需求
产品希望我们这边能够实现用户上传pdf、word、txt之内得文本内容,然后用户可以根据附件名称或文件内容模糊查询文件信息,并可以在线查看文件内容。
一、环境
项目开发环境:
后台管理系统springboot+mybatis_plus+mysql+es
搜索引擎:elasticsearch7.9.3 +kibana图形化界面
二、功能实现
1.搭建环境
es+kibana的搭建这里就不介绍了,网上多的是
后台程序搭建也不介绍,这里有一点很重要,java使用的连接es的包的版本一定要和es的版本对应上,不然你会有各种问题
2.文件内容识别
第一步: 要用es实现文本附件内容的识别,需要先给es安装一个插件:ingest attachment processor plugin
这知识一个内容识别的插件,还有其它的例如ocr之类的其它插件,有兴趣的可以去搜一下了解一下
ingest attachment processor plugin是一个文本抽取插件,本质上是利用了elasticsearch的ingest node功能,提供了关键的预处理器attachment。在安装目录下运行以下命令即可安装。
到es的安装文件bin目录下执行
elasticsearch-plugin install ingest-attachment
因为我们这里es是使用docker安装的,所以需要进入到es的docker镜像里面的bin目录下安装插件
[root@izuf63d0pqnjrga4pi18udz plugins]# docker exec -it es bash
[root@elasticsearch elasticsearch]# ls
license.txt notice.txt readme.asciidoc bin config data jdk lib logs modules plugins
[root@elasticsearch elasticsearch]# cd bin/
[root@elasticsearch bin]# ls
elasticsearch elasticsearch-certutil elasticsearch-croneval elasticsearch-env-from-file elasticsearch-migrate elasticsearch-plugin elasticsearch-setup-passwords elasticsearch-sql-cli elasticsearch-syskeygen x-pack-env x-pack-watcher-env
elasticsearch-certgen elasticsearch-cli elasticsearch-env elasticsearch-keystore elasticsearch-node elasticsearch-saml-metadata elasticsearch-shard elasticsearch-sql-cli-7.9.3.jar elasticsearch-users x-pack-security-env
[root@elasticsearch bin]# elasticsearch-plugin install ingest-attachment
-> installing ingest-attachment
-> downloading ingest-attachment from elastic
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ warning: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.runtimepermission accessclassinpackage.sun.java2d.cmm.kcms
* java.lang.runtimepermission accessdeclaredmembers
* java.lang.runtimepermission getclassloader
* java.lang.reflect.reflectpermission suppressaccesschecks
* java.security.securitypermission createaccesscontrolcontext
* java.security.securitypermission insertprovider
* java.security.securitypermission putproviderproperty.bc
see http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
continue with installation? [y/n]y
-> installed ingest-attachment
显示installed 就表示安装完成了,然后重启es,不然第二步要报错
第二步:创建一个文本抽取的管道
主要是用于将上传的附件转换成文本内容,支持(word,pdf,txt,excel没试,应该也支持)
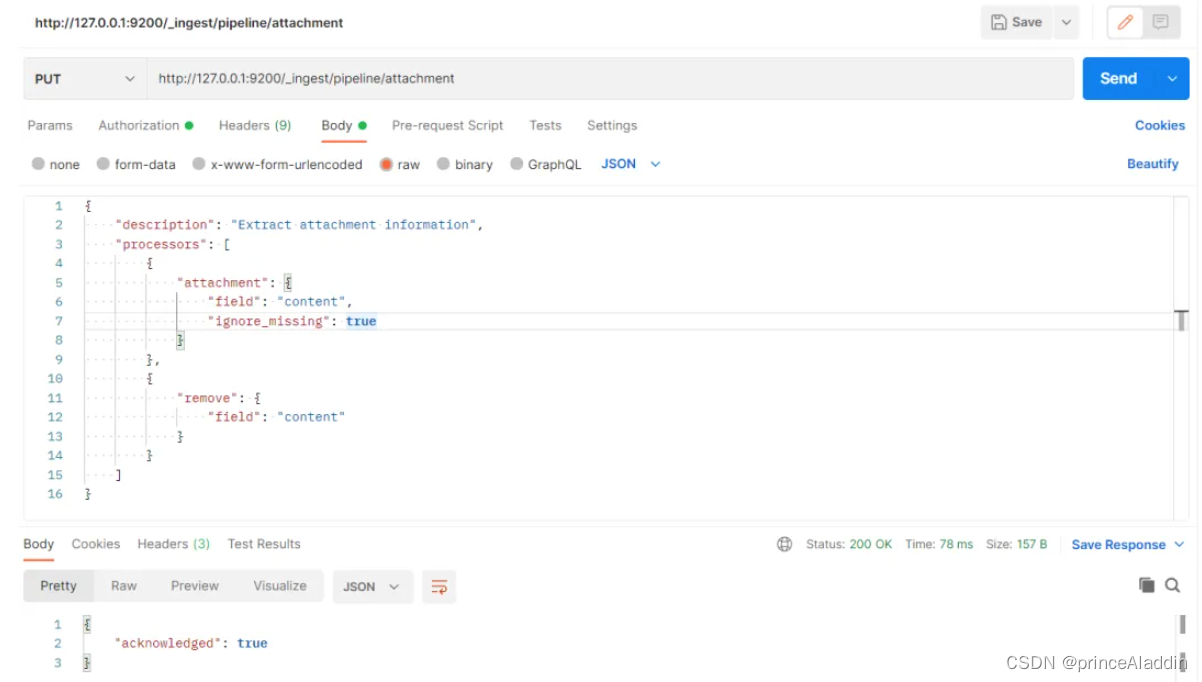
{
"description": "extract attachment information",
"processors": [
{
"attachment": {
"field": "content",
"ignore_missing": true
}
},
{
"remove": {
"field": "content"
}
}
]
}
第三步:定义我们内容存储的索引
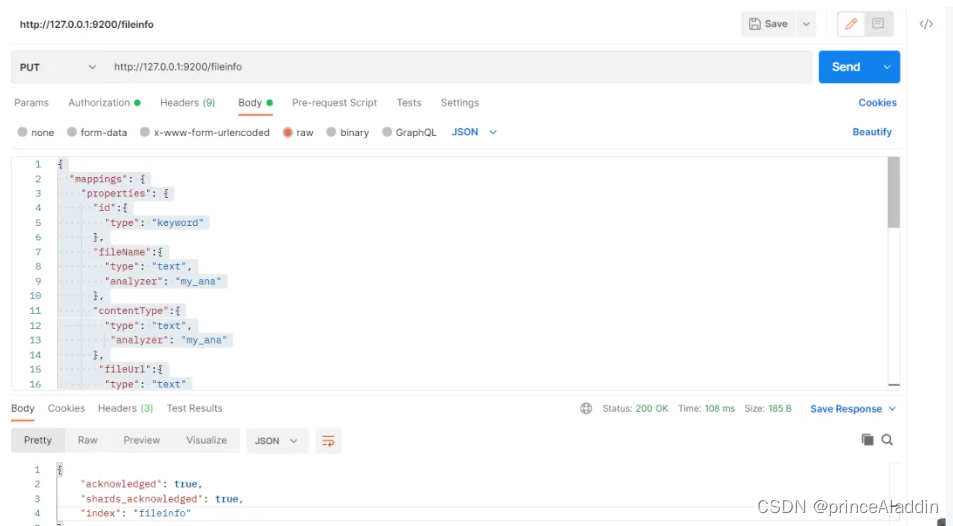
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"filename":{
"type": "text",
"analyzer": "my_ana"
},
"contenttype":{
"type": "text",
"analyzer": "my_ana"
},
"fileurl":{
"type": "text"
},
"attachment": {
"properties": {
"content":{
"type": "text",
"analyzer": "my_ana"
}
}
}
}
},
"settings": {
"analysis": {
"filter": {
"jieba_stop": {
"type": "stop",
"stopwords_path": "stopword/stopwords.txt"
},
"jieba_synonym": {
"type": "synonym",
"synonyms_path": "synonym/synonyms.txt"
}
},
"analyzer": {
"my_ana": {
"tokenizer": "jieba_index",
"filter": [
"lowercase",
"jieba_stop",
"jieba_synonym"
]
}
}
}
}
}
mapping:定义的是存储的字段格式
setting:索引的配置信息,这边定义了一个分词(使用的是jieba的分词)
第四步:测试
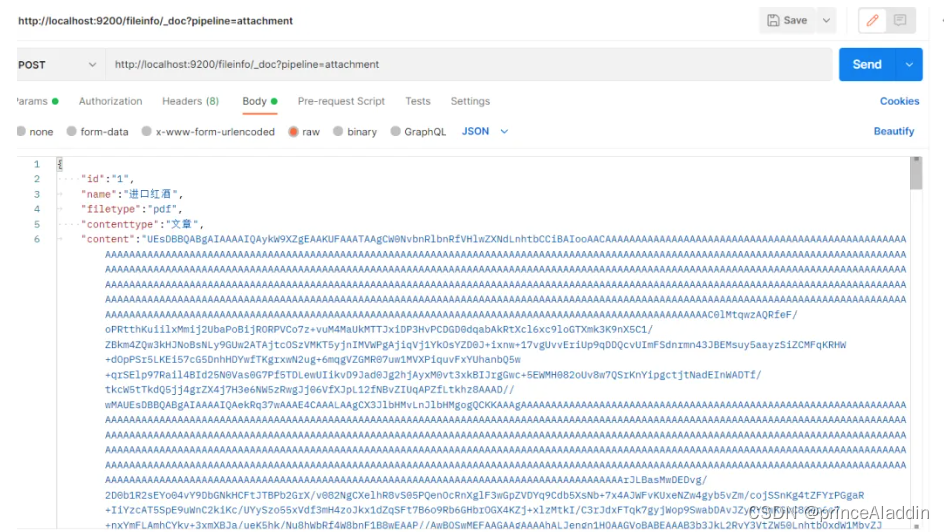
{
"id":"1",
"name":"进口红酒",
"filetype":"pdf",
"contenttype":"文章",
"content":"文章内容"
}
测试内容需要将附件转换成base64格式
在线转换文件的地址:https://www.zhangxinxu.com/sp/base64.html
查询刚刚上传的文件:
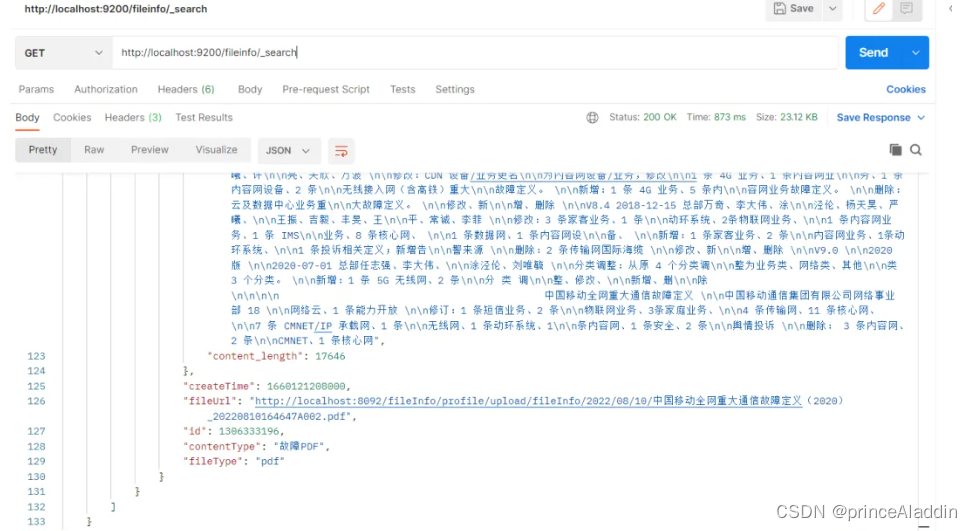
{
"took": 861,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "lkpegyibz3nlbkqzxyx9",
"_score": 1.0,
"_source": {
"filename": "测试_20220809164145a002.docx",
"updatetime": 1660034506000,
"attachment": {
"date": "2022-08-09t01:38:00z",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"author": "dell",
"language": "lt",
"content": "内容",
"content_length": 2572
},
"createtime": 1660034506000,
"fileurl": "http://localhost:8092/fileinfo/profile/upload/fileinfo/2022/08/09/测试_20220809164145a002.docx",
"id": 1306333192,
"contenttype": "文章",
"filetype": "docx"
}
},
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "muphgyibz3nlbkqzwivw",
"_score": 1.0,
"_source": {
"filename": "测试_20220809164527a001.docx",
"updatetime": 1660034728000,
"attachment": {
"date": "2022-08-09t01:38:00z",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"author": "dell",
"language": "lt",
"content": "内容",
"content_length": 2572
},
"createtime": 1660034728000,
"fileurl": "http://localhost:8092/fileinfo/profile/upload/fileinfo/2022/08/09/测试_20220809164527a001.docx",
"id": 1306333193,
"contenttype": "文章",
"filetype": "docx"
}
},
{
"_index": "fileinfo",
"_type": "_doc",
"_id": "jdqshoibbktnu1ugkzfk",
"_score": 1.0,
"_source": {
"filename": "txt测试_20220810153351a001.txt",
"updatetime": 1660116831000,
"attachment": {
"content_type": "text/plain; charset=utf-8",
"language": "lt",
"content": "内容",
"content_length": 804
},
"createtime": 1660116831000,
"fileurl": "http://localhost:8092/fileinfo/profile/upload/fileinfo/2022/08/10/txt测试_20220810153351a001.txt",
"id": 1306333194,
"contenttype": "告示",
"filetype": "txt"
}
}
]
}
}
我们调用上传的接口,可以看到文本内容已经抽取到es里面了,后面就可以直接分词检索内容,高亮显示了
三.代码
介绍下代码实现逻辑:文件上传,数据库存储附件信息和附件上传地址;调用es实现文本内容抽取,将抽取的内容放到对应索引下;提供小程序全文检索的api实现根据文件名称关键词联想,文件名称内容全文检索模糊匹配,并高亮显示分词匹配字段;直接贴代码
yml配置文件:
# 数据源配置
spring:
# 服务模块
devtools:
restart:
# 热部署开关
enabled: true
# 搜索引擎
elasticsearch:
rest:
url: 127.0.0.1
uris: 127.0.0.1:9200
connection-timeout: 1000
read-timeout: 3000
username: elastic
password: 123456
elsticsearchconfig(连接配置)
package com.yj.rselasticsearch.domain.config;
import org.apache.http.httphost;
import org.apache.http.auth.authscope;
import org.apache.http.auth.usernamepasswordcredentials;
import org.apache.http.impl.client.basiccredentialsprovider;
import org.elasticsearch.client.restclient;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.time.duration;
@configuration
public class elasticsearchconfig {
@value("${spring.elasticsearch.rest.url}")
private string edurl;
@value("${spring.elasticsearch.rest.username}")
private string username;
@value("${spring.elasticsearch.rest.password}")
private string password;
@bean
public resthighlevelclient resthighlevelclient() {
//设置连接的用户名密码
final basiccredentialsprovider credentialsprovider = new basiccredentialsprovider();
credentialsprovider.setcredentials(authscope.any, new usernamepasswordcredentials(username, password));
resthighlevelclient client = new resthighlevelclient(restclient.builder(
new httphost(edurl, 9200,"http"))
.sethttpclientconfigcallback(httpclientbuilder -> {
httpclientbuilder.disableauthcaching();
//保持连接池处于链接状态,该bug曾导致es一段时间没使用,第一次连接访问超时
httpclientbuilder.setkeepalivestrategy(((response, context) -> duration.ofminutes(5).tomillis()));
return httpclientbuilder.setdefaultcredentialsprovider(credentialsprovider);
})
);
return client;
}
}
文件上传保存文件信息并抽取内容到es
实体对象fileinfo
package com.yj.common.core.domain.entity;
import com.baomidou.mybatisplus.annotation.tablefield;
import com.yj.common.core.domain.baseentity;
import lombok.data;
import lombok.equalsandhashcode;
import lombok.getter;
import lombok.setter;
import org.springframework.data.elasticsearch.annotations.document;
import org.springframework.data.elasticsearch.annotations.field;
import org.springframework.data.elasticsearch.annotations.fieldtype;
import java.util.date;
@setter
@getter
@document(indexname = "fileinfo",createindex = false)
public class fileinfo {
/**
* 主键
*/
@field(name = "id", type = fieldtype.integer)
private integer id;
/**
* 文件名称
*/
@field(name = "filename", type = fieldtype.text,analyzer = "jieba_index",searchanalyzer = "jieba_index")
private string filename;
/**
* 文件类型
*/
@field(name = "filetype", type = fieldtype.keyword)
private string filetype;
/**
* 内容类型
*/
@field(name = "contenttype", type = fieldtype.text)
private string contenttype;
/**
* 附件内容
*/
@field(name = "attachment.content", type = fieldtype.text,analyzer = "jieba_index",searchanalyzer = "jieba_index")
@tablefield(exist = false)
private string content;
/**
* 文件地址
*/
@field(name = "fileurl", type = fieldtype.text)
private string fileurl;
/**
* 创建时间
*/
private date createtime;
/**
* 更新时间
*/
private date updatetime;
}
controller类
package com.yj.rselasticsearch.controller;
import com.yj.common.core.controller.basecontroller;
import com.yj.common.core.domain.ajaxresult;
import com.yj.common.core.domain.entity.fileinfo;
import com.yj.rselasticsearch.service.fileinfoservice;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.multipartfile;
import javax.annotation.resource;
/**
* (file_info)表控制层
*
* @author xxxxx
*/
@restcontroller
@requestmapping("/fileinfo")
public class fileinfocontroller extends basecontroller {
/**
* 服务对象
*/
@resource
private fileinfoservice fileinfoservice;
@putmapping("uploadfile")
public ajaxresult uploadfile(string contenttype, multipartfile file) {
return fileinfoservice.uploadfileinfo(contenttype,file);
}
}
serviceimpl实现类
package com.yj.rselasticsearch.service.impl;
import com.alibaba.fastjson.json;
import com.baomidou.mybatisplus.core.conditions.query.lambdaquerywrapper;
import com.yj.common.config.ruoyiconfig;
import com.yj.common.core.domain.ajaxresult;
import com.yj.common.utils.fastutils;
import com.yj.common.utils.stringutils;
import com.yj.common.utils.file.fileuploadutils;
import com.yj.common.utils.file.fileutils;
import com.yj.framework.config.serverconfig;
import lombok.extern.slf4j.slf4j;
import org.elasticsearch.action.index.indexrequest;
import org.elasticsearch.action.index.indexresponse;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.client.resthighlevelclient;
import org.elasticsearch.common.xcontent.xcontenttype;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.data.elasticsearch.core.elasticsearchresttemplate;
import org.springframework.stereotype.service;
import javax.annotation.resource;
import com.yj.common.core.domain.entity.fileinfo;
import com.yj.rselasticsearch.mapper.fileinfomapper;
import com.yj.rselasticsearch.service.fileinfoservice;
import org.springframework.web.multipart.multipartfile;
import java.io.file;
import java.io.fileinputstream;
import java.io.ioexception;
import java.util.base64;
@service
@slf4j
public class fileinfoserviceimpl implements fileinfoservice{
@resource
private serverconfig serverconfig;
@autowired
@qualifier("resthighlevelclient")
private resthighlevelclient client;
@resource
private fileinfomapper fileinfomapper;
/**
* 上传文件并进行文件内容识别上传到es
* @param contenttype
* @param file
* @return
*/
@override
public ajaxresult uploadfileinfo(string contenttype, multipartfile file) {
if (fastutils.checknullorempty(contenttype,file)){
return ajaxresult.error("请求参数不能为空");
}
try {
// 上传文件路径
string filepath = ruoyiconfig.getuploadpath() + "/fileinfo";
fileinfo fileinfo = new fileinfo();
// 上传并返回新文件名称
string filename = fileuploadutils.upload(filepath, file);
string prefix = filename.substring(filename.lastindexof(".")+1);
file files = file.createtempfile(filename, prefix);
file.transferto(files);
string url = serverconfig.geturl() + "/fileinfo" + filename;
fileinfo.setfilename(fileutils.getname(filename));
fileinfo.setfiletype(prefix);
fileinfo.setfileurl(url);
fileinfo.setcontenttype(contenttype);
int result = fileinfomapper.insertselective(fileinfo);
if (result > 0) {
fileinfo = fileinfomapper.selectone(new lambdaquerywrapper<fileinfo>().eq(fileinfo::getfileurl,fileinfo.getfileurl()));
byte[] bytes = getcontent(files);
string base64 = base64.getencoder().encodetostring(bytes);
fileinfo.setcontent(base64);
indexrequest indexrequest = new indexrequest("fileinfo");
//上传同时,使用attachment pipline进行提取文件
indexrequest.source(json.tojsonstring(fileinfo), xcontenttype.json);
indexrequest.setpipeline("attachment");
indexresponse indexresponse = client.index(indexrequest, requestoptions.default);
log.info("indexresponse:" + indexresponse);
}
ajaxresult ajax = ajaxresult.success(fileinfo);
return ajax;
} catch (exception e) {
return ajaxresult.error(e.getmessage());
}
}
/**
* 文件转base64
*
* @param file
* @return
* @throws ioexception
*/
private byte[] getcontent(file file) throws ioexception {
long filesize = file.length();
if (filesize > integer.max_value) {
log.info("file too big...");
return null;
}
fileinputstream fi = new fileinputstream(file);
byte[] buffer = new byte[(int) filesize];
int offset = 0;
int numread = 0;
while (offset < buffer.length
&& (numread = fi.read(buffer, offset, buffer.length - offset)) >= 0) {
offset += numread;
}
// 确保所有数据均被读取
if (offset != buffer.length) {
throw new serviceexception("could not completely read file "
+ file.getname());
}
fi.close();
return buffer;
}
}
高亮分词检索
参数请求warninginfodto
package com.yj.rselasticsearch.domain.dto;
import com.yj.common.core.domain.entity.warninginfo;
import io.swagger.annotations.apimodel;
import io.swagger.annotations.apimodelproperty;
import lombok.data;
import java.util.list;
/**
* 前端请求数据传输
* warninginfo
* @author luoy
*/
@data
@apimodel(value ="warninginfodto",description = "告警信息")
public class warninginfodto{
/**
* 页数
*/
@apimodelproperty("页数")
private integer pageindex;
/**
* 每页数量
*/
@apimodelproperty("每页数量")
private integer pagesize;
/**
* 查询关键词
*/
@apimodelproperty("查询关键词")
private string keyword;
/**
* 内容类型
*/
private list<string> contenttype;
/**
* 用户手机号
*/
private string phone;
}
controller类
package com.yj.rselasticsearch.controller;
import com.baomidou.mybatisplus.core.metadata.ipage;
import com.yj.common.core.controller.basecontroller;
import com.yj.common.core.domain.ajaxresult;
import com.yj.common.core.domain.entity.fileinfo;
import com.yj.common.core.domain.entity.warninginfo;
import com.yj.rselasticsearch.service.elasticsearchservice;
import com.yj.rselasticsearch.service.warninginfoservice;
import io.swagger.annotations.api;
import io.swagger.annotations.apiimplicitparam;
import io.swagger.annotations.apiimplicitparams;
import io.swagger.annotations.apioperation;
import org.springframework.web.bind.annotation.*;
import com.yj.rselasticsearch.domain.dto.warninginfodto;
import javax.annotation.resource;
import javax.servlet.http.httpservletrequest;
import java.util.list;
/**
* es搜索引擎
*
* @author luoy
*/
@api("搜索引擎")
@restcontroller
@requestmapping("es")
public class elasticsearchcontroller extends basecontroller {
@resource
private elasticsearchservice elasticsearchservice;
/**
* 告警信息关键词联想
*
* @param warninginfodto
* @return
*/
@apioperation("关键词联想")
@apiimplicitparams({
@apiimplicitparam(name = "contenttype", value = "文档类型", required = true, datatype = "string", datatypeclass = string.class),
@apiimplicitparam(name = "keyword", value = "关键词", required = true, datatype = "string", datatypeclass = string.class)
})
@postmapping("getassociationalworddoc")
public ajaxresult getassociationalworddoc(@requestbody warninginfodto warninginfodto, httpservletrequest request) {
list<string> words = elasticsearchservice.getassociationalwordother(warninginfodto,request);
return ajaxresult.success(words);
}
/**
* 告警信息高亮分词分页查询
*
* @param warninginfodto
* @return
*/
@apioperation("高亮分词分页查询")
@apiimplicitparams({
@apiimplicitparam(name = "keyword", value = "关键词", required = true, datatype = "string", datatypeclass = string.class),
@apiimplicitparam(name = "pageindex", value = "页码", required = true, datatype = "integer", datatypeclass = integer.class),
@apiimplicitparam(name = "pagesize", value = "页数", required = true, datatype = "integer", datatypeclass = integer.class),
@apiimplicitparam(name = "contenttype", value = "文档类型", required = true, datatype = "string", datatypeclass = string.class)
})
@postmapping("queryhighlightworddoc")
public ajaxresult queryhighlightworddoc(@requestbody warninginfodto warninginfodto,httpservletrequest request) {
ipage<fileinfo> warninginfolistpage = elasticsearchservice.queryhighlightwordother(warninginfodto,request);
return ajaxresult.success(warninginfolistpage);
}
}
serviceimpl实现类
package com.yj.rselasticsearch.service.impl;
import com.alibaba.fastjson.json;
import com.baomidou.mybatisplus.core.conditions.query.lambdaquerywrapper;
import com.baomidou.mybatisplus.core.metadata.ipage;
import com.baomidou.mybatisplus.extension.plugins.pagination.page;
import com.yj.common.constant.dataconstants;
import com.yj.common.constant.httpstatus;
import com.yj.common.core.domain.entity.fileinfo;
import com.yj.common.core.domain.entity.warninginfo;
import com.yj.common.core.domain.entity.whitelist;
import com.yj.common.core.redis.rediscache;
import com.yj.common.exception.serviceexception;
import com.yj.common.utils.fastutils;
import com.yj.rselasticsearch.domain.dto.retrievalrecorddto;
import com.yj.rselasticsearch.domain.dto.warninginfodto;
import com.yj.rselasticsearch.domain.vo.membervo;
import com.yj.rselasticsearch.service.*;
import lombok.extern.slf4j.slf4j;
import org.elasticsearch.action.bulk.bulkrequest;
import org.elasticsearch.action.bulk.bulkresponse;
import org.elasticsearch.action.index.indexrequest;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.client.resthighlevelclient;
import org.elasticsearch.common.xcontent.xcontenttype;
import org.elasticsearch.index.query.boolquerybuilder;
import org.elasticsearch.index.query.operator;
import org.elasticsearch.index.query.querybuilders;
import org.elasticsearch.search.fetch.subphase.highlight.highlightbuilder;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.data.domain.pagerequest;
import org.springframework.data.domain.pageable;
import org.springframework.data.elasticsearch.core.elasticsearchresttemplate;
import org.springframework.data.elasticsearch.core.searchhits;
import org.springframework.data.elasticsearch.core.query.*;
import org.springframework.stereotype.service;
import javax.annotation.resource;
import javax.servlet.http.httpservletrequest;
import java.util.*;
import java.util.stream.collectors;
@service
@slf4j
public class elasticsearchserviceimpl implements elasticsearchservice {
@resource
private whitelistservice whitelistservice;
@autowired
@qualifier("resthighlevelclient")
private resthighlevelclient client;
@autowired
private rediscache rediscache;
@resource
private tokenservice tokenservice;
/**
* 文档信息关键词联想(根据输入框的词语联想文件名称)
*
* @param warninginfodto
* @return
*/
@override
public list<string> getassociationalwordother(warninginfodto warninginfodto, httpservletrequest request) {
//需要查询的字段
boolquerybuilder boolquerybuilder = querybuilders.boolquery()
.should(querybuilders.matchboolprefixquery("filename", warninginfodto.getkeyword()));
//contenttype标签内容过滤
boolquerybuilder.must(querybuilders.termsquery("contenttype", warninginfodto.getcontenttype()));
//构建高亮查询
nativesearchquery searchquery = new nativesearchquerybuilder()
.withquery(boolquerybuilder)
.withhighlightfields(
new highlightbuilder.field("filename")
)
.withhighlightbuilder(new highlightbuilder().pretags("<span style='color:red'>").posttags("</span>"))
.build();
//查询
searchhits<fileinfo> search = null;
try {
search = elasticsearchresttemplate.search(searchquery, fileinfo.class);
} catch (exception ex) {
ex.printstacktrace();
throw new serviceexception(string.format("操作错误,请联系管理员!%s", ex.getmessage()));
}
//设置一个最后需要返回的实体类集合
list<string> resultlist = new linkedlist<>();
//遍历返回的内容进行处理
for (org.springframework.data.elasticsearch.core.searchhit<fileinfo> searchhit : search.getsearchhits()) {
//高亮的内容
map<string, list<string>> highlightfields = searchhit.gethighlightfields();
//将高亮的内容填充到content中
searchhit.getcontent().setfilename(highlightfields.get("filename") == null ? searchhit.getcontent().getfilename() : highlightfields.get("filename").get(0));
if (highlightfields.get("filename") != null) {
resultlist.add(searchhit.getcontent().getfilename());
}
}
//list去重
list<string> newresult = null;
if (!fastutils.checknullorempty(resultlist)) {
if (resultlist.size() > 9) {
newresult = resultlist.stream().distinct().collect(collectors.tolist()).sublist(0, 9);
} else {
newresult = resultlist.stream().distinct().collect(collectors.tolist());
}
}
return newresult;
}
/**
* 高亮分词搜索其它类型文档
*
* @param warninginfodto
* @param request
* @return
*/
@override
public ipage<fileinfo> queryhighlightwordother(warninginfodto warninginfodto, httpservletrequest request) {
//分页
pageable pageable = pagerequest.of(warninginfodto.getpageindex() - 1, warninginfodto.getpagesize());
//需要查询的字段,根据输入的内容分词全文检索filename和content字段
boolquerybuilder boolquerybuilder = querybuilders.boolquery()
.should(querybuilders.matchboolprefixquery("filename", warninginfodto.getkeyword()))
.should(querybuilders.matchboolprefixquery("attachment.content", warninginfodto.getkeyword()));
//contenttype标签内容过滤
boolquerybuilder.must(querybuilders.termsquery("contenttype", warninginfodto.getcontenttype()));
//构建高亮查询
nativesearchquery searchquery = new nativesearchquerybuilder()
.withquery(boolquerybuilder)
.withhighlightfields(
new highlightbuilder.field("filename"), new highlightbuilder.field("attachment.content")
)
.withhighlightbuilder(new highlightbuilder().pretags("<span style='color:red'>").posttags("</span>"))
.build();
//查询
searchhits<fileinfo> search = null;
try {
search = elasticsearchresttemplate.search(searchquery, fileinfo.class);
} catch (exception ex) {
ex.printstacktrace();
throw new serviceexception(string.format("操作错误,请联系管理员!%s", ex.getmessage()));
}
//设置一个最后需要返回的实体类集合
list<fileinfo> resultlist = new linkedlist<>();
//遍历返回的内容进行处理
for (org.springframework.data.elasticsearch.core.searchhit<fileinfo> searchhit : search.getsearchhits()) {
//高亮的内容
map<string, list<string>> highlightfields = searchhit.gethighlightfields();
//将高亮的内容填充到content中
searchhit.getcontent().setfilename(highlightfields.get("filename") == null ? searchhit.getcontent().getfilename() : highlightfields.get("filename").get(0));
searchhit.getcontent().setcontent(highlightfields.get("content") == null ? searchhit.getcontent().getcontent() : highlightfields.get("content").get(0));
resultlist.add(searchhit.getcontent());
}
//手动分页返回信息
ipage<fileinfo> warninginfoipage = new page<>();
warninginfoipage.settotal(search.gettotalhits());
warninginfoipage.setrecords(resultlist);
warninginfoipage.setcurrent(warninginfodto.getpageindex());
warninginfoipage.setsize(warninginfodto.getpagesize());
warninginfoipage.setpages(warninginfoipage.gettotal() % warninginfodto.getpagesize());
return warninginfoipage;
}
}
代码测试:
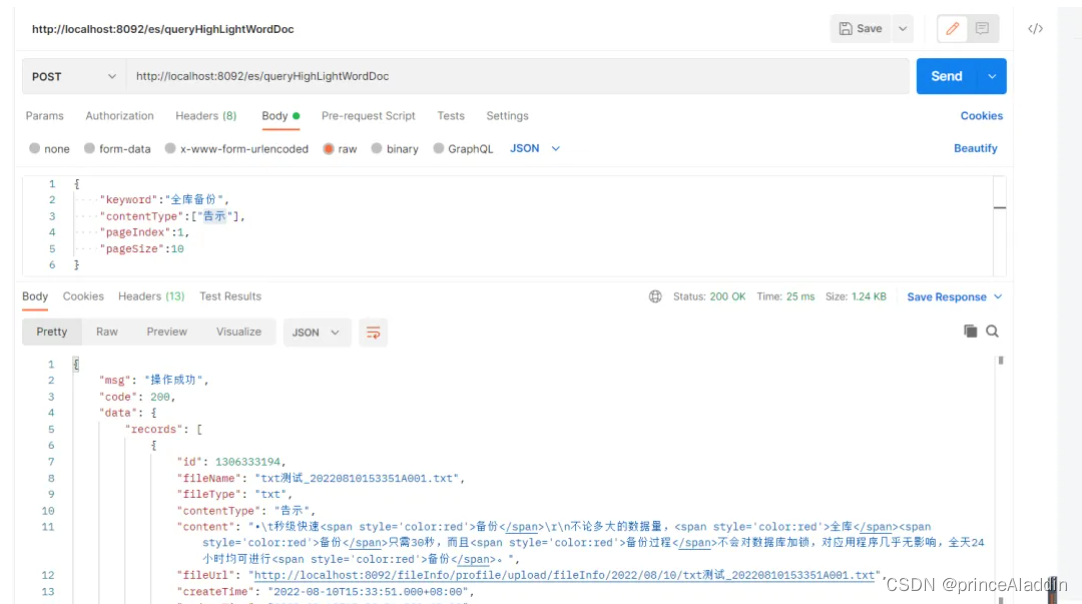
--请求jason
{
"keyword":"全库备份",
"contenttype":["告示"],
"pageindex":1,
"pagesize":10
}
--响应
{
"msg": "操作成功",
"code": 200,
"data": {
"records": [
{
"id": 1306333194,
"filename": "txt测试_20220810153351a001.txt",
"filetype": "txt",
"contenttype": "告示",
"content": "•\t秒级快速<span style='color:red'>备份</span>\r\n不论多大的数据量,<span style='color:red'>全库</span><span style='color:red'>备份</span>只需30秒,而且<span style='color:red'>备份过程</span>不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行<span style='color:red'>备份</span>。",
"fileurl": "http://localhost:8092/fileinfo/profile/upload/fileinfo/2022/08/10/txt测试_20220810153351a001.txt",
"createtime": "2022-08-10t15:33:51.000+08:00",
"updatetime": "2022-08-10t15:33:51.000+08:00"
}
],
"total": 1,
"size": 10,
"current": 1,
"orders": [],
"optimizecountsql": true,
"searchcount": true,
"countid": null,
"maxlimit": null,
"pages": 1
}
}
返回的内容将分词检索到匹配的内容,并将匹配的词高亮显示。

发表评论