⭐简单说两句⭐
flink状态

flink中的state
state概念
在 flink 中,状态是流处理程序中非常重要的一部分,它允许你保存和访问数据,以实现复杂的计算逻辑。
可以简单理解为: 历史计算结果
flink中的算子任务的state分类通常分为两类
1️⃣ 有状态
有状态需要考虑历史的数据,相同的输入可能会得到不同的输出
比如:sum/reduce/maxby, 对单词按照key分组聚合,进来一个(hello,1),得到(hello,1), 再进来一个(hello,1), 得到的结果为(hello,2)
2️⃣ 无状态
无状态简单说就是不需要考虑历史的数据,相同的输入得到相同的结果
比如map、filter、flatmap算子都属于无状态,不需要依赖其他数据
✅ flink默认已经支持了无状态和有状态计算!
状态分类
flink中有两种基本类型的状态:托管状态(managed state)和原生状态(raw state)
managed state是由flink管理的,flink帮忙存储、恢复和优化
raw state是开发者自己管理的,需要自己序列化
❇️通常情况下,我们采用托管状态来实现我们的需求!!!
托管状态
flink 中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的 slot 在计算资源上是物理隔离的,所以flink 能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
很多有状态的操作(比如聚合、窗口)都是要先做 keyby 进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前 key 有效,所以状态也应该按照 key 彼此隔离。在这种情况下,状态的访问方式又会有所不同。
🎨所以:我们又可以将托管状态分为两类:算子状态和按键分区状态。
键控状态keyed state
详细内容可以瞅瞅官网:https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/dev/datastream/fault-tolerance/state/
flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
需要注意的是键控状态只能在 keyedstream 上进行使用,可以通过 stream.keyby(…) 来得到 keyedstream 。

flink 提供了以下数据格式来管理和存储键控状态 (keyed state):
valuestate:存储单值类型的状态。可以使用 update(t) 进行更新,并通过 t value() 进行检索。
liststate:存储列表类型的状态。可以使用 add(t) 或 addall(list) 添加元素;并通过 get() 获得整个列表。
reducingstate:用于存储经过 reducefunction 计算后的结果,使用 add(t) 增加元素。
aggregatingstate:用于存储经过 aggregatingstate 计算后的结果,使用 add(in) 添加元素。
foldingstate:已被标识为废弃,会在未来版本中移除,官方推荐使用 aggregatingstate 代替。
mapstate:维护 map 类型的状态。
code实操
例子1
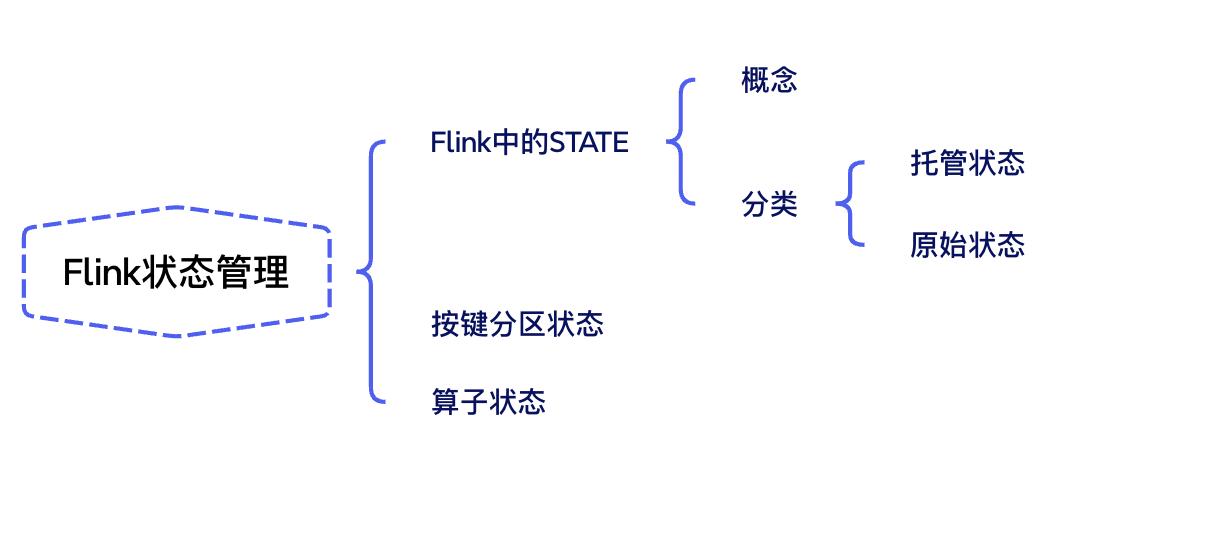
使用keystate中的valuestate来模拟实现maxby
import org.apache.flink.api.common.runtimeexecutionmode;
import org.apache.flink.api.common.functions.richmapfunction;
import org.apache.flink.api.common.state.valuestate;
import org.apache.flink.api.common.state.valuestatedescriptor;
import org.apache.flink.api.java.tuple.tuple2;
import org.apache.flink.api.java.tuple.tuple3;
import org.apache.flink.configuration.configuration;
import org.apache.flink.streaming.api.datastream.datastream;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;
/**
* @author tiancx
*/
public class statemaxbydemo {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.setruntimemode(runtimeexecutionmode.automatic);
//加载数据
datastream<tuple2<string, integer>> source = env.fromelements(
tuple2.of("北京", 1),
tuple2.of("上海", 2),
tuple2.of("广州", 3),
tuple2.of("北京", 4),
tuple2.of("上海", 5),
tuple2.of("广州", 6),
tuple2.of("北京", 3))
.keyby(t -> t.f0);
source.map(new richmapfunction<tuple2<string, integer>, tuple3<string, integer, integer>>() {
//定义状态,用于存储最大值
valuestate<integer> maxvaluestate = null;
//进行初始化
@override
public void open(configuration parameters) throws exception {
//创建状态描述器
valuestatedescriptor<integer> descriptor = new valuestatedescriptor<>("maxvaluestate", integer.class);
maxvaluestate = getruntimecontext().getstate(descriptor);
}
@override
public tuple3<string, integer, integer> map(tuple2<string, integer> value) throws exception {
//获取当前值
integer currentval = value.f1;
integer currentmax = maxvaluestate.value();
if (currentmax == null || currentval > currentmax) {
maxvaluestate.update(currentval);
}
return tuple3.of(value.f0, value.f1, maxvaluestate.value());
}
}).print();
env.execute();
}
}
例子2
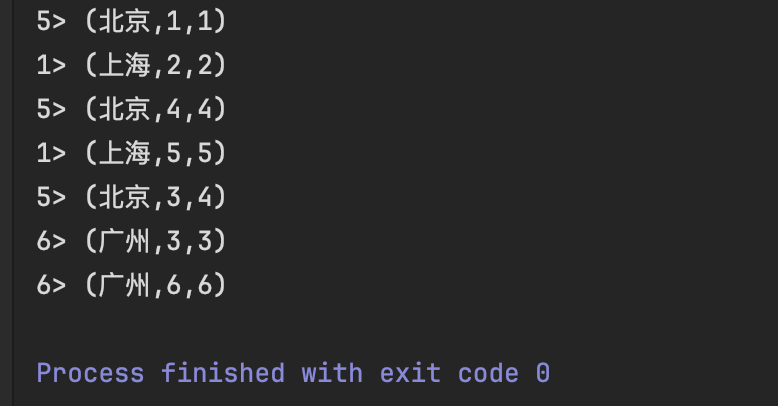
如果一个人的体温超过阈值38度,超过3次及以上,则输出: 姓名 [温度1,温度2,温度3]
import org.apache.flink.api.common.runtimeexecutionmode;
import org.apache.flink.api.common.functions.mapfunction;
import org.apache.flink.api.common.functions.richflatmapfunction;
import org.apache.flink.api.common.state.liststate;
import org.apache.flink.api.common.state.liststatedescriptor;
import org.apache.flink.api.common.state.valuestate;
import org.apache.flink.api.common.state.valuestatedescriptor;
import org.apache.flink.api.java.tuple.tuple2;
import org.apache.flink.configuration.configuration;
import org.apache.flink.streaming.api.datastream.datastream;
import org.apache.flink.streaming.api.datastream.datastreamsource;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;
import org.apache.flink.util.collector;
import java.util.list;
/**
* @author tiancx
*/
public class statedemo01 {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.setruntimemode(runtimeexecutionmode.automatic);
datastreamsource<string> stream = env.sockettextstream("localhost", 9999);
datastream<tuple2<string, integer>> source = stream.map(new mapfunction<string, tuple2<string, integer>>() {
@override
public tuple2<string, integer> map(string value) throws exception {
string[] split = value.split(" ");
return tuple2.of(split[0], integer.parseint(split[1]));
}
})
.keyby(t -> t.f0);
source.flatmap(new richflatmapfunction<tuple2<string, integer>, tuple2<string, list<integer>>>() {
liststate<integer> liststate = null;
//存放超过38度的次数
valuestate<integer> valuestate = null;
@override
public void open(configuration parameters) throws exception {
liststatedescriptor<integer> liststatedescriptor = new liststatedescriptor<integer>("liststate", integer.class);
valuestatedescriptor<integer> descriptor = new valuestatedescriptor<>("valuestate", integer.class);
liststate = getruntimecontext().getliststate(liststatedescriptor);
valuestate = getruntimecontext().getstate(descriptor);
}
@override
public void flatmap(tuple2<string, integer> value, collector<tuple2<string, list<integer>>> out) throws exception {
system.out.println("进入flatmap");
integer val = value.f1;
if (valuestate.value() == null) {
valuestate.update(0);
}
if (val > 38) {
liststate.add(val);
valuestate.update(valuestate.value() + 1);
}
if (valuestate.value() >= 3) {
list<integer> list = (list<integer>) liststate.get();
out.collect(tuple2.of(value.f0, list));
liststate.clear();
valuestate.clear();
}
}
}).print();
env.execute();
}
}

算子状态operatorstate
算子状态(operator state)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的 key 无关,所以不同 key 的数据只要被分发到同一个并行子任务,就会访问到同一个 operator state。
算 子 状 态 也 支 持 不 同 的 结 构 类 型 , 主 要 有 三 种 : liststate 、 unionliststate 和broadcaststate。
code实操
例子1:
在 map 算子中计算数据的个数
import org.apache.flink.api.common.functions.mapfunction;
import org.apache.flink.api.common.state.liststate;
import org.apache.flink.api.common.state.liststatedescriptor;
import org.apache.flink.api.scala.typeutils.types;
import org.apache.flink.runtime.state.functioninitializationcontext;
import org.apache.flink.runtime.state.functionsnapshotcontext;
import org.apache.flink.streaming.api.checkpoint.checkpointedfunction;
import org.apache.flink.streaming.api.datastream.datastreamsource;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;
/**
* @author tiancx
*/
public class operatorliststatedemo {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.setparallelism(2);
datastreamsource<string> stream = env.sockettextstream("localhost", 9999);
stream.map(new mycountmapfunction())
.print();
env.execute();
}
public static class mycountmapfunction implements mapfunction<string, long>, checkpointedfunction {
private long count = 0l;
private liststate<long> liststate;
@override
public long map(string value) throws exception {
return ++count;
}
/**
* 本地变量持久化:将 本地变量拷贝到算子状态中,开启checkpoint 时才会调用 snapshotstate 方法
*
* @param context the context for drawing a snapshot of the operator
* @throws exception
*/
@override
public void snapshotstate(functionsnapshotcontext context) throws exception {
system.out.println("mycountmapfunction.snapshotstate");
liststate.clear();
liststate.add(count);
}
/**
* 初始化本地变量:程序启动和恢复时,从状态中把数据添加到本地变量,每个子任务调用一次
*
* @param context the context for initializing the operator
* @throws exception
*/
@override
public void initializestate(functioninitializationcontext context) throws exception {
system.out.println("mycountmapfunction.initializestate");
//从上下文初始化状态
liststate = context
.getoperatorstatestore()
.getliststate(new liststatedescriptor<>("liststate", types.long()));
//从算子状态中把数据拷贝到本地变量
if (context.isrestored()) {
for (long along : liststate.get()) {
count += along;
}
}
}
}
}
【都看到这了,点点赞点点关注呗,爱你们】😚😚

💬
✨ 正在努力的小叮当~
💖 超级爱分享,分享各种有趣干货!
👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板
🌈 感谢关注,关注了你就是我的超级粉丝啦!
🔒 以下内容仅对你可见~
作者:小叮当撩代码,csdn后端领域新星创作者 |阿里云专家博主
csdn个人主页:
🔎gzh:哆啦a梦撩代码
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
发表评论