在图像处理和计算机视觉领域,颜色模型是理解和分析图像色彩的基础。opencv作为一个广泛使用的计算机视觉库,支持多种颜色空间,其中hsv(hue, saturation, value)颜色模型因其直观性和易用性,在图像处理和颜色分析中被广泛应用。
文章目录
一、hsv颜色模型概述
hsv颜色模型是一种基于人眼感知颜色的方式而设计的颜色空间,由a. r. smith在1978年提出。它通过将颜色分解为色调(hue)、饱和度(saturation)和明度(value)三个分量,以直观的方式表示颜色。hsv颜色模型可以用一个圆锥体或圆柱体来描述,其中色调h用极坐标的极角表示,饱和度s用极坐标的极轴长度表示,明度v用圆柱体的高度表示。
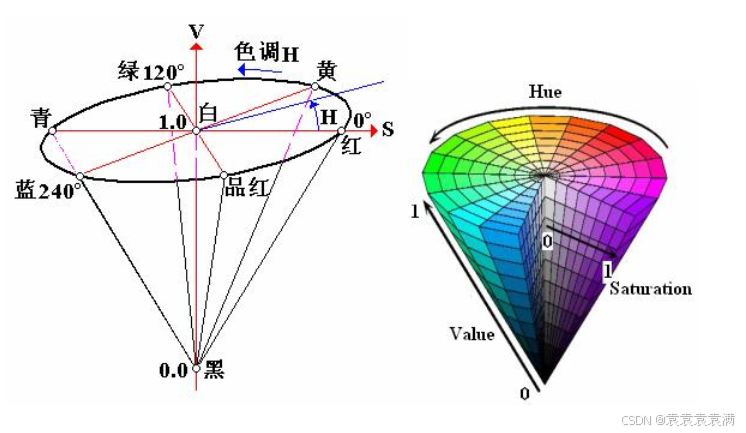
1.1 色调(hue)
色调h表示颜色的类别,用角度度量,取值范围为0°~360°。在hsv模型中,色调从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。
1.2 饱和度(saturation)
饱和度s表示颜色接近光谱色的程度,取值范围为0%~100%。饱和度越高,颜色越深且越鲜艳;饱和度越低,颜色越浅且越接近白色。在hsv模型中,饱和度为0%表示纯白色,此时颜色不包含任何光谱色成分。
1.3 明度(value)
明度v表示颜色的明亮程度,取值范围也是0%~100%。明度越高,颜色越明亮;明度越低,颜色越暗。当明度为0%时,颜色最暗,表现为黑色。在hsv模型中,明度v与颜色的亮度直接相关,但与颜色的种类和饱和度无关。
二、opencv中的hsv颜色分量范围
2.1 分量范围
在opencv中,hsv颜色模型的具体分量范围如下:
- 色调h:0~180(注意,这与标准hsv模型中的0~360°不同,opencv将色调的取值范围进行了归一化处理,以便在内部处理时更加高效)
- 饱和度s:0~255(与标准hsv模型中的0%~100%不同,opencv使用0~255来表示)
- 明度v:0~255(同样,与标准hsv模型中的0%~100%不同,opencv使用0~255来表示)
这种表示方式使得在opencv中处理hsv颜色时更加直观和方便,因为所有的颜色分量都可以使用相同的整数范围来表示。
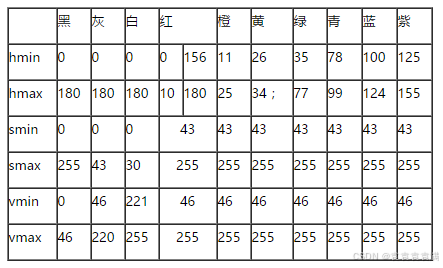
2.2 基本色分量范围表
基本色分量范围表如下(注意:下表来自网络实验,可能会有少许误差):
三、hsv颜色模型的应用
hsv颜色模型在opencv中常用于图像的颜色分割、颜色过滤和颜色识别等任务。例如,在提取图像中特定颜色的物体时,可以首先将图像从bgr颜色空间转换到hsv颜色空间,然后根据目标颜色的色调、饱和度和明度范围创建一个掩码(mask),最后通过掩码来提取目标物体。
3.1 示例代码
以下是一个使用opencv将bgr图像转换为hsv图像,并提取特定颜色(如绿色)的示例代码:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
# 将bgr图像转换为hsv图像
hsv_img = cv2.cvtcolor(img, cv2.color_bgr2hsv)
# 定义绿色的色调、饱和度和明度范围
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
# 根据颜色范围创建掩码
mask = cv2.inrange(hsv_img, lower_green, upper_green)
# 使用掩码提取绿色部分
result = cv2.bitwise_and(img, img, mask=mask)
# 显示结果
cv2.imshow('original image', img)
cv2.imshow('mask', mask)
cv2.imshow('result', result)
cv2.waitkey(0)
cv2.destroyallwindows()
在上述代码中,我们首先读取一张图像,并将其从bgr颜色空间转换为hsv颜色空间。然后,我们定义了绿色的色调、饱和度和明度范围,并据此创建了一个掩码。最后,我们使用掩码从原图中提取出绿色的部分,并显示结果。
四、结论
hsv颜色模型以其直观性和易用性,在opencv的图像处理和颜色分析中发挥着重要作用。通过了解hsv颜色模型及其颜色分量范围,我们可以更加灵活和高效地处理图像中的颜色信息。
书籍推荐
python和pyspark数据分析(数据科学与大数据技术)

spark数据处理引擎是一个惊人的分析工厂:输入原始数据,输出洞察。pyspark用基于python的api封装了spark的核心引擎。它有助于简化spark陡峭的学习曲线,并使这个强大的工具可供任何在python数据生态系统中工作的人使用。
《python和pyspark数据分析》帮助你使用pyspark解决数据科学的日常挑战。你将学习如何跨多台机器扩展处理能力,同时从任何来源(无论是hadoop集群、云数据存储还是本地数据文件)获取数据。一旦掌握了基础知识,就可以通过构建机器学习管道,并配合python、pandas和pyspark代码,探索pyspark的全面多功能特性。
主要内容:
● 组织pyspark代码
● 管理任何规模的数据
● 充满信心地扩展你的数据项目
● 解决常见的数据管道问题
● 创建可靠的长时间运行的任务
发表评论