深入了解b+树:数据库索引的基础
数据库是现代应用的核心组成部分,对于高效数据检索至关重要。在数据库内部,索引是一种关键的数据结构,用于加速数据查找和访问。其中,b+树是最常见且最重要的索引数据结构之一。本篇博客将深入探讨b+树的原理、特性以及在数据库中的应用。
什么是b+树?
b+树是一种自平衡的树状数据结构,通常用于数据库中的索引。它是一种多路搜索树,具有以下主要特性:
-
多路分支:每个节点可以包含多个子节点,这意味着b+树可以高效地处理大量的数据。
-
自平衡:b+树具有自平衡性质,确保树的高度保持较小,从而保持高效的查询性能。
-
有序性:b+树的节点是有序的,这使得范围查询非常高效,因为查询时只需遍历一次。
-
叶子节点存储数据:b+树的叶子节点存储实际的数据记录,这与其他树状结构(如b树)不同,它们的叶子节点通常存储键值对。
-
分裂和合并:b+树具有分裂和合并节点的机制,以保持树的平衡性。当节点满了时,会分裂为两个节点,而当节点的数据过少时,可以合并为一个节点。
b+树的结构
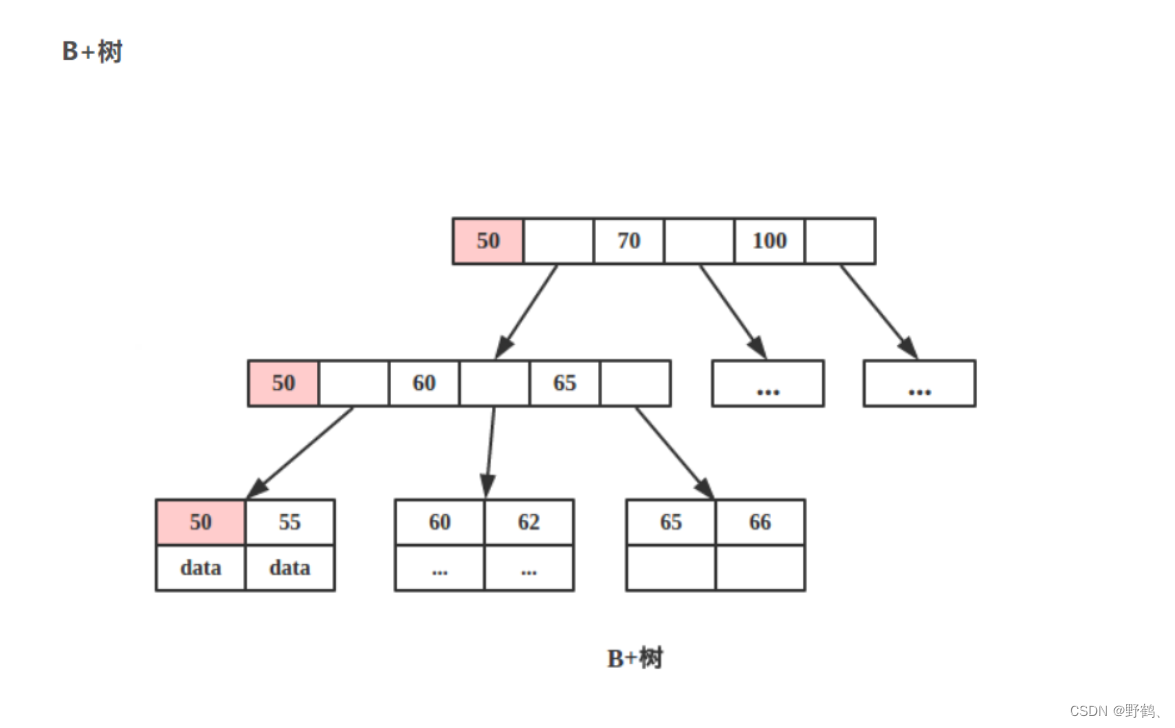
b+树的结构由根节点、中间节点和叶子节点组成。其中,叶子节点存储实际的数据记录,中间节点用于导航到叶子节点,根节点作为树的入口点。
b+树的查询操作从根节点开始,逐级向下导航,直到达到叶子节点。因为叶子节点是有序的,所以可以执行二分查找或类似的算法来查找具体的数据。
b+树在数据库中的应用
b+树在数据库中扮演着重要的角色,它主要用于以下方面:
-
索引:数据库管理系统使用b+树来实现索引,例如b+树索引、聚簇索引等。索引可以加速数据的检索操作,提高数据库的查询性能。
-
范围查询:b+树的有序性质使其非常适合范围查询,例如在某个时间段内检索数据。
-
连接操作:在执行连接操作时,数据库系统可以使用b+树索引来查找匹配的数据行,从而实现高效的连接操作。
-
唯一性约束:b+树索引可以用于确保数据表中的某列具有唯一性,从而实现唯一性约束。
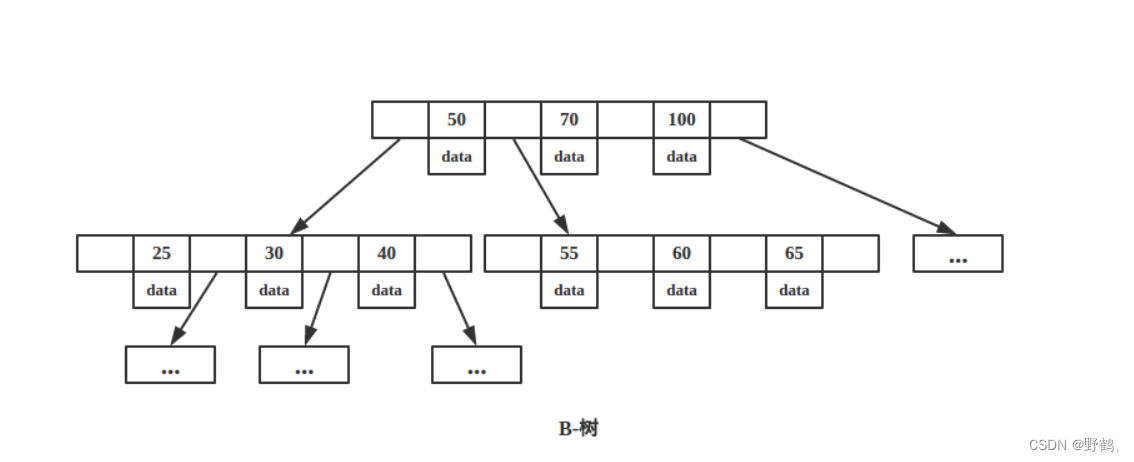
b+树与b树的的区别
b树(b-tree)和b+树(b+ tree)都是常见的自平衡树状数据结构,用于在数据库中实现索引。它们之间存在一些关键区别,以下是b树和b+树之间的主要区别:
-
叶子节点存储数据:
- b树:b树的叶子节点和内部节点都存储键值对(即数据和索引键)。这意味着b树的每个节点都包含实际数据。
- b+树:b+树的叶子节点存储实际数据记录,而内部节点仅存储索引键。这使得b+树在范围查询时更加高效,因为只需要遍历叶子节点。
-
内部节点的子节点数目:
- b树:b树的内部节点通常具有大于两个子节点,子节点数目不是固定的。
- b+树:b+树的内部节点通常具有固定数量的子节点,通常为2个或更多。这样的设计有助于维持树的平衡性。
-
范围查询性能:
- b树:b树在范围查询时性能较差,因为需要在内部节点和叶子节点之间进行多次跳跃,增加了磁盘i/o次数。
- b+树:b+树在范围查询时性能更好,因为范围查询可以在叶子节点之间连续地执行,减少了磁盘i/o次数。
-
叶子节点连接:
- b树:b树的叶子节点之间通常没有连接,数据存储分散在整个树中。
- b+树:b+树的叶子节点之间通常通过指针进行连接,形成一个有序的链表。这使得范围查询和全表扫描更加高效。
-
适用场景:
- b树:b树通常适用于文件系统和某些数据库索引,特别是在需要支持范围查询的情况下。
- b+树:b+树在数据库索引中广泛使用,特别适合需要高效范围查询和全表扫描的情况,如sql数据库中的索引。
综上所述,b树和b+树在设计和应用上有所不同,b+树的叶子节点存储了全部数据记录,适合于范围查询和全表扫描等操作,因此在数据库中得到广泛应用。而b树的使用场景相对较少,更适用于文件系统等领域。在数据库系统中,通常会使用b+树来实现索引结构。
mysql默认用的什么索引
在innodb存储引擎下,当您创建一个表格时,如果没有显式指定主键(primary key),innodb会自动生成一个隐藏的名为gen_clust_index的聚簇索引(clustered index)。这个聚簇索引在innodb中被称为聚簇索引,它的默认类型是b+树索引。
聚簇索引与其他索引的关键区别在于它决定了数据在磁盘上的物理存储顺序。聚簇索引的叶子节点包含整个数据行,而不仅仅是索引键值。这意味着数据行的物理存储顺序与聚簇索引的顺序相同,这有助于高效的按主键检索和范围查询。
需要注意的是,当您显式指定了主键时,innodb将使用您指定的列作为主键,并相应地创建聚簇索引。如果没有指定主键,innodb会选择一个合适的列作为主键,通常是一个自增长的整数列。聚簇索引在innodb中具有特殊的地位,因为它决定了数据行的物理布局,因此对于表的性能和存储结构具有重要影响。
除了聚簇索引,innodb还支持创建其他类型的索引,如唯一索引、普通索引等,以满足不同的查询需求。这些索引通常也是b+树索引,但可以根据需要创建其他类型的索引,如全文索引或空间索引。
总结
b+树是数据库索引的基础,它的高效性能和自平衡性质使其成为许多数据库系统的首选索引结构。了解b+树的原理和应用有助于更好地理解数据库内部的工作方式,并在设计数据库表格和查询时做出明智的决策。无论您是数据库管理员、开发人员还是数据库设计师,都应该深入研究和理解b+树的重要性和应用。

发表评论