基于Doris的日志存储分析平台(同步Kafka日志数据)
【代码】基于Doris的日志存储分析平台(同步Kafka日志数据)
kafka日志写入doris
- 实现方式
- 采用 routine load 官方文档:routine load - apache doris
- 采用 sparkstreaming实时消费kafka后写入doris,在日志记录场景(只写不删,不覆盖,不聚合...),我们使们前者;
- doris 可以通过 routine load 导入方式持续消费 kafka topic 中的数据。在提交 routine load 作业后,doris 会持续运行该导入作业,实时生成导入任务不断消费 kakfa 集群中指定 topic 中的消息。
- 我们的日志数据由log4net推入kafka后是一串json格式,大致如下格式:
[
{
"partition": 0,
"offset": 49,
"msg": "{\"log_timestamp\":1715752796717,\"business\":\"example.business.project\",\"service\":\"example.service\",\"host_ip\":\"yfb-cto\",\"level\":\"info\",\"logger_name\":\"web.controllers.rolecontroller\",\"message\":\"########### \\u8fd9\\u662f\\u624b\\u52a8\\u8f93\\u51fa\\u7684\\u4e2d\\u6587\\u65e5\\u5fd7\\u4fe1\\u606f ###########\",\"request_path\":null,\"request_parameter\":null,\"request_method\":null,\"request_header\":null,\"status_code\":null,\"request_response_time\":0,\"exception\":null}",
"timespan": 1715752796716,
"date": "2024-05-15 13:59:56"
}
]
- 创建 routine load 导入作业
- 语法
-
create routine load [db.]job_name [on tbl_name]
[merge_type]
[load_properties]
[job_properties]
from data_source [data_source_properties]
[comment "comment"]
- 在 doris 中,使用 create routine load 命令,创建导入作业
-
create routine load biz_log_db.ods_example_service_log_routine_load_json on ods_example_service_log
columns(log_timestamp,business,service,host_ip,level,logger_name,message,request_path,request_parameter,request_method,request_header,response_content,status_code,request_response_time,exception,log_time=from_millisecond(log_timestamp))
properties(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false",
"format"="json",
"jsonpaths"="[\"$.log_timestamp\",\"$.business\",\"$.service\",\"$.host_ip\",\"$.level\",\"$.logger_name\",\"$.message\",\"$.request_path\",\"$.request_parameter\",\"$.request_method\",\"$.request_header\",\"$.response_content\",\"$.status_code\",\"$.request_response_time\",\"$.exception\"]"
)
from kafka(
"kafka_broker_list" = "192.168.2.111:9092,192.168.2.184:9092,192.168.2.156:9092",
"kafka_topic" = "example-service-log",
"property.kafka_default_offsets" = "offset_beginning",
"property.deserializer.encoding" = "utf-8"
)
comment "示例服务日志记录同步 kafka routine load 配置";
- 说明
- 请参考官方文档:create-routine-load - apache doris
- 示例中通过 json_root 抽取根节点的元素进行解析,以简化配置。
- offset_beginning: 表示从有数据的位置开始订阅。
- 上述配置表示:自动默认消费所有分区,且从有数据的位置(offset_beginning)开始订阅
- 查看导入运行任务
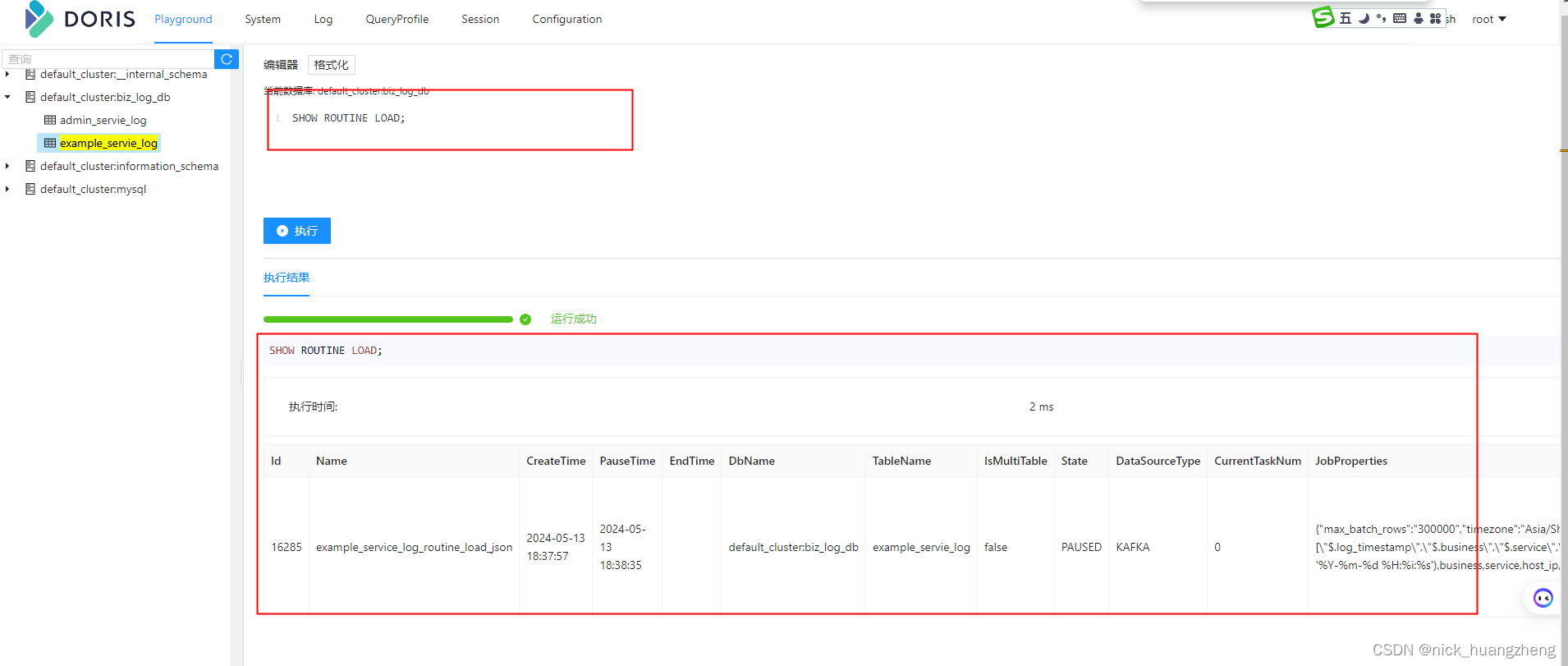
- 查看导入运行作业
- 创建 routine load 任务之后,可以通过show routine load命令查看运行状态的例行任务,如果在show routine load中没有找到对应的例行任务,则可能因为例行任务失败或者错误数过多被停止或者暂停,使用show all routine load查看所有状态的例行任务。
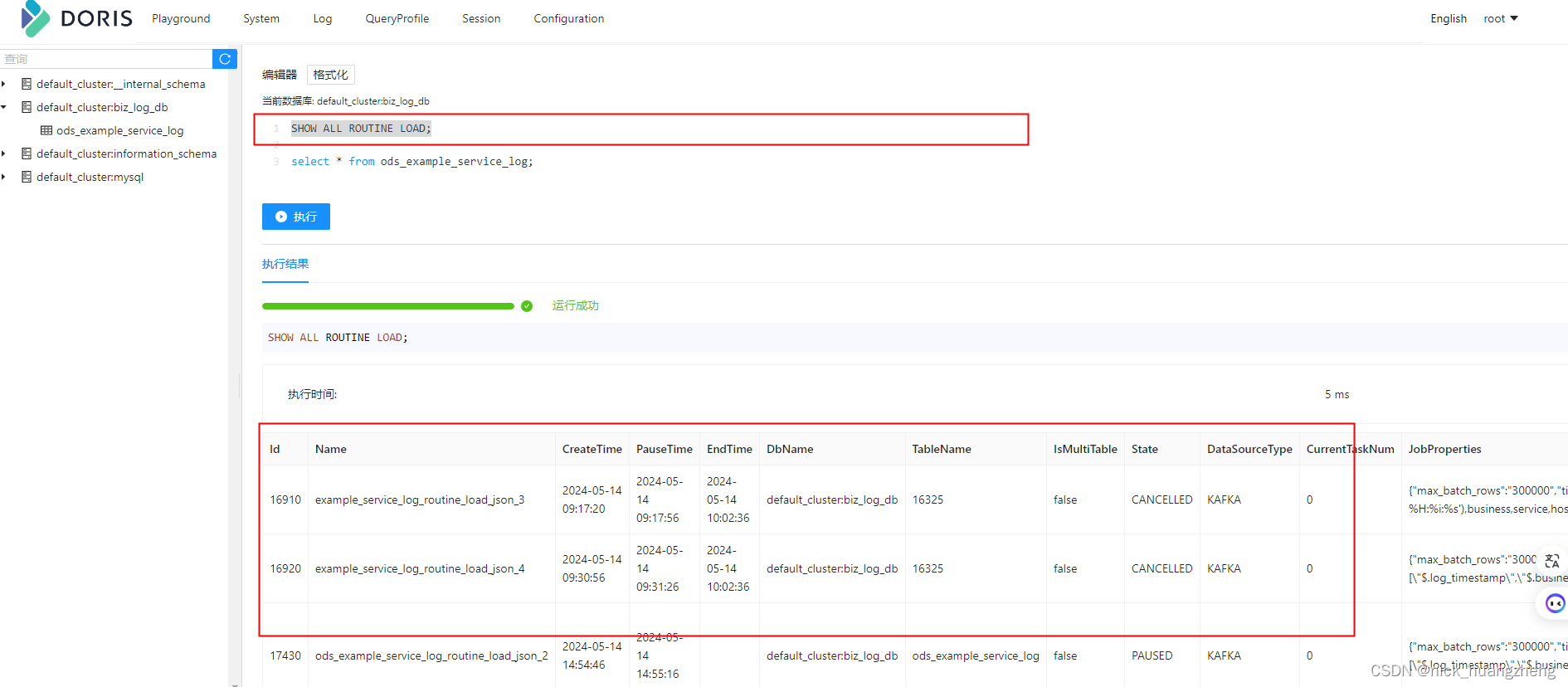
- 暂停导入作业
- 恢复(重启)导入作业
- 修改导入作业
- 取消(停止)导入作业
- 问题排查
- 先执行“show all routine load;”,找出有问题的routine-load,拖到最右边,看到“errorlogurls”,如下:
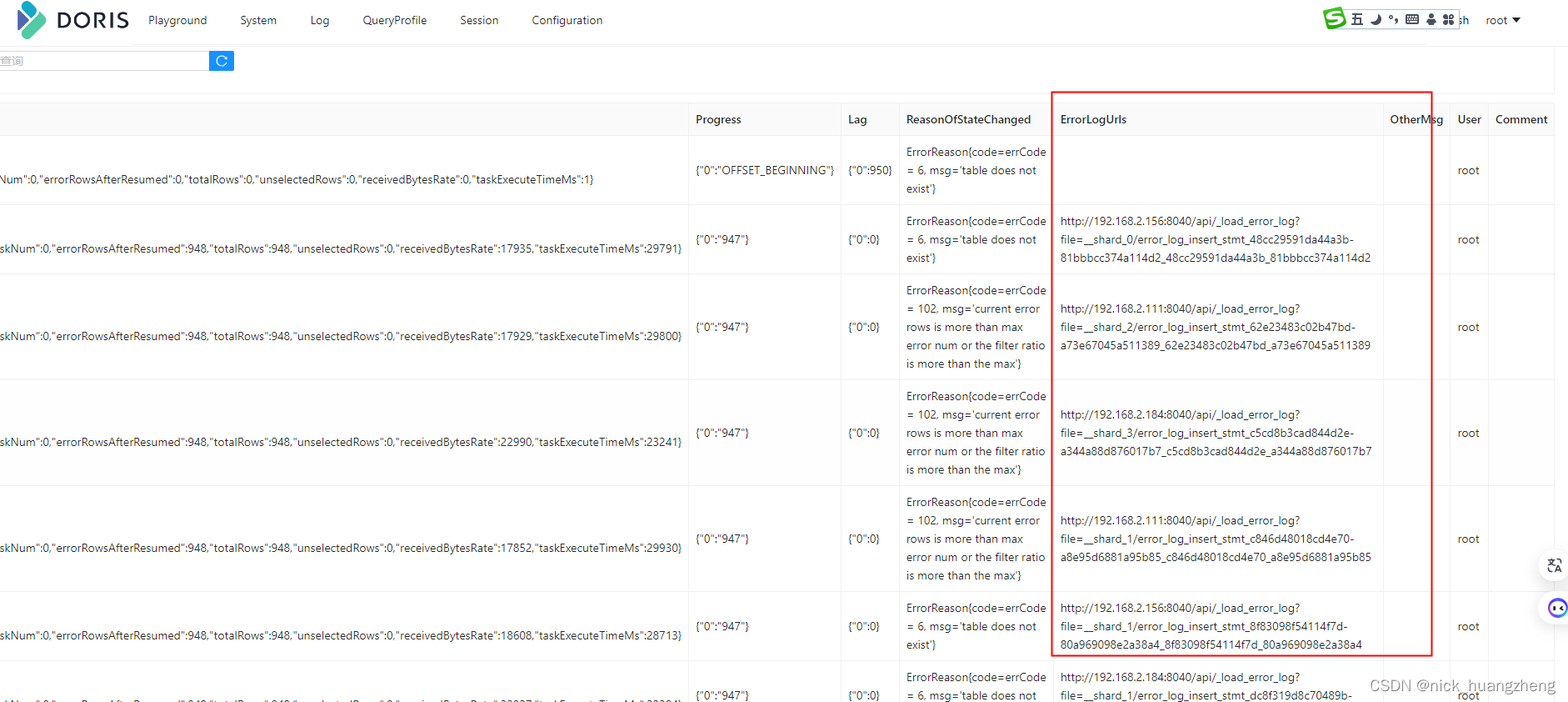
- 复制errorlogurls,在浏览器里打开,查看错误信息,如下:
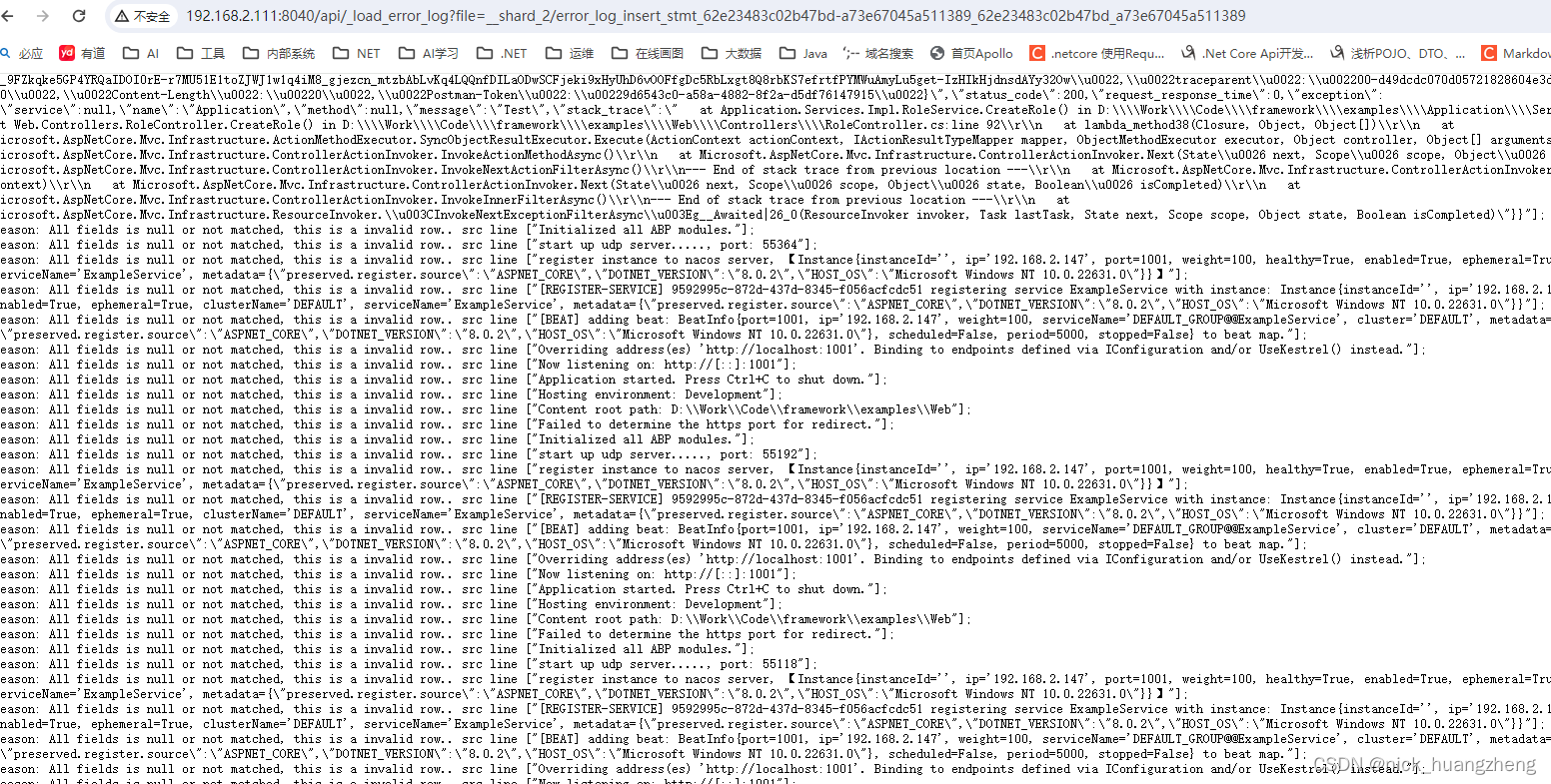
- 看一下数据
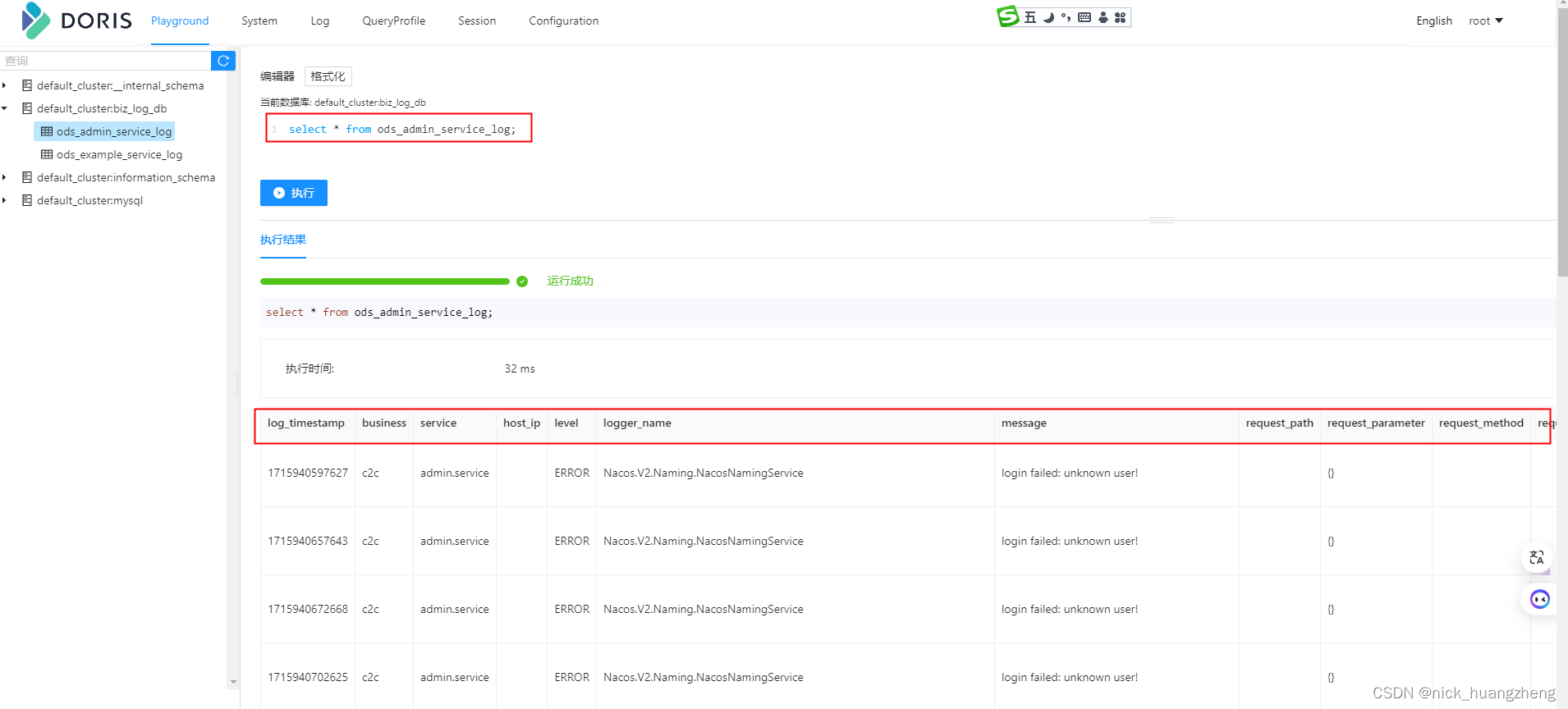
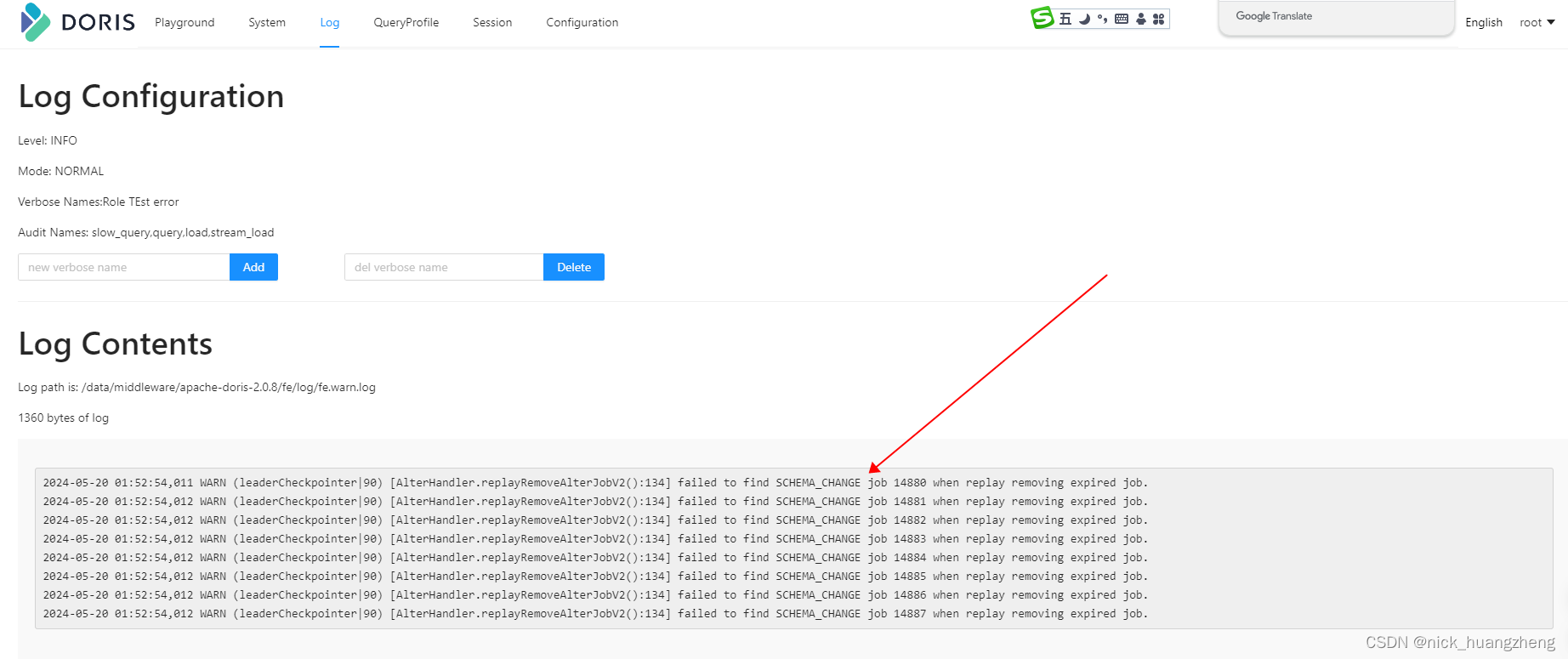
- 最后:经过实测,已经取消的routine load是没办法手动删除的,doris会自动删除,不过这个过程等了好几天,过了一个周未才发现自动删除了已经取消的routine load,如下:
相关文章:
-
元数据管理是对基础库和主题库中的数据项属性的管理,同时,将数据项的业务含义与数据项进行了关联,便于业务人员也能够理解数据库中的数据字段含义,并且,元数据是后面提到的自动化数据共享、…
-
超详细【入门精讲】数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本,参考B站up主哈喽鹏程视频撰写而成,感谢!!!…
-
-
-
-

HDFS 的健壮性体现在哪里?
HDFS 的主要目标就是即使在出错的情况下也要保证数据存储的可靠性。常见的三种出错情况是 Namenode 出错、Datanode 出错和网络割裂,HDFS 提...
[阅读全文]
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。
发表评论