev特征的模式接近lidar bev特征,这是检测3d目标的关键信息。此外,中间特征引导可以缓解高维信息过拟合,作为整体损失函数中的正则化项。

response-based knowledge distillation
本文使用教师模型的预测作为学生模型的响应指导。与真值标签相比,软标签包含更多的信息。此外,教师模型可以作为训练样本的样本过滤器,例如,对于教师模型来说很难检测到的样本往往被消除或分配低置信度分数,并且稳定样本会被分配高置信度分数。
基于响应蒸馏的损失包括 3d 边界框的回归损失和目标分类损失:
l
res
=
l
reg
+
l
cls
\mathcal{l}_{\text {res }}=\mathcal{l}_{\text {reg }}+\mathcal{l}_{\text {cls }}
lres =lreg +lcls
在对教师模型进行预训练时,我们使用iou以及quality focal loss作为连续质量标签,而不是分类头中的原始 one-hot 标签。因此,预测的置信度分数更具 iou 意识,用于表示预测的“质量”。对于第i个anchor,使用smooth l1作为损失函数,同时使用软标签的置信度来作为惩罚系数,具体公式为:
l
reg
=
smooth l
1
(
a
i
soft
,
a
i
pred
)
×
s
i
\mathcal{l}_{\text {reg }}=\text { smooth l } 1\left(a_i^{\text {soft }}, a_i^{\text {pred }}\right) \times s_i
lreg = smooth l 1(aisoft ,aipred )×si
其中,
a
i
soft
,
a
i
pred
a_i^{\text {soft }}, a_i^{\text {pred }}
aisoft ,aipred 为软标签和预测框参数,
s
i
s_i
si 是教师模型预测框和真值框iou值。对于分类损失,公式为:
l
c
l
s
=
q
f
l
(
c
i
soft
,
c
i
pred
)
×
s
i
\mathcal{l}_{c l s}=q f l\left(c_i^{\text {soft }}, c_i^{\text {pred }}\right) \times s_i
lcls=qfl(cisoft ,cipred )×si
其中,
c
i
soft
,
c
i
pred
c_i^{\text {soft }}, c_i^{\text {pred }}
cisoft ,cipred 为软标签和预测分类参数。 如下图所示,软标签的置信度分数与其真值框的 iou大小正相关,用于对学生模型的每个预测产生的损失进行加权。
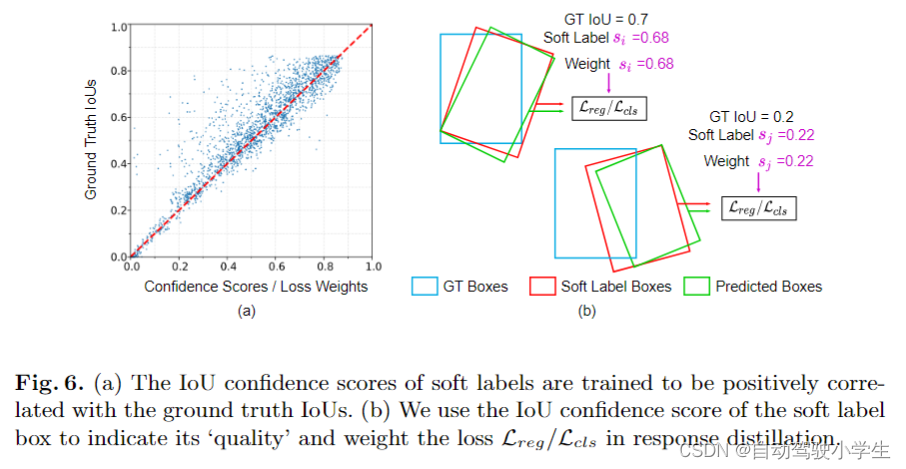
extension: distilling unlabeled data
在用标记样本对教师模型进行预训练后,学生模型的损失函数中的每个损失项不使用任何来自真值标签的信息。因此,我们可以很容易地将 cmkd 扩展为具有大规模未标记数据的半监督训练框架。通过教师模型提取有益信息并将其转移到学生模型作为软指导,我们可以使用部分标记样本并使用整个未标记集训练模型。
cmkd 处理未标记数据的扩展能力显着减少了注释成本并带来了性能改进, 可以泛华cmkd在现实场景中的应用。请注意,未标记数据的利用对于单目3d检测任务并不新鲜,尤其是对于pseudo-lidar方法。本文的贡献是使用跨模态知识蒸馏网络提高未标记数据的利用率。主要区别在于其他方法仅使用未标记的数据进行深度预训练,但我们进一步使用它来进行知识蒸馏,网络的所有组件联合优化。
experiments
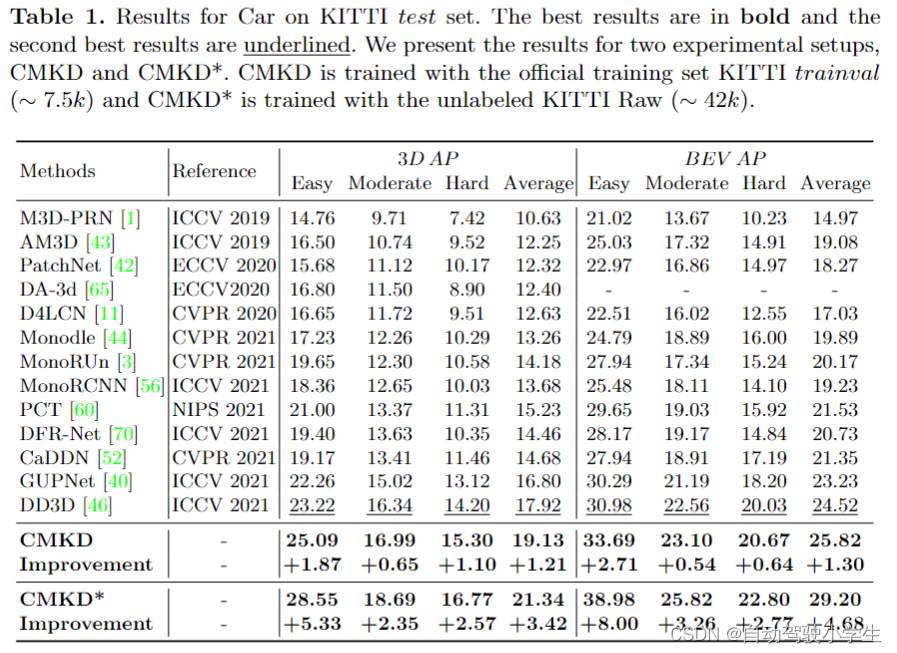
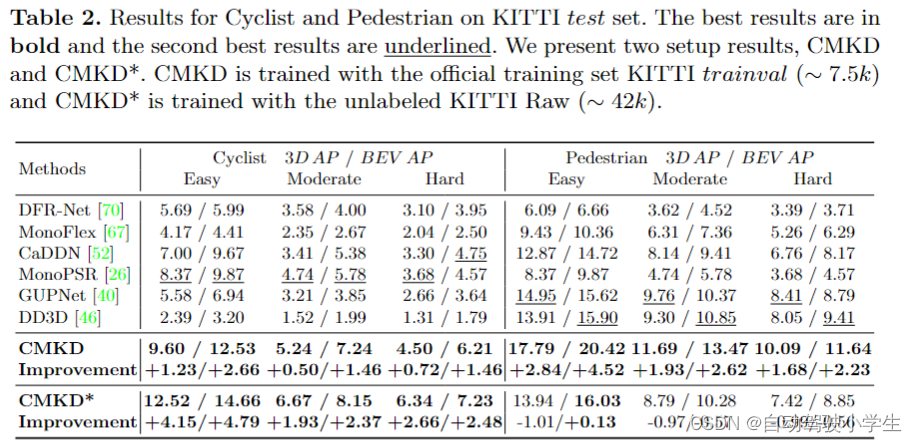
results on kitti test set
下面介绍本文的实验,本文做的实验比较多。首先是在kitti测试集上的实验,可以看到,使用更多无标签的数据进行训练,可以有效地从海量未标记数据中提取有益信息并提高性能。 然而,行人的性能随着额外的未标记数据变得更糟,本文进行了额外的实验来探索这一原因。这是因为教师模型为行人提供的软标签质量不足,无法为学生模型提供良好的指导。
ablation studies
下面是消融实验:
- effectiveness of both distillation。当使用深度预训练网络作为图像主干网时,性能与基线相比有了显着提高,这表明 lidar 点提供的准确深度信息有助于该任务。并且当应用本文的每个蒸馏模块时,性能进一步提高,这表明整流模块利用可以更充分利用激光雷达数据的潜力,进一步提高单目3d检测器的性能。
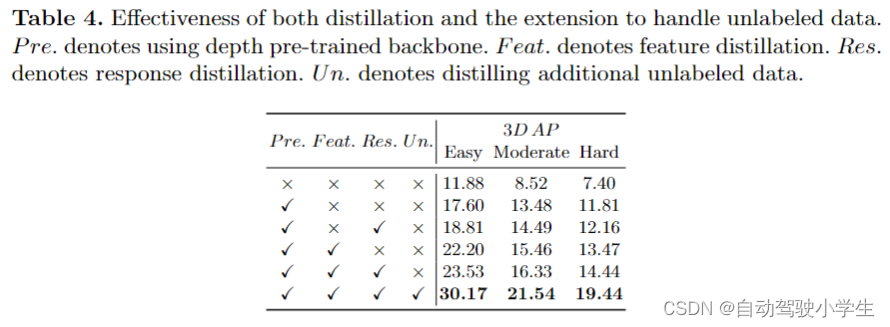
- effectiveness of distilling unlabeled data。当将未标记数据添加到蒸馏模块中,cmkd 的性能进一步提高(表4最后一行所示),这表明本文的方法在从大量未标记数据中提取有益信息并提高性能方面是有效的。具体来说,本文使用18k个样本进行训练,标记样本约 3.7k,本文降低了大约 80% 的注释成本。
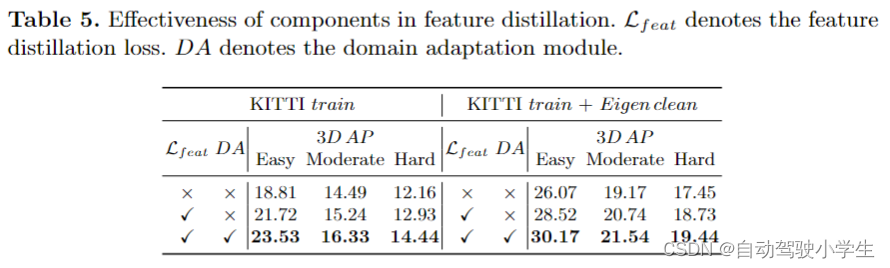
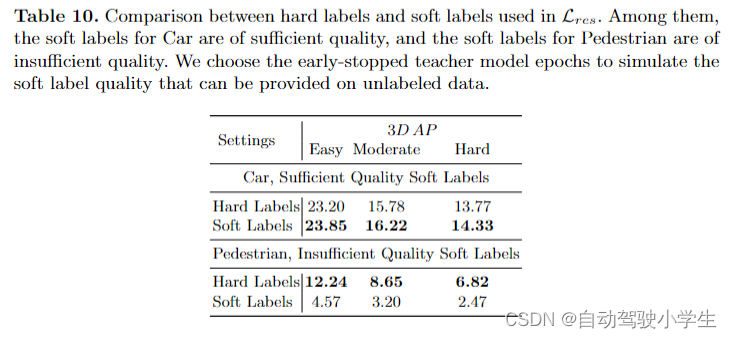
- effectiveness of components in feature distillation。从下表可以看到,在特征蒸馏中,这两个组件对性能的提高都是有帮助的。
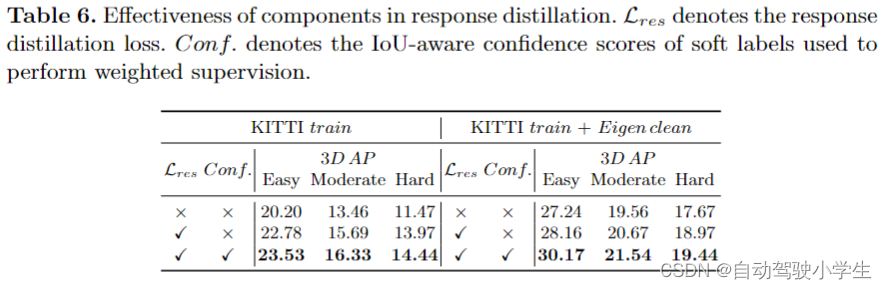
- effectiveness of components in response distillation。从下表可以看到,性能随着响应蒸馏损失的增加而提高,并通过对软标签质量的惩罚(即具有自适应监督)实现了进一步的改进。
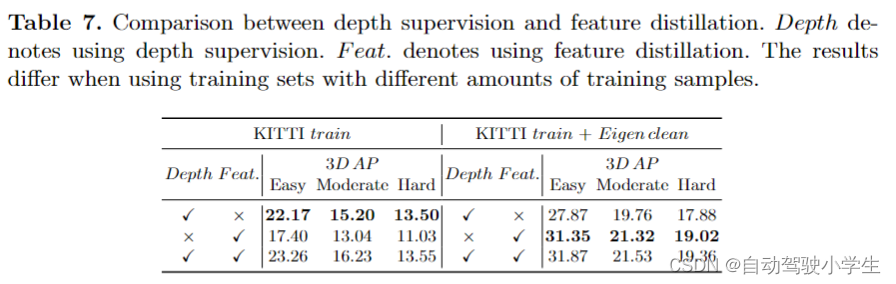
depth supervision vs. feature distillation
这里比较深度监督与特征蒸馏对性能的影响,cmkd在训练阶段直接将显式深度监督添加到模型中,而不是使用深度预训练。深度监督在动机方面类似于特征蒸馏,这两种监督都旨在使图像模型从激光雷达数据中学习准确的3d信息,如深度和几何形状。本文在这两个监督上进行了实验以进行比较。具体来说,本文从cmkd中的单目检测器中删除了特征蒸馏模块,然后将深度损失添加到整体损失函数中。
如下表所示,在不同的训练集上训练模型时,得到了相反的结果。 具体来说,在kitti train上训练模型(约3.7k个样本),使用深度监督明显优于特征蒸馏。在特征蒸馏之上添加深度监督可以带来显着的改进。在 kitti train 和 eigen clean 上训练模型时(使用 18k 个样本),其中训练数据更充分,特征蒸馏的力量被开发,使用特征蒸馏明显优于深度监督。在特征蒸馏之上添加深度监督只能带来有限的改进。
这一观察结果在预期范围内。与明确监督 3d 信息的深度监督相比,特征蒸馏以隐式方式监督深度、几何和对象特征表示,其中所有丰富且有意义的信息都融合在一层 bev 特征中。
- 当训练样本有限时,模型很难正确理解这些隐式模式,模型往往会出现过拟合,因此在这种情况下添加具有显式物理意义的直接深度监督可以帮助模型更好地理解由 bev 特征表示的隐式模式,并带来显着的性能提升。
- 当训练样本变得更加充分时,模型很好地学习了特征蒸馏提供的丰富而有意义的信息,在这种情况下,揭示了特征蒸馏在深度监督方面的优势。同时,模型很好地学习了特征蒸馏中已经隐式包含的深度信息,因此添加额外的深度监督只能提供有限的新信息,并对性能带来有限的改进。
- 基于上述实验和讨论,当训练集较小时,建议使用深度预训练或直接深度监督以及特征蒸馏。当训练样本充足时,特征蒸馏本身效果很好。
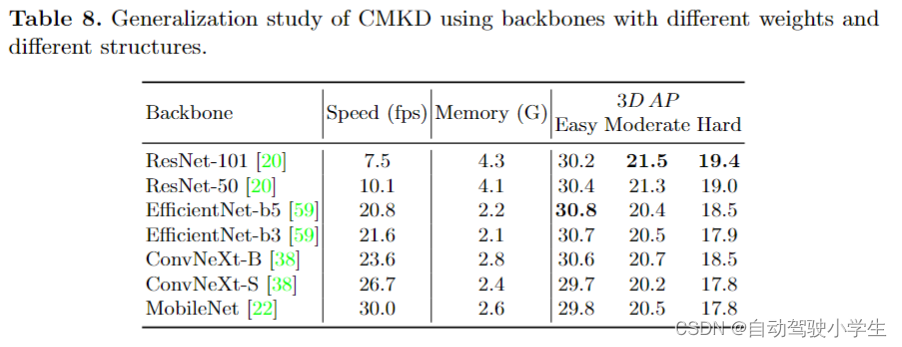
generalization study with different backbones
在这一部分中,本文使用不同的学生模型对cmkd的泛化能力进行了实验。具体来说,选择具有不同权重和不同结构的图像主干网,并比较了 cmkd 的性能,包括运行速度、运行内存和 3d ap。
一方面,本文希望使用具有不同结构的图像主干网来展示 cmkd 的性能,另一方面,也希望展示速度和准确性的综合比较。运行速度和内存在单个 nvidia 3090 gpu 上进行了测试,批量大小为 1,3d ap 在 kitti val 上进行了测试。
从表中可以看出,对于 easy 类别,不同模型之间的性能差距不大,一些轻量级模型甚至比大的模型表现更好。对于moderate和hard类,大的模型的性能优于轻量级模型,但轻量级模型的性能并不算很差。一方面,上述实验证明本文的框架具有良好的泛化性能,可以与具有不同结构和权重的各种主干网合作,以满足不同应用场景的需求。另一方面,它还突出了本文在这项工作中的主要观点,即本文强调的是跨模态知识蒸馏 (cmkd) 框架的想法,而不是框架中使用的特定模型。
potential limitation of cmkd: soft label quality matters
为了使本文的工作更加全面和完整,这里探索 cmkd 的局限性并提供对应的解决方案。注意到 cmkd 可能存在以下限制,即软标注质量很重要。
从表9可以看到,cmkd*(约42k个训练样本)在car和cyclist上的性能比cmkd要好得多(训练样本约7.5k),而行人上的性能正好相反,即训练样本越多,结果越差。 这是因为汽车、骑自行车和行人的软标签质量之间存在很大差距。在中等水平的kitti排行榜上,基于激光雷达的汽车、自行车和行人检测器的性能约为80、70和40,行人的预测质量与汽车和骑自行车的水平十分不同。 也就是说,教师模型为行人自己提供的软标签质量非常低,不能作为学生模型的良好指导。本文的框架在未标记数据上的训练假设教师模型提供的软标注质量足够, 对于汽车和骑自行车的人是足够但行人是不够的。
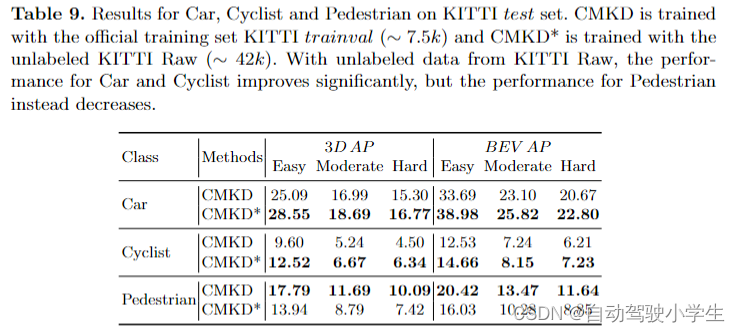
为了验证上述讨论,本文进行了额外的实验。具体来说,选择了 car 和 pestrian 两类,并使用 kitti train 中的真值和软标注分别监督它们,并报告 kitti val 的性能以进行比较实验。对于软标签,我们选择在kitti val上的性能接近kitti测试集上的模型(car为3d ap≈80%,行人为3d ap≈40%),以模拟教师模型在未标记数据上提供的软标注质量。
从表中可以看出。对于 car,足够质量的软标签可以提供有用的信息,使用软标注的结果优于使用硬标注。但是对于行人来说,质量不足的软标注不能提供有效的指导,因此结果远不如使用真值。当我们在未标记数据上训练 cmkd 时,教师模型可以从海量未标记数据中提取 car 的有益信息并将其转移到学生模型中,从而提高学生模型的性能。但是对于行人来说,教师模型本身提供的软标注质量不足,不能作为学生模型的良好指导,而是降低了学生模型的性能。当软标注的质量很差时,本文提供的解决方案是在不改变整体框架的情况下将软标注更改为真值。
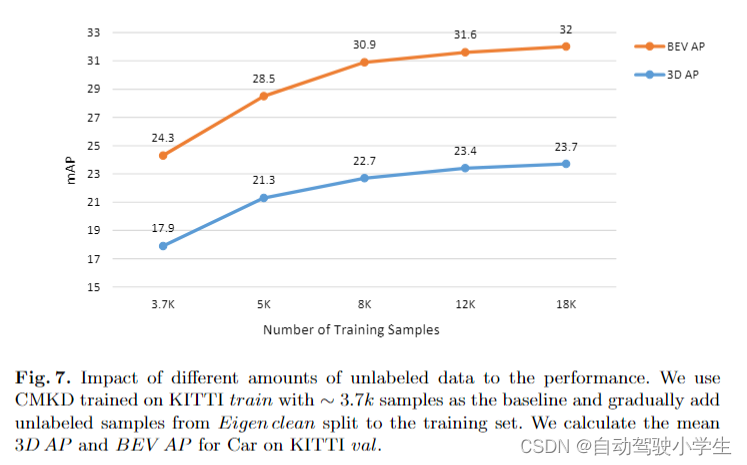
impact of different amounts of unlabeled data
在本节中,通过实验来探索不同数量的未标记数据对性能的影响。基线是在 kitti 训练集上训练的 cmkd,样本量约为 3.7k,逐渐将 eigen clean split 的未标记样本添加到训练集中。计算car在kitti val上的3d ap和bev ap。
从下图可以看出,随着未标记样本数量的增加,cmkd的性能有所提高。
- 具体来说,当训练样本有限时(例如只有3.7k 个样本,这对于像 cmkd 这样的深度网络训练非常少),少量未标记样本(1.3k)可以带来显着的性能提升。
- 当未标记样本的数量变大时(分别为 +4.3k、+8.3k、+14.3k),性能改进的幅度趋于平和。这与在其他任务中使用额外的未标记数据进行预训练的性能提升趋势是一致的。请注意,这里额外的未标记数据的数量及其提供的信息不是线性的。如前所述,kitti 3d 是 kitti raw 的子集,kitti raw 是连续序列形式,因此存在大量相似、重复的样本,只能提供有限的新信息。



发表评论