ollama介绍

在本地启动并运行大型语言模型。运行llama 3、phi 3、mistral、gemma和其他型号。
llama 3
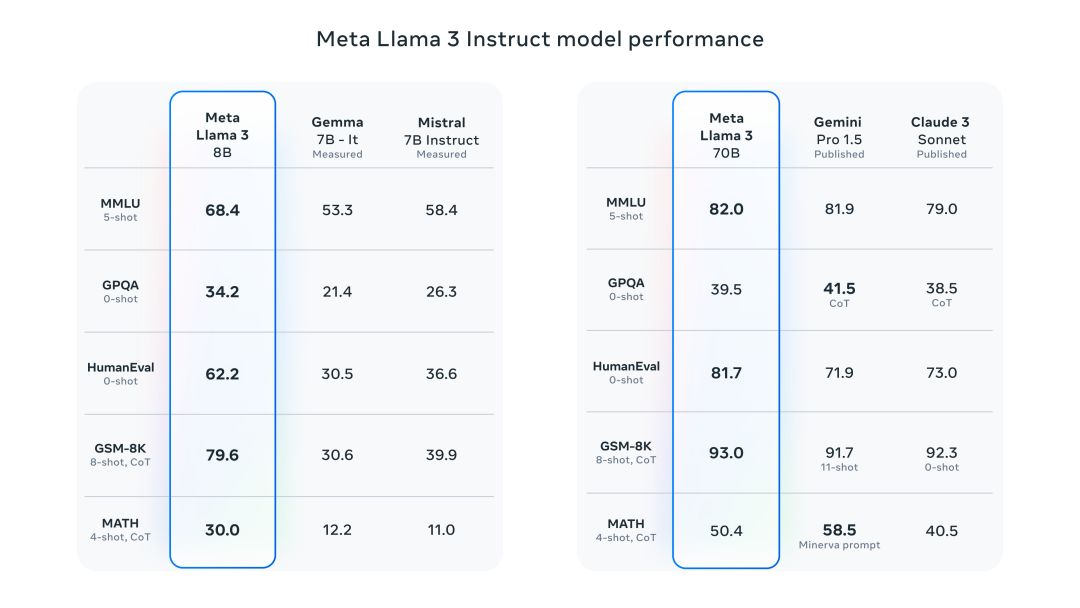
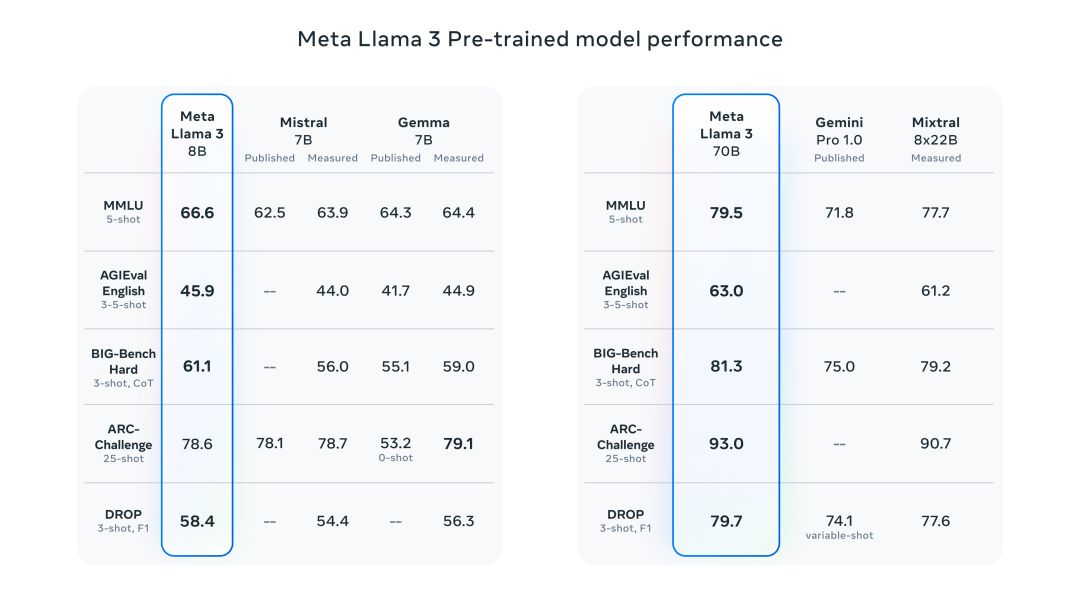
meta llama 3 是 meta inc. 开发的一系列最先进的模型,提供8b和70b参数大小(预训练或指令调整)。

llama 3 指令调整模型针对对话/聊天用例进行了微调和优化,并且在常见基准测试中优于许多可用的开源聊天模型。
安装
pip install ollama
高性价比gpu资源:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_tongyong_shemei
用法
import ollamaresponse = ollama.chat(model='llama2', messages=[ { 'role': 'user', 'content': 'why is the sky blue?', },])print(response['message']['content'])
流式响应
可以通过设置stream=true、修改函数调用以返回 python 生成器来启用响应流,其中每个部分都是流中的一个对象。
import ollama stream = ollama.chat( model='llama2', messages=[{'role': 'user', 'content': 'why is the sky blue?'}], stream=true, ) for chunk in stream: print(chunk['message']['content'], end='', flush=true)
应用程序编程接口
ollama python 库的 api 是围绕ollama rest api设计的
聊天
ollama.chat(model='llama2', messages=[{'role': 'user', 'content': 'why is the sky blue?'}])
新增
ollama.generate(model='llama2', prompt='why is the sky blue?')
列表
ollama.list()
展示
ollama.show('llama2')
创建
modelfile=''' from llama2 system you are mario from super mario bros. ''' ollama.create(model='example', modelfile=modelfile)
复制
ollama.copy('llama2', 'user/llama2')
删除
ollama.delete('llama2') pull ollama.pull('llama2') push ollama.push('user/llama2')
嵌入
ollama.embeddings(model='llama2', prompt='the sky is blue because of rayleigh scattering')
定制客户端
可以使用以下字段创建自定义客户端:
- host:要连接的 ollama 主机
- timeout: 请求超时时间
from ollama import client client = client(host='http://localhost:11434') response = client.chat(model='llama2', messages=[ { 'role': 'user', 'content': 'why is the sky blue?', }, ])
异步客户端
import asyncio from ollama import asyncclient async def chat(): message = {'role': 'user', 'content': 'why is the sky blue?'} response = await asyncclient().chat(model='llama2', messages=[message]) asyncio.run(chat())
设置stream=true修改函数以返回 python 异步生成器:
import asyncio from ollama import asyncclient async def chat(): message = {'role': 'user', 'content': 'why is the sky blue?'} async for part in await asyncclient().chat(model='llama2', messages=[message], stream=true): print(part['message']['content'], end='', flush=true) asyncio.run(chat())
错误
如果请求返回错误状态或在流式传输时检测到错误,则会引发错误。
model = 'does-not-yet-exist'try: ollama.chat(model)except ollama.responseerror as e: print('error:', e.error)if e.status_code == 404: ollama.pull(model)


发表评论