在《java版flink使用指南——从rabbitmq中队列中接入消息流》一文中,我们让外部组件rabbitmq充当了无界流的数据源,使得flink进行了流式处理。在《java版flink使用指南——将消息写入到rabbitmq的队列中》一文中,我们使用了flink自带的数据生成器,生成了有限数据,从而让flink以批处理形式运行了该任务。
本文我们将自定义一个无界流生成器,以方便后续测试。
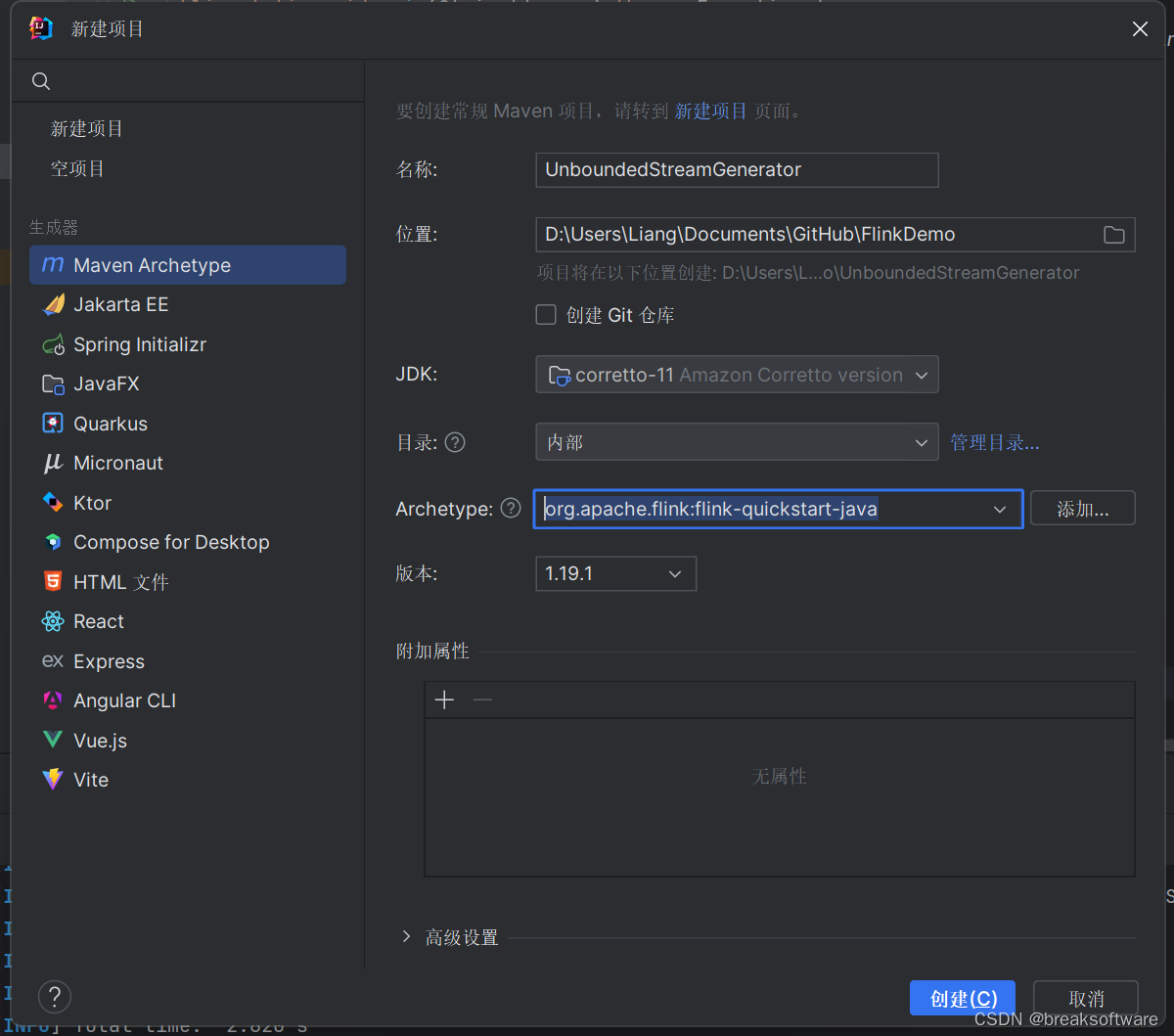
新建工程
我们新建一个名字叫unboundedstreamgenerator的工程。
archetype:org.apache.flink:flink-quickstart-java
版本:1.19.1
自定义无界流
新建src/main/java/org/example/generator/unboundedstreamgenerator.java
然后unboundedstreamgenerator实现richsourcefunction接口
public abstract class richsourcefunction<out> extends abstractrichfunction
implements sourcefunction<out> {
private static final long serialversionuid = 1l;
}
主要实现sourcefunction接口的run和cancel方法。run方法用来获取获取,cancel方法用于终止任务。
package org.example.generator;
import org.apache.flink.streaming.api.functions.source.richsourcefunction;
public class unboundedstreamgenerator extends richsourcefunction<long> {
private volatile boolean isrunning = true;
@override
public void run(sourcecontext<long> ctx) throws exception {
long count = 0l;
while (isrunning) {
thread.sleep(1000); // simulate delay
ctx.collect(count++); // emit data
}
}
@override
public void cancel() {
isrunning = false;
system.out.println("unboundedstreamgenerator canceled");
}
}
在run方法中,我们每隔一秒产生一条数据,且这个数字自增。
使用
我们使用addsource方法,将该无界流生成器添加成数据源。然后将其输出到日志。
/*
* licensed to the apache software foundation (asf) under one
* or more contributor license agreements. see the notice file
* distributed with this work for additional information
* regarding copyright ownership. the asf licenses this file
* to you under the apache license, version 2.0 (the
* "license"); you may not use this file except in compliance
* with the license. you may obtain a copy of the license at
*
* http://www.apache.org/licenses/license-2.0
*
* unless required by applicable law or agreed to in writing, software
* distributed under the license is distributed on an "as is" basis,
* without warranties or conditions of any kind, either express or implied.
* see the license for the specific language governing permissions and
* limitations under the license.
*/
package org.example;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;
import org.example.generator.unboundedstreamgenerator;
/**
* skeleton for a flink datastream job.
*
* <p>for a tutorial how to write a flink application, check the
* tutorials and examples on the <a href="https://flink.apache.org">flink website</a>.
*
* <p>to package your application into a jar file for execution, run
* 'mvn clean package' on the command line.
*
* <p>if you change the name of the main class (with the public static void main(string[] args))
* method, change the respective entry in the pom.xml file (simply search for 'mainclass').
*/
public class datastreamjob {
public static void main(string[] args) throws exception {
// sets up the execution environment, which is the main entry point
// to building flink applications.
final streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.addsource(new unboundedstreamgenerator()).name("custom stream source")
.setparallelism(1)
.print(); // for demonstration, print the stream to stdout
// execute program, beginning computation.
env.execute("flink java api skeleton");
}
}
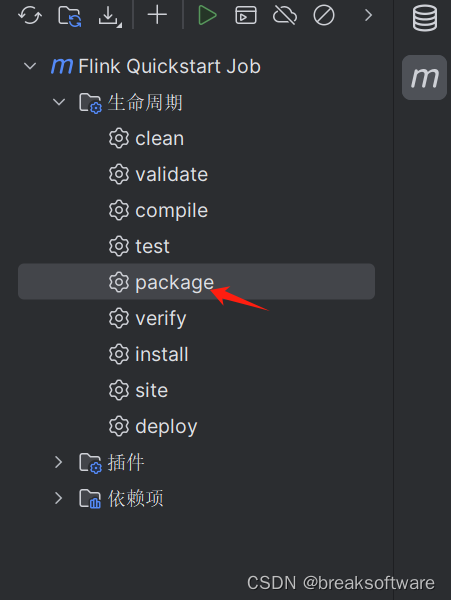
打包、提交、运行
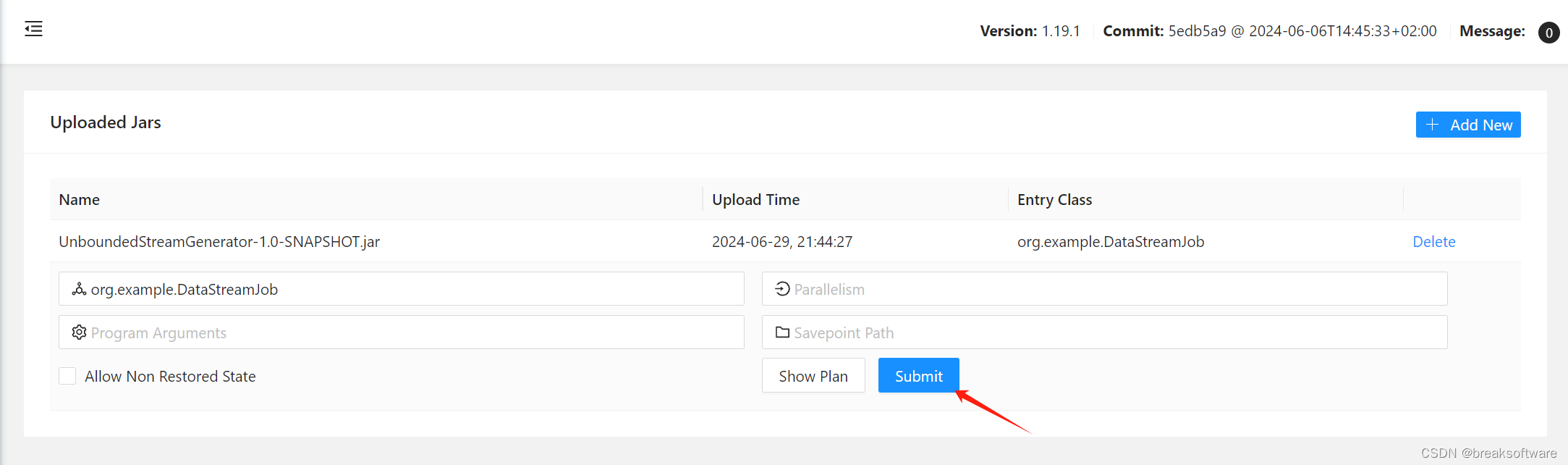
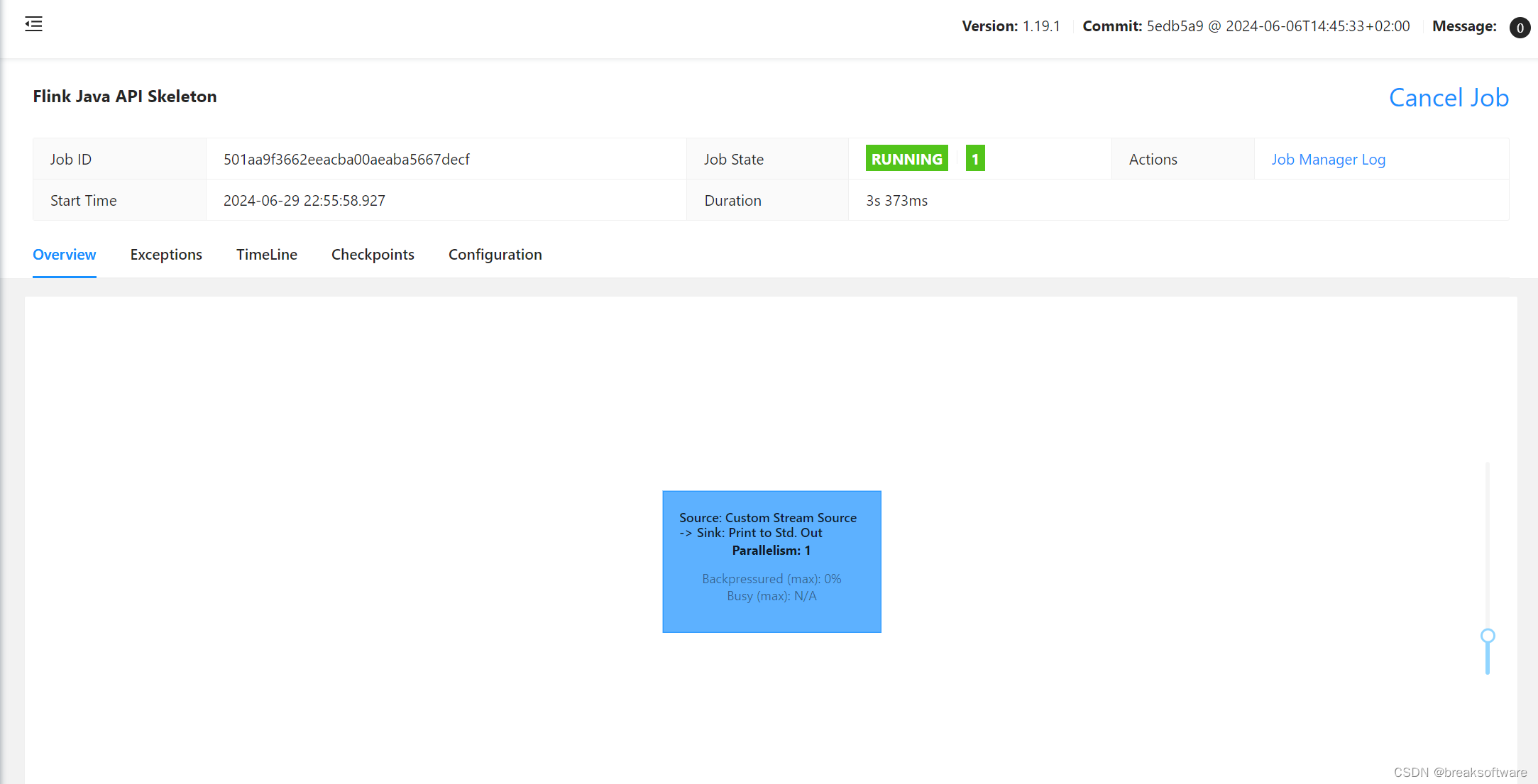
使用下面命令查看日志输出
tail -f log/*
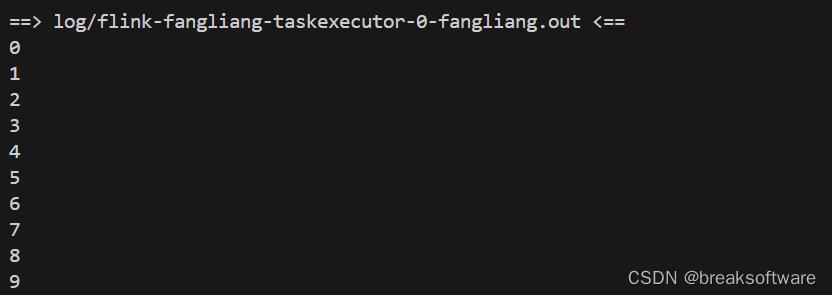
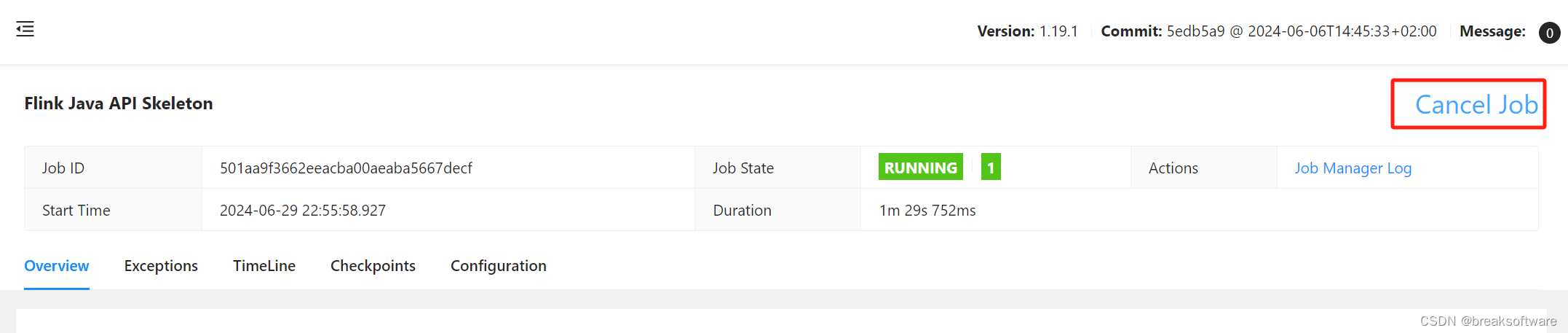
然后我们在后台点击cancel job
可以看到输出



发表评论