1、hdfs概述
1.1 hdfs产出背景及定义
1、hdfs产生背景
随着数据量越来越大,在一个操作系统存不住所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。hdfs只是分布式文件管理系统中的一种。
2、hdfs定义
hdfs(hadoop distributed file system),是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
hdfs的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.2 hdfs 优缺点
1、hdfs优点
(1)高容错
数据自动保存多个副本。它通过增加副本的形式提高容错性。
某一个副本丢失以后,它可以自动恢复。
(2)适合处理大数据
数据规模:能够处理数据规模达到gb、tb、甚至pb级别的数据;
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
(3)可构建在廉价机器上,通过多副本机制,提高可靠性。
2、hdfs缺点
(1)不适合低延时数据范围,比如毫秒级的存储数据,是做不到的。
(2)无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用namenode大量的内存来存储文件目录和块信息。这样是不可取的,因为namenode的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了hdfs的设计目标。
(3)不支持并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写。
仅支持数据append(追加),不支持文件的随机修改。
1.3 hdfs组成架构
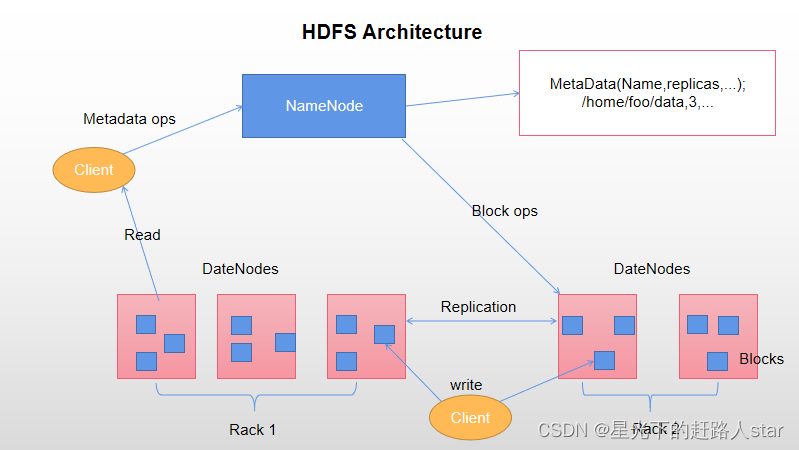
1、namenode(nn):就是master,它是一个主管、管理者。
(1)管理hdfs的名称空间
(2)配置副本策略
(3)管理数据块(block)映射信息
(4)处理客户端读写请求。
2、datenode:就是workes(slave)。namenode下达命令,datanode执行实际的操作。
(1)存储实际的数据块
(2)执行数据块的读/写操作
3、client:客户端
(1)文件切分。文件上传hdfs的时候,client将文件切分成一个一个的block,然后进行上传;
(2)与namenode交互,获取文件的位置信息;
(3)与datanode交互,读取或者写入数据。
(4)client提供一些命令来管理hdfs,比如namenode格式化
(5)client可以通过一些命令来访问hdfs,比如对hdfs增删改查操作。
4、secondary namenode:并非namenode的热备。当namenode挂掉的时候,它并不是能马上替换namenode并提供服务。
(1)辅助namenode,分担其工作量,比如定期合并fsimage和edits,并推送给namenode。
(2)在紧急情况下,可辅助恢复namenode。
1.4 hdfs文件块大小
hdfs中的文件在物理上是分块存储(block),块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在hadoop2.x和3.x版本中是128m,1.x是64m。
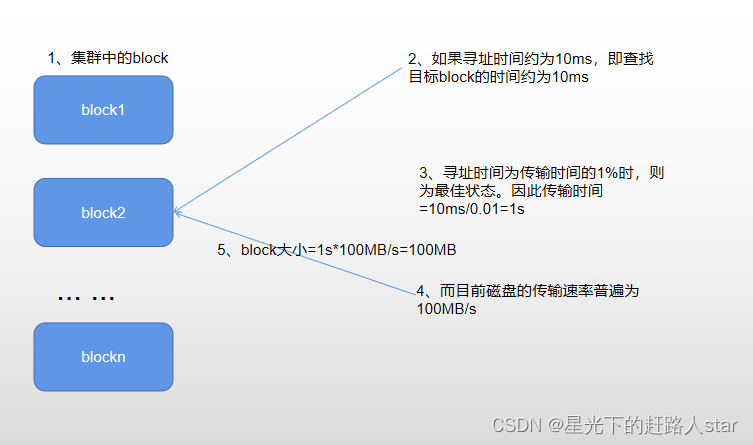
为什么块的大小不能设置太小也不能太大?
(1)hdfs的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输速率的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:hdfs块的大小设置主要取决于磁盘传输速率。
2、hdfs的shell操作
2.1 基本语法
hadoop fs 具体命令 or hdfs dfs 具体命令
两个是完全相同的。
2.2 命令大全
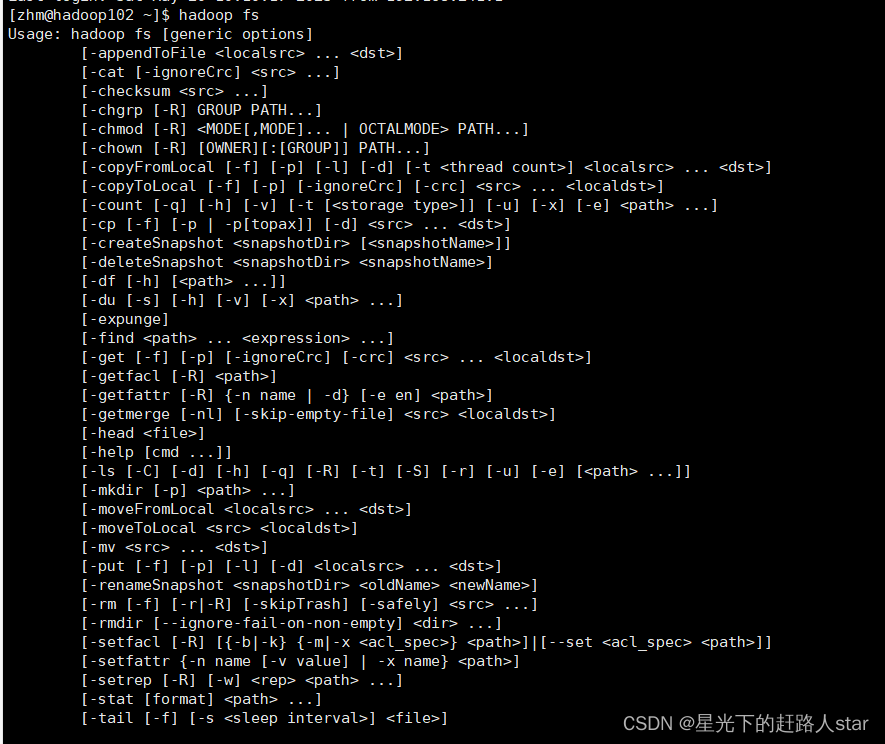
2.3 常用命令实操
2.3.1 准备工作
(1)启动hadoop集群
[zhm@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[zhm@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(2)- help:输出这个命令参数
hadoop fs -help rm
(3)创建/zhm文件夹
hadoop fs -mkdir /zhm
2.3.2 上传
1、-movefromlocal:从本地剪切粘贴到hdfs
hadoop fs -movefromlocal 文件路径 目的路径
2、-copyfromlocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyfromlocal 文件路径 目的路径
3、-put:等同于copyfromlocal,生产环境更习惯用put
hadoop fs -put 文件路径 目的路径
4、-appendtofile:追加一个文件到已经存在的文件末尾
hadoop fs -appendtofile 文件路径 目的路径
2.3.3 下载
1、-copytolocal:从 hdfs 拷贝到本地
hadoop fs -copytolocal 文件路径 目的路径
2、-get:等同于 copytolocal,生产环境更习惯用 get
hadoop fs -get 文件路径 目的路径
2.4 hdfs直接操作
1、-ls:显示目录信息
hadoop fs -ls 目录
2、-cat:显示文件内容
hadoop fs -cat 文件路径
3、-chgrp、-chmod、-chown:linux 文件系统中的用法一样,修改文件所属权限
4、-mkdir:创建路径
hadoop fs -mkdir 目录路径
5、-cp:从 hdfs 的一个路径拷贝到 hdfs 的另一个路径
hadoop fs -cp 文件路径 目的目录
6、-mv:在 hdfs 目录中移动文件
hadoop fs -mv 文件路径 目的路径
7、-tail:显示一个文件的末尾 1kb 的数据
hadoop fs -tail 文件路径
8、-rm:删除文件或文件夹
hadoop fs -rm 文件路径
9、-rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r 文件路径
10、-du 统计文件夹的大小信息
hadoop fs -du 文件路径
11、-setrep:设置 hdfs 中文件的副本数量
hadoop fs -setrep 数量 文件路径
这里设置的副本数只是记录在namenode的元数据中,是否真的有会有这么多的副本,还得看datanode的数量、因为目前只有三台datanode,最多也就是3个副本,只有节点数增加到相应的数量时,副本数才会达到相应的数量。
3、hdfs的api操作
3.1 客户端环境准备
1、找到资料包路径下的windows依赖文件夹,拷贝hadoo-3.1.0到非中文路径(比如 d:\)。
链接:https://pan.baidu.com/s/1wamz5h6p0kynxd_j6vwi8w
提取码:zhm6
–来自百度网盘超级会员v1的分享
2、配置hadoop_home环境变量
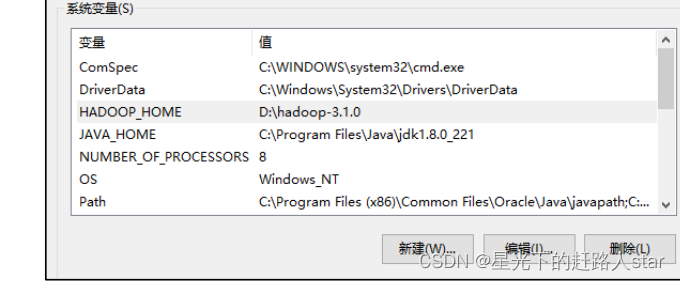
3、配置path环境变量
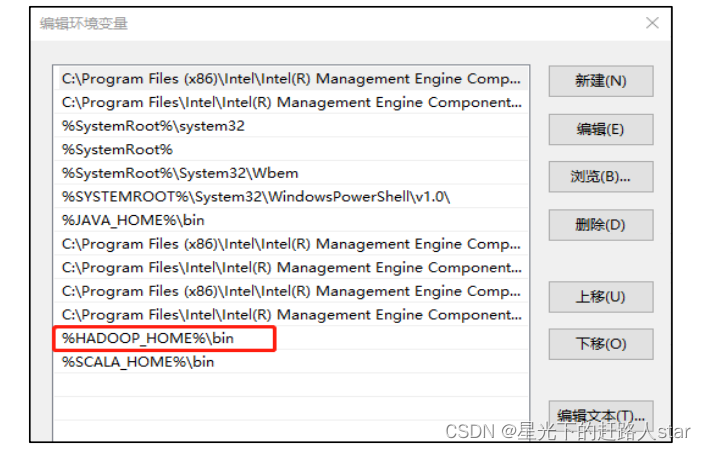
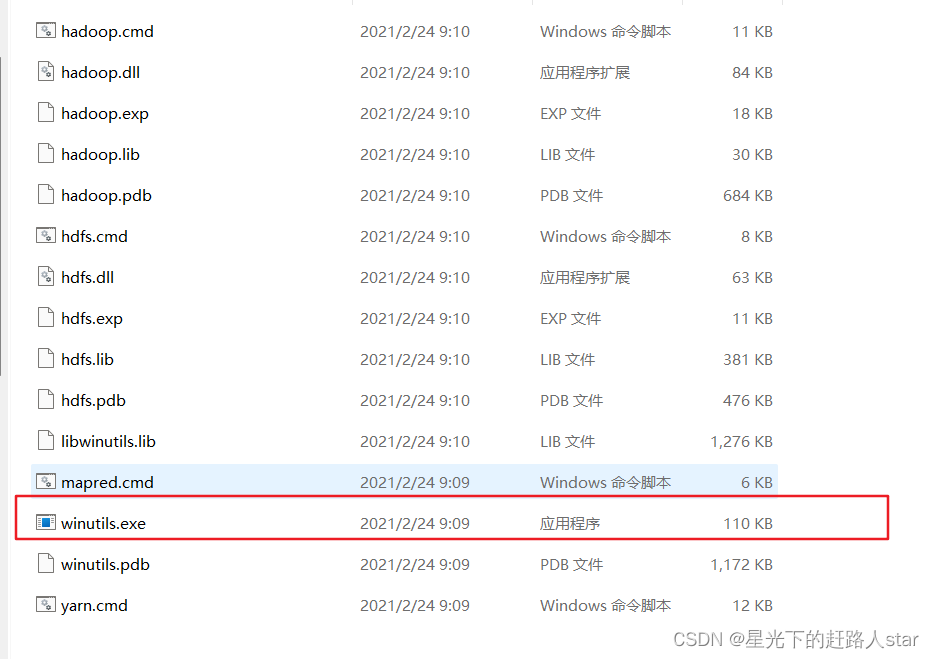
验证hadoop环境变量是否正常,双击winutils.exe。
4、在idea中创建一个maven工程,并导入相应的依赖坐标+日志添加
<dependencies>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-client</artifactid>
<version>3.1.3</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.12</version>
</dependency>
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-log4j12</artifactid>
<version>1.7.30</version>
</dependency>
</dependencies>
在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootlogger=info, stdout
log4j.appender.stdout=org.apache.log4j.consoleappender
log4j.appender.stdout.layout=org.apache.log4j.patternlayout
log4j.appender.stdout.layout.conversionpattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.fileappender
log4j.appender.logfile.file=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.patternlayout
log4j.appender.logfile.layout.conversionpattern=%d %p [%c] - %m%n
5、创建包名:com.zhm.hdfs
6、在hdfs包下创建hdfsclient类
public class hdfsclient {
@test
public void testmkdirs() throws ioexception, urisyntaxexception,
interruptedexception {
// 1 获取文件系统
configuration configuration = new configuration();
// filesystem fs = filesystem.get(new
uri("hdfs://hadoop102:8020"), configuration);
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration,"zhm");
// 2 创建目录
fs.mkdirs(new path("/xiyou/huaguoshan/"));
// 3 关闭资源
fs.close();
}
}
7、执行程序
3.2 hdfs的api案例实操
3.2.1 hdfs文件上传(测试参数优先级)
1、编写源码
@test
public void testcopyfromlocalfile() throws ioexception,
interruptedexception, urisyntaxexception {
// 1 获取文件系统
configuration configuration = new configuration();
configuration.set("dfs.replication", "2");
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 上传文件
fs.copyfromlocalfile(new path("d:/sunwukong.txt"), new
path("/xiyou/huaguoshan"));
// 3 关闭资源
fs.close();
}
2、将hdfs-site.xml拷贝到项目的resource资源目录下
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3、参数优先级
参数优先级排序:(1)客户端代码中设置的值>(2)classpath下的用户自定义配置文件>(3)然后就是服务器的自定义配置(xxx-site.xml)>(4)服务器的默认配置(xxx-default.xml)
3.2.2 hdfs文件下载
@test
public void testcopytolocalfile() throws ioexception,
interruptedexception, urisyntaxexception{
// 1 获取文件系统
configuration configuration = new configuration();
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 执行下载操作
// boolean delsrc 指是否将原文件删除
// path src 指要下载的文件路径
// path dst 指将文件下载到的路径
// boolean userawlocalfilesystem 是否开启文件校验
fs.copytolocalfile(false, new
path("/xiyou/huaguoshan/sunwukong.txt"), new path("d:/sunwukong2.txt"),
true);
// 3 关闭资源
fs.close();
}
3.2.3 hdfs文件更名和移动
@test
public void testrename() throws ioexception, interruptedexception,
urisyntaxexception{
// 1 获取文件系统
configuration configuration = new configuration();
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 修改文件名称
fs.rename(new path("/xiyou/huaguoshan/sunwukong.txt"), new
path("/xiyou/huaguoshan/meihouwang.txt"));
// 3 关闭资源
fs.close();
}
3.2.4 hdfs删除文件和目录
@test
public void testdelete() throws ioexception, interruptedexception,
urisyntaxexception{
// 1 获取文件系统
configuration configuration = new configuration();
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 执行删除
fs.delete(new path("/xiyou"), true);
// 3 关闭资源
fs.close();
}
3.2.5 hdfs文件详情查看
查看文件名称、权限、长度、块信息
@test
public void testlistfiles() throws ioexception, interruptedexception,
urisyntaxexception {
// 1 获取文件系统
configuration configuration = new configuration();
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 获取文件详情
remoteiterator<locatedfilestatus> listfiles = fs.listfiles(new path("/"),
true);
while (listfiles.hasnext()) {
locatedfilestatus filestatus = listfiles.next();
system.out.println("========" + filestatus.getpath() + "=========");
system.out.println(filestatus.getpermission());
system.out.println(filestatus.getowner());
system.out.println(filestatus.getgroup());
system.out.println(filestatus.getlen());
system.out.println(filestatus.getmodificationtime());
system.out.println(filestatus.getreplication());
system.out.println(filestatus.getblocksize());
system.out.println(filestatus.getpath().getname());
// 获取块信息
blocklocation[] blocklocations = filestatus.getblocklocations();
system.out.println(arrays.tostring(blocklocations));
}
// 3 关闭资源
fs.close();
}
3.2.5 hdfs文件详情查看
@test
public void testliststatus() throws ioexception, interruptedexception,
urisyntaxexception{
// 1 获取文件配置信息
configuration configuration = new configuration();
filesystem fs = filesystem.get(new uri("hdfs://hadoop102:8020"),
configuration, "zhm");
// 2 判断是文件还是文件夹
filestatus[] liststatus = fs.liststatus(new path("/"));
for (filestatus filestatus : liststatus) {
// 如果是文件
if (filestatus.isfile()) {
system.out.println("f:"+filestatus.getpath().getname());
}else {
system.out.println("d:"+filestatus.getpath().getname());
}
}
// 3 关闭资源
fs.close();
}
发表评论