1. 原因
写入iceberg表时,会在hive_locks表中插入一条记录,表示该表正在被写入(hive中的独占锁)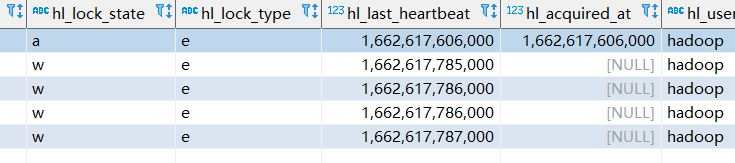
当数据插入完成后,会自动删除该条记录。
2. 出现场景
(1)在同时往同一个iceberg表中写入数据时,会出现retrying task after failure: waiting for lock之类的警告信息
如果有一个表正在写入中,并且在hive_locks中插入了一条记录。并且有另一个任务也在写入该表,就会出现这个警告信息,等待前面的任务执行完成后,这个任务就会自动执行下去,此时不需要进行任何其他的操作。
但是如果前面一个任务写入表的时候,突然中断了,导致在hive_locks表中这条记录没有删除,那么就会一直出现这个错误,此时的解决方法是手工删除hive_locks表中该表对应的锁记录。
(2)在删除表后,重新创建表时,也会出错,提示错误信息是该表存在。
在重新创建新表时,会去hive_locks这个表中校验是否存在正在写入的锁记录,如果存在,就会提示该表已存在的错误信息,此时也是相同的解决方案,手工删除hive_locks表中该表对应的锁记录。
3. hive中的锁
3.1 锁的介绍
hive中存在两种锁,共享锁shared(s)和互斥锁exclusive(x)
共享锁 s 和 排他锁 x 它们之间的兼容性关系如下:
1)查询操作使用共享锁,共享锁是可以多重、并发使用的
2)修改表操作使用独占锁,它会阻止其他的查询、修改操作
3)可以对分区使用锁。
触发共享锁的操作是可以并发执行的,但是触发互斥锁,那么该表和该分区就不能并发的执行作业了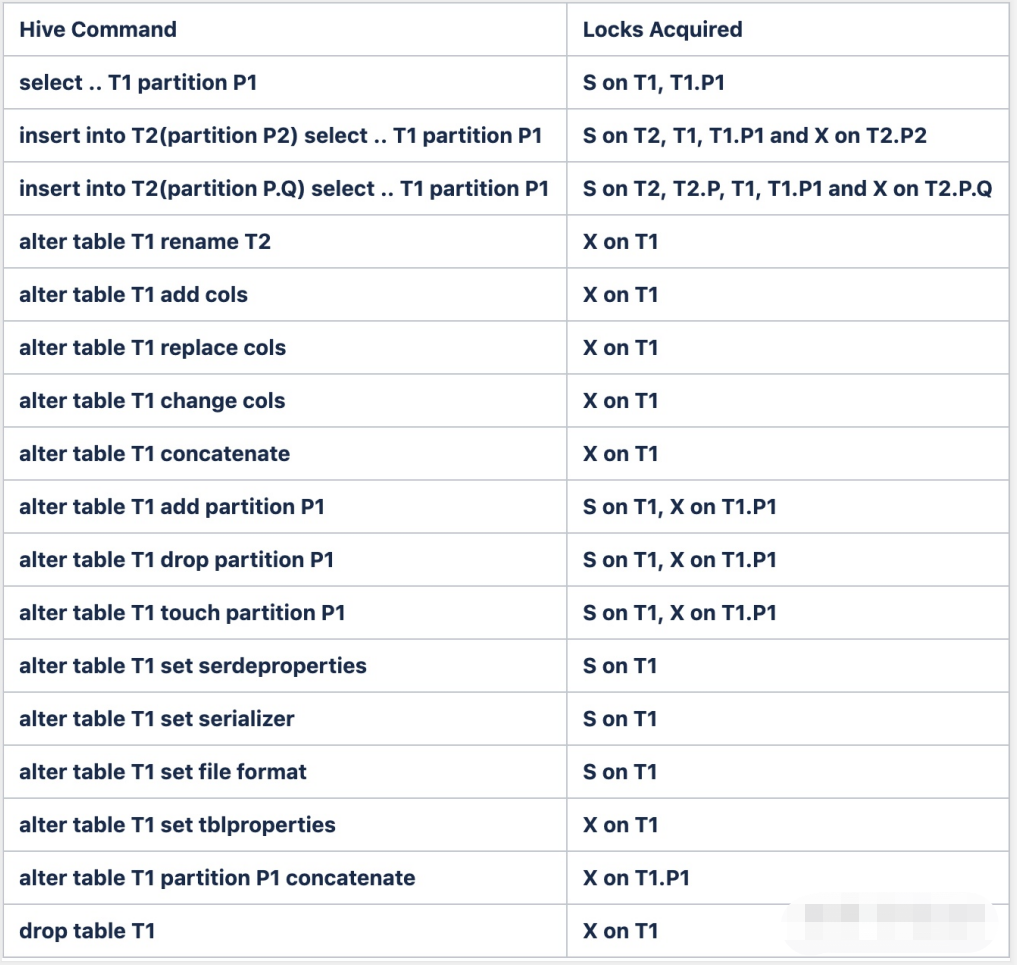
3.2 锁的常用操作
show locks tablename --查看锁
unlock table 表名; -- 解锁表
unlock table 表名 partition(dt='2014-04-01'); -- 解锁某个分区
--如果这个命令无法执行,lockmanager没有指定,这时候需要执行命令:
set hive.support.concurrency=true;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.dummytxnmanager;
--如果还不行,那么就直接去mysql的元数据表hive_locks中去执行:
delete from hive_locks where hl_db = 'xxx.db' and hl_table = 'xxx_table';3.3 锁配置
全局配置,修改hive-site.xml,配置如下
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>-- 单独锁表
lock table t1 exclusive;
--解除锁
unlock table t1;
--关闭锁
set hive.support.concurrency=false;配置条件
hive.lock.numretries #重试次数
hive.lock.sleep.between.retries #重试时sleep的时间hive默认的sleep时间是60s,比较长,在高并发场景下,可以减少这个的数值来提供job的效率。
如何查看是否配置了锁?
我们在hive的webui中可以查看配置,http://hadoop:10002/conf
直接搜索 hive.support.concurrency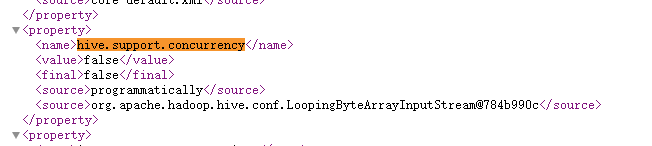
3.4 hive(cdh4.2.0)的锁处理流程
应该是修改了源码。。。
1.首先对query进行编译,生成queryplan
2.构建读写锁对象(主要两个成员变量:lockobject,lockmode)
对于非分区表,直接根据需要构建s或者x锁对象
对于分区表:(此处是区分input/output)
if s mode:
直接对table/related partition 构建s对象
else:
if 添加新分区:
构建s对象
else
构建x对象
end
3.对锁对象进行字符表排序(避免死锁),对于同一个lockobject,先获取execlusive
4.遍历锁对象列表,进行锁申请
while trynumber< hive.lock.numretries(default100):
创建parent(node)目录,mode= createmode.persistent
创建锁目录,mode=createmode.ephemeral_sequential
for child:children
if child已经有写锁:
获取child写锁seqno
if mode=x 并且 child 已经有读锁
获取child读锁seqno
if childseqno>0并且小于当前seqno
释放锁
trynumber++
sleep(hive.lock.sleep.between.retries:default1min)以上对hive中的锁有个大概的了解。
4. iceberg中的锁原理
摘录自网络的中的一段话:
从这里可以了解到iceberg为了保证事务的acid属性,解决并发的读写问题,使用到了数据库的锁,我们目前创建iceberg使用到的是hive_catalog,所以自然也就使用了hive中的数据库锁。
但是即使我们在hive中不配置锁,iceberg也是直接使用了hive的数据库中hive_locks表。
相关内容引用参考:https://maimai.cn/article/detail?fid=1726689402&efid=cwv6bwn0rlckectf98v2mqhttps://developer.aliyun.com/article/903837

发表评论