版权声明:本文为博主原创文章,遵循 cc 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
flink dataset api编程模型

flink dataset api编程基本步骤
- 获取执行环境(executionenvironment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的dataset)
- 指定将计算的结果输出
- 提交任务(可选)
输入数据集data source
data sources 是什么呢?就字面意思其实就可以知道 数据来源 。
flink 做为一款流式计算框架,它可用来做批处理,也可以用来做流处理,这个 data sources 就是数据的来源地。
flink在批处理中常见的source主要有两大类。
- 基于本地集合的source(collection-based-source)
- 基于文件的source(file-based-source)
基于本地集合的source(collection-based-source)
在flink最常见的创建dataset方式有三种:
- 使用env.fromelements(),这种方式也支持tuple,自定义对象等复合形式。
注意:类型要一致,不一致可以用object接收,但是使用会报错,比如:env.fromelements(“haha”, 1);

源码注释中有写:

- 使用env.fromcollection(),这种方式支持多种collection的具体类型,如list,set,queue
- 使用env.generatesequence()方法创建基于sequence的dataset
代码
package batch.source;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.operators.datasource;
import java.util.*;
import java.util.concurrent.arrayblockingqueue;
/**
* @author lwh
* @date 2023/4/11
* @description
**/
public class testsource {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
// 1. 从元素中获取
datasource<string> source1 = env.fromelements("haha", "heihei");
source1.print();
// 2. 从元素中获取,但是元素类型不同
// datasource<object> source2 = env.fromelements("haha", 1);
// source2.print();
// 3. 从list中获取
list<string> list = new arraylist<>();
list.add("haha");
list.add("heihei");
datasource<string> listsource = env.fromcollection(list);
listsource.print();
// 4. 从set中获取
set<string> set = new hashset<>();
set.add("lalala");
set.add("guaguagua");
datasource<string> setsource = env.fromcollection(set);
setsource.print();
// 5. 从队列中获取
queue<string> queue = new arrayblockingqueue<>(10);
queue.add("spark");
queue.add("hadoop");
datasource<string> queuesource = env.fromcollection(queue);
queuesource.print();
// 6. 生成序列
datasource<long> seqsource = env.generatesequence(1, 10);
seqsource.print();
}
}
在代码中指定并行度
指定全局并行度:
env.setparallelism(12);
获得全局并行度:
env.getparallelism();
指定算子设置并行度:
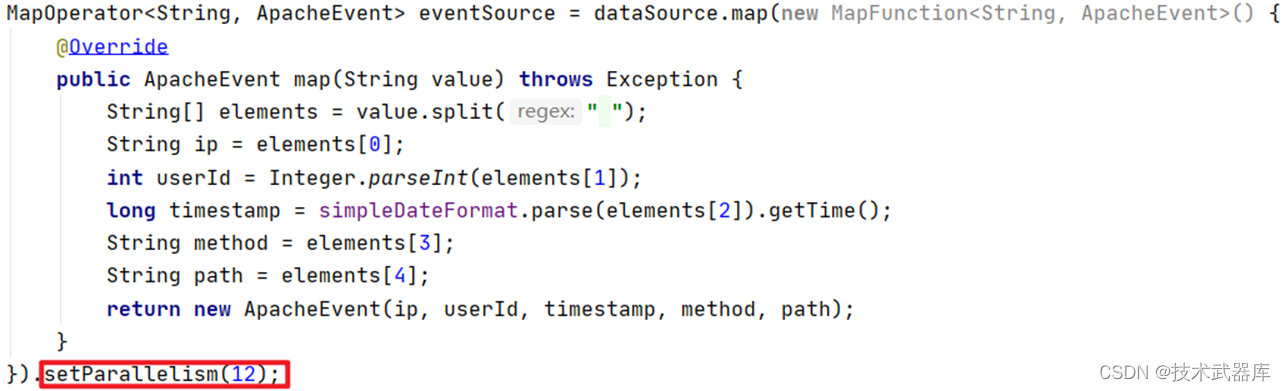
获得指定算子的并行度:
eventsource.getparallelism();
基于文件的source(file-based-source)
flink支持直接从外部文件存储系统中读取文件的方式来创建source数据源,flink支持的方式有以下几种:
- 读取本地文件数据
- 读取hdfs文件数据
- 读取csv文件数据
- 读取压缩文件
- 遍历目录
下面分别演示每个数据源的加载方式。
读取本地文件
flink的批处理可以直接通过readtextfile()方法读取文件来创建数据源,方法如下:
package batch.source;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.operators.datasource;
/**
* @author lwh
* @date 2023/4/11
* @description
**/
public class batchfromfiledemo {
public static void main(string[] args) throws exception {
//1:初始化运行环境
executionenvironment env = executionenvironment.getexecutionenvironment();
//2:读取本地文件数据源
datasource<string> locallines = env.readtextfile("./data/input/wordcount.txt");
//3:打印数据
locallines.print();
}
}
读取hdfs数据
package batch.source;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.operators.datasource;
/**
* @author lwh
* @date 2023/4/11
* @description
**/
public class hdfsfilesource {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
// read hdfs file
datasource<string> hdfssource = env.readtextfile("hdfs://node1:8020/input/license.txt");
hdfssource.print();
}
}
读取csv数据
package entity;
/**
* @author lwh
* @date 2023/4/11
* @description
**/
public class student {
private integer id;
private string name;
private integer sort;
private double score;
public integer getid() {
return id;
}
public void setid(integer id) {
this.id = id;
}
public string getname() {
return name;
}
public void setname(string name) {
this.name = name;
}
public integer getsort() {
return sort;
}
public void setsort(integer sort) {
this.sort = sort;
}
public double getscore() {
return score;
}
public void setscore(double score) {
this.score = score;
}
@override
public string tostring() {
return "student{" +
"id=" + id +
", name='" + name + '\'' +
", sort=" + sort +
", score=" + score +
'}';
}
}
package batch.source;
import entity.student;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.io.csvreader;
import org.apache.flink.api.java.operators.datasource;
/**
* @author lwh
* @date 2023/4/11
* @description
**/
public class csvfilesource {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
/**
* 参数说明:
* fielddelimiter设置分隔符,默认的是","
* ignorefirstline忽略第一行
* includefields是设置选取哪几列,我这里是第四列不选取的。
* pojotype和后面字段名,就是对应列。字段名是不需要对应原始文件header字段名,
* 但必须与pojo例如userinfo.class里的字段名一一对应
*/
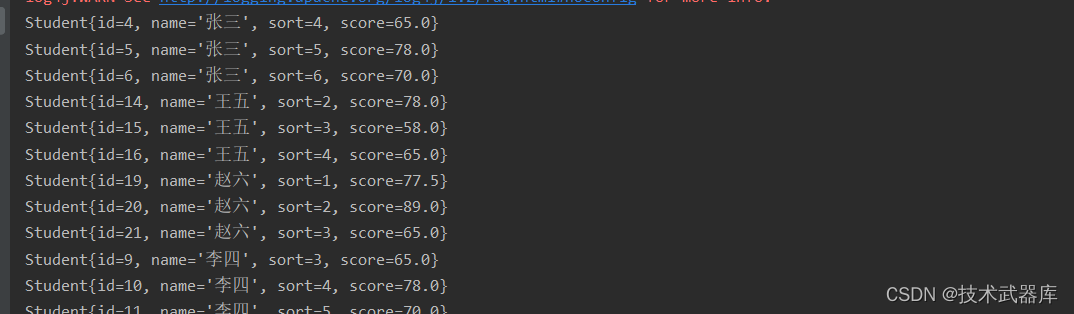
csvreader csvreader = env.readcsvfile("data/input/score.csv");
datasource<student> csvsource = csvreader.fielddelimiter(",")
.ignorefirstline()
.includefields(true, true, true, true)
.pojotype(student.class, "id", "name", "sort", "score");
csvsource.print();
}
}
基于文件的source(遍历目录)
flink支持对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式。
对于从文件中读取数据,当读取的多个文件夹的时候,嵌套的文件默认是不会被读取的,只会读取第一个文件,其他的都会被忽略。所以我们需要使用recursive.file.enumeration进行递归读取
package batch.source;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.operators.datasource;
import org.apache.flink.configuration.configuration;
/**
* @author lwh
* @date 2023/4/11
* @description 递归读取目录内的文件
**/
public class recursivefilereadsource {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
// 生成配置参数
configuration param = new configuration();
param.setboolean("recursive.file.enumeration", true);
// 读取目录配合递归
datasource<string> source = env.readtextfile("./data").withparameters(param);
source.print();
}
}
读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
| 压缩格式 | 扩展名 |
|---|---|
| deflate | deflate |
| gzip | .gz,.gzip |
| bzip2 | .bz2 |
| xz | .xz |
package batch.source;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.operators.datasource;
/**
* @author lwh
* @date 2023/4/11
* @description 读取压缩文件:gz,xz
**/
public class compressfilesource {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
// 读取压缩文件
datasource<string> gzsource = env.readtextfile("data/input/test.gz");
gzsource.print();
}
}
注意:读取压缩文件,不能并行处理,因此加载解压的时间会稍微有点长。
发表评论