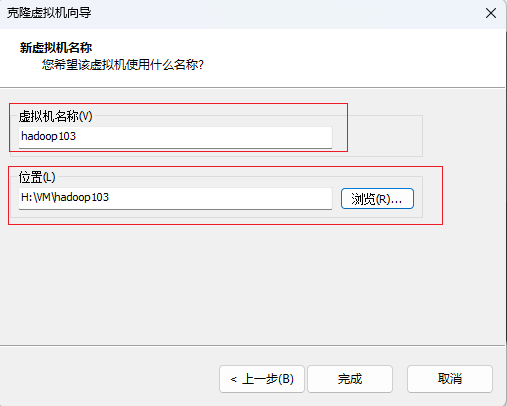
点击完成,克隆成功
再按照以上步骤克隆一台虚拟机,名称为hadoop104
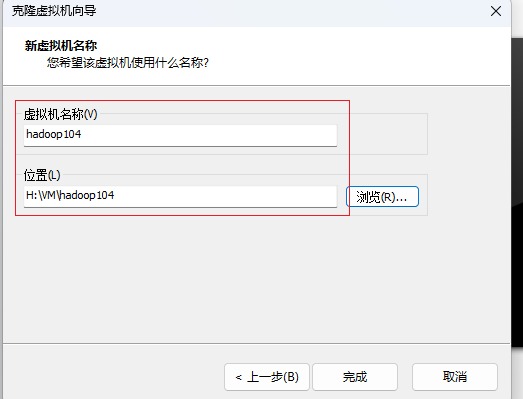
完成后如下图
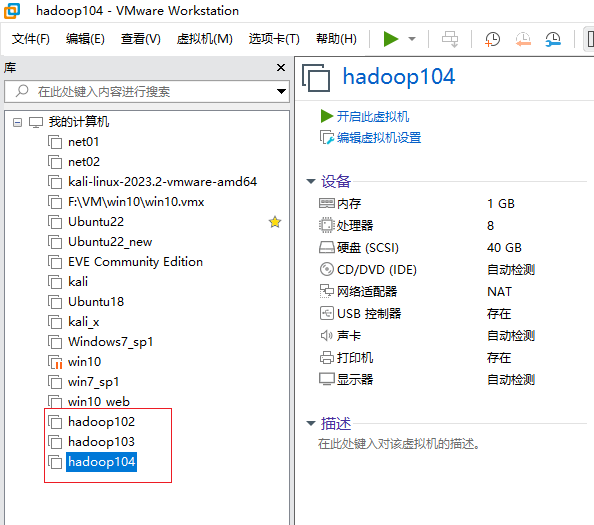
-
配置克隆的网络文件
- 开启hadoop103,切换至root用户
su - root密码是root
- 编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33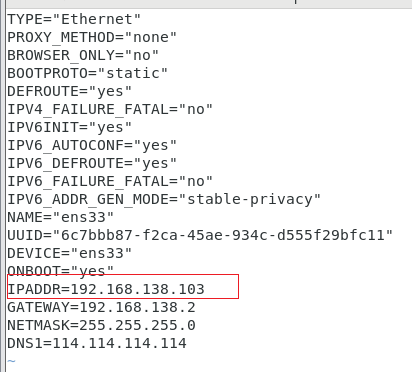
保存退出
- 重启
reboot- 开启hadoop104
- 切换至root用户
su - root- 编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33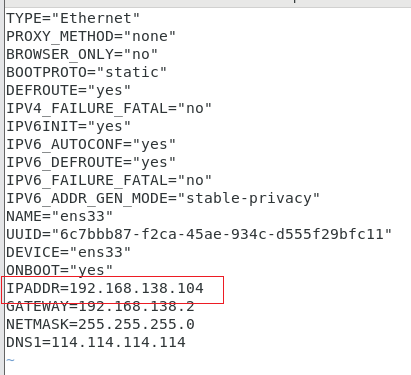
保存退出
- 重启hadoop104
reboot -
启动hadoop102
确保3台节点启动成功
-
打开xshell,新建两个会话
- hadoop103会话
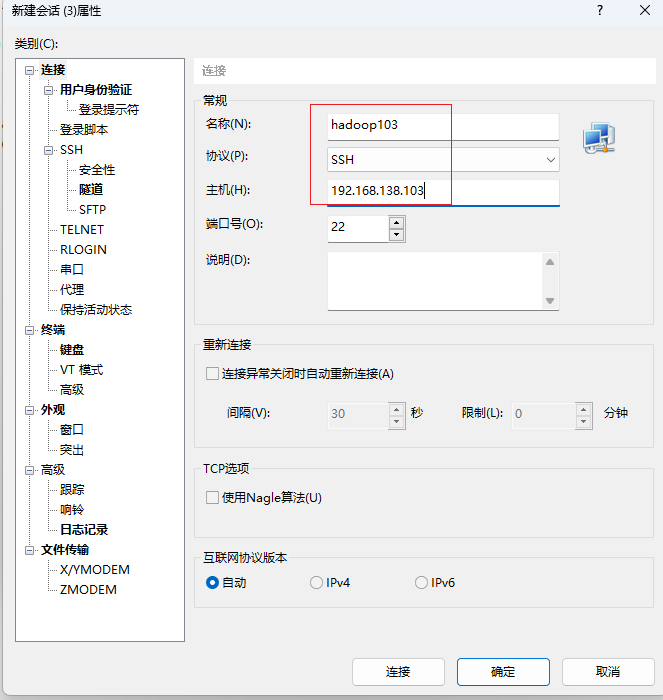
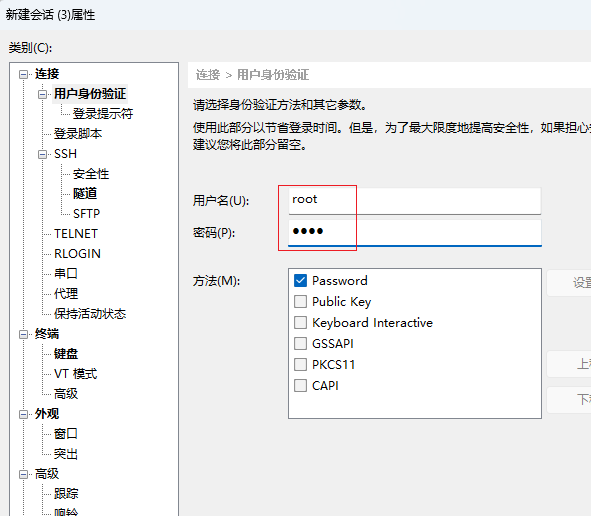
点击确定
- hadoop104会话
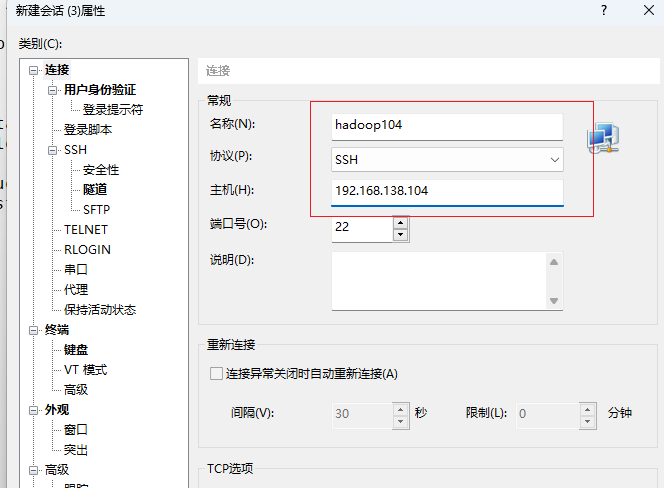
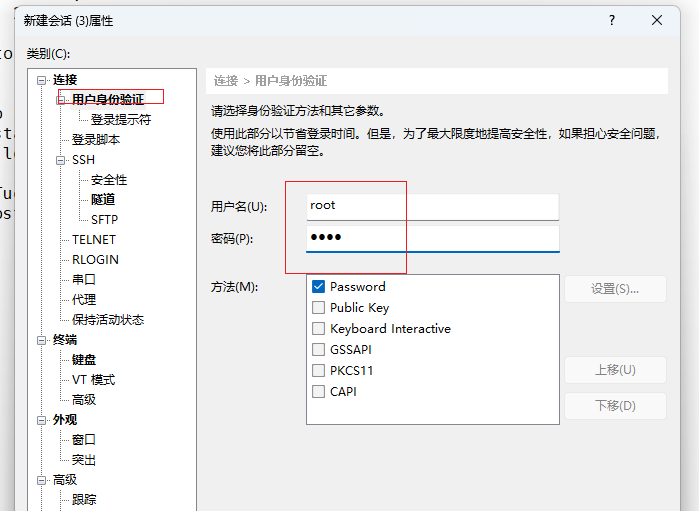
点击确定
- 连接
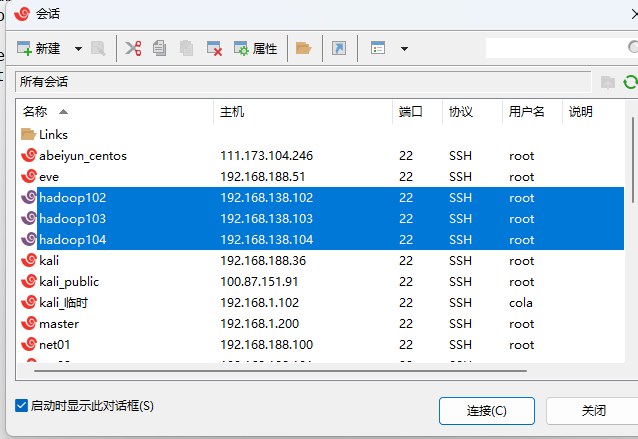
选中3个会话,点击连接
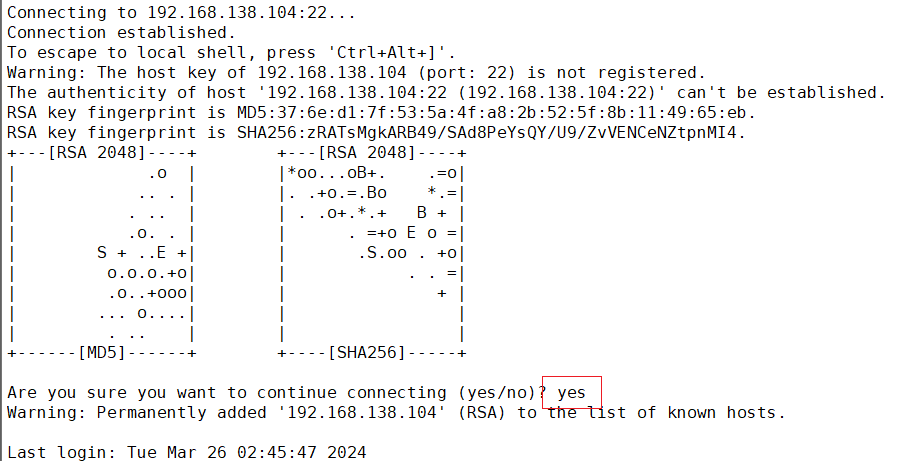
弹出如下提示,输入yes即可
搭建hadoop3.x完全分布式集群
集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| namenode | resourcemanager | datanode |
| datanode | datanode | nodemanager |
| nodemanager | nodemanager | secondarynamenode |
-
配置host映射
- 点击hadoop102选项卡
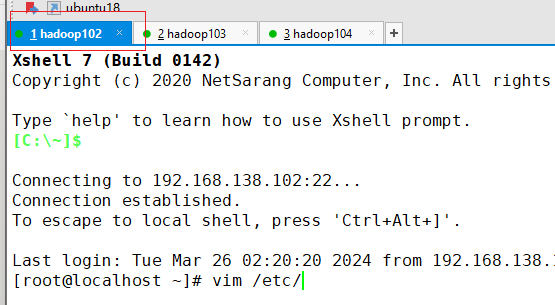
- 编辑hosts文件
vim /etc/hosts192.168.138.102 hadoop102 192.168.138.103 hadoop103 192.168.138.104 hadoop104
保存退出
-
配置集群ssh
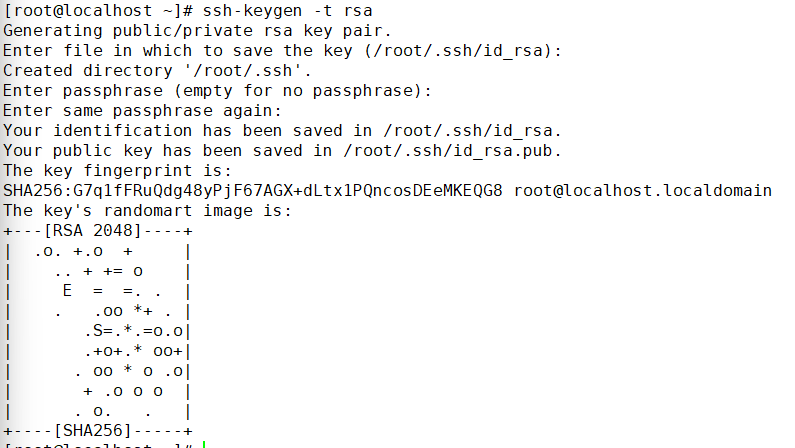
- hadoop102配置ssh无密登录
ssh-keygen -t rsa一直回车即可
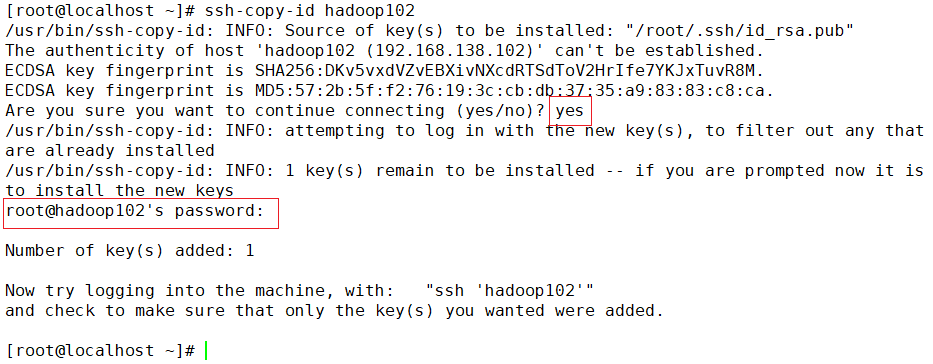
ssh-copy-id hadoop102输入yes,提示输入密码的地方输入root,这里也是没有回显的!!
如上操作再将公钥复制到hadoop103、hadoop104
ssh-copy-id hadoop103ssh-copy-id hadoop104- 分发hosts
xsync /etc/hosts- hadoop103配置ssh无密登录
点击hadoop103选项卡
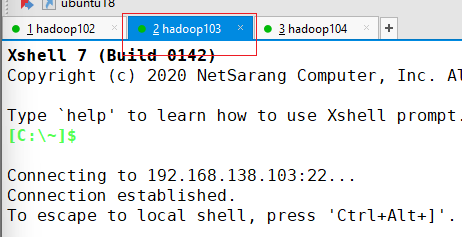
生成公钥
ssh-keygen -t rsa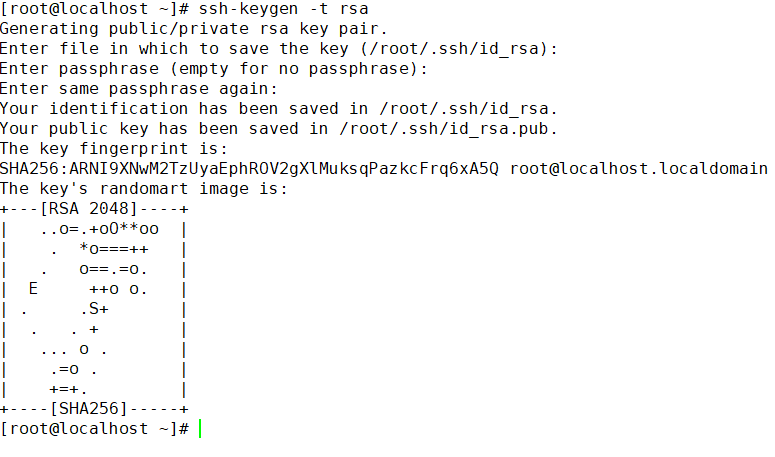
如hadoop102的操作,将公钥复制到其他节点
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104- hadoop104配置ssh无密登录
选择hadoop104选项卡
生成公钥
ssh-keygen -t rsa复制公钥到其他节点
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104 -
上传hadoop安装包
- 回到hadoop102选项卡
创建目录
mkdir /opt/software && cd /opt/software- 上传安装包
开启xftp

将下载好的hadoop和jdk移动到右边
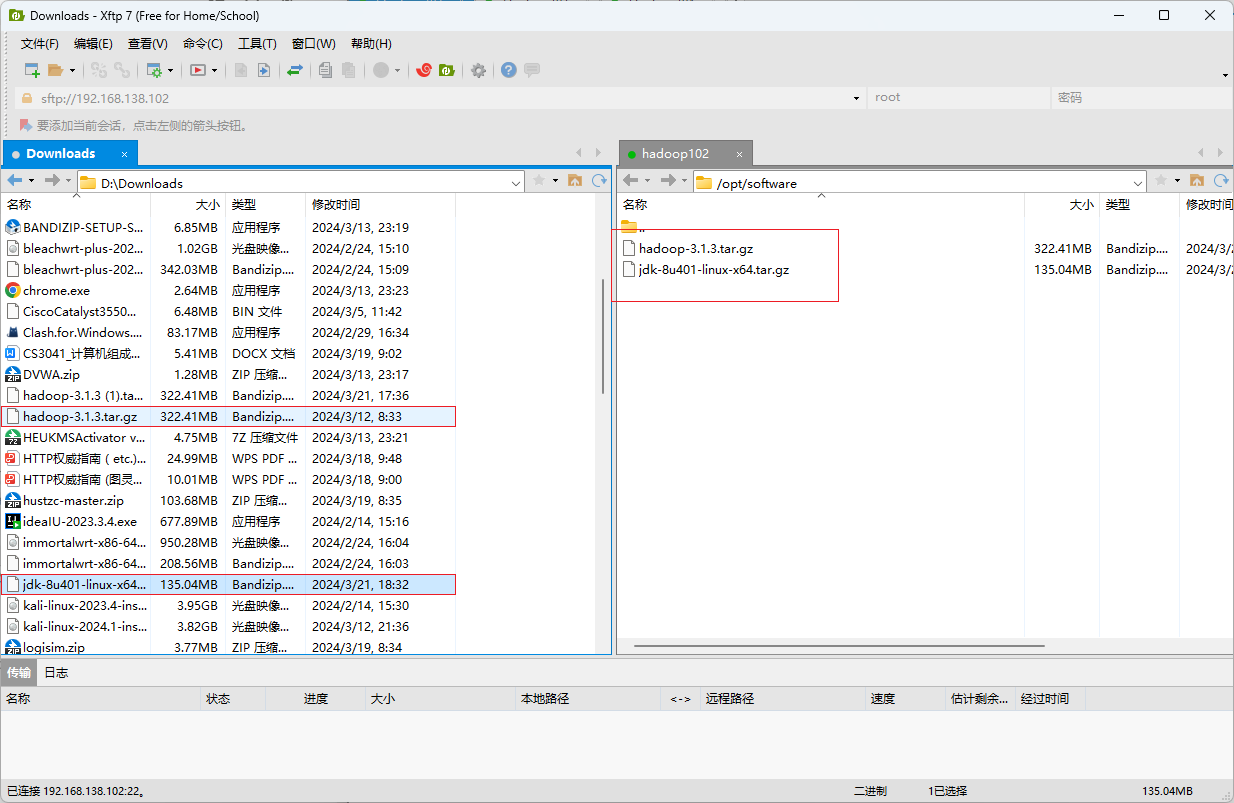
回到xshell
- 创建目录并解压
mkdir /opt/moduletar -zxvf /opt/software/hadoop-3.1.3.tar.gz -c /opt/module/tar -zxvf /opt/software/jdk-8u401-linux-x64.tar.gz -c /opt/module/- 改名
mv /opt/module/jdk1.8.0_401/ /opt/module/jdk -
添加java_home
- 添加java环境变量
vim /etc/profile#java\_home export java\_home=/opt/module/jdk export path=$path:$java\_home/bin -
添加hadoop_home
- 添加hadoop环境变量
#hadoop\_home export hadoop\_home=/opt/module/hadoop export path=$path:$hadoop\_home/bin export path=$path:$hadoop\_home/sbin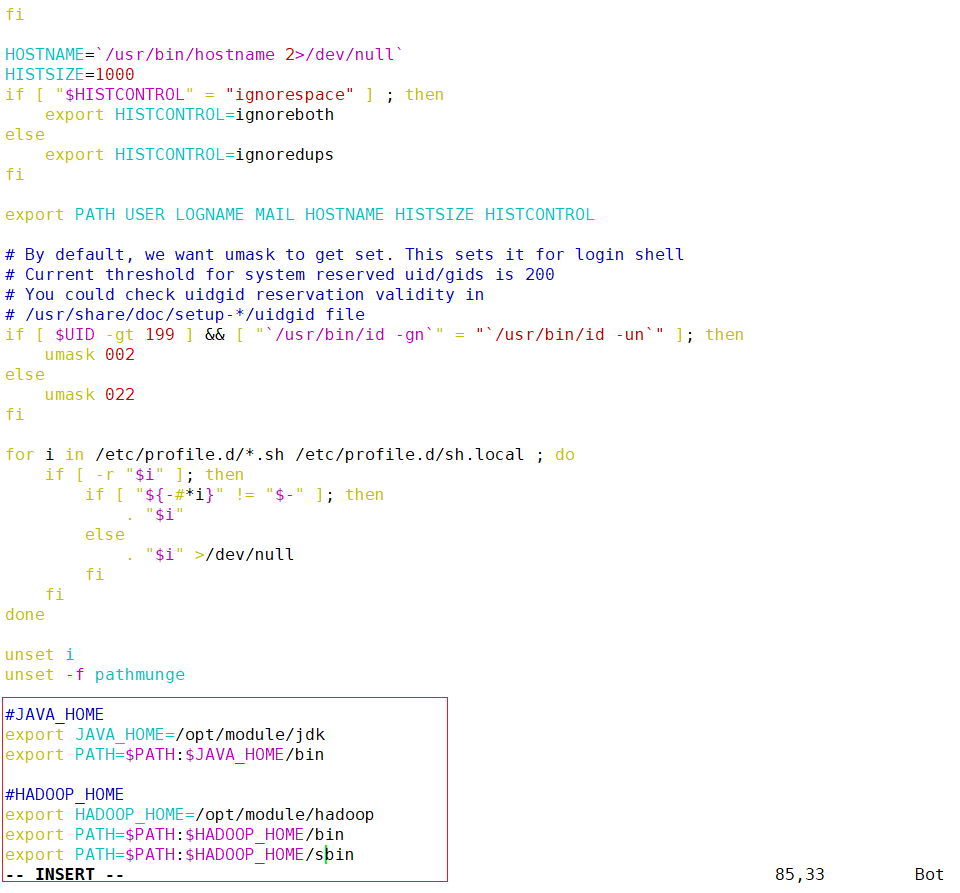
保存退出
- 刷新环境变量
source /etc/profile- 分发环境变量
xsync /etc/profile -
修改配置文件
- 改名
mv /opt/module/hadoop-3.1.3/ /opt/module/hadoop- core-site.xml
vim /opt/module/hadoop/etc/hadoop/core-site.xml<configuration> <property> <name>fs.defaultfs</name> <value>hdfs://hadoop102:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop/data</value> </property> </configuration>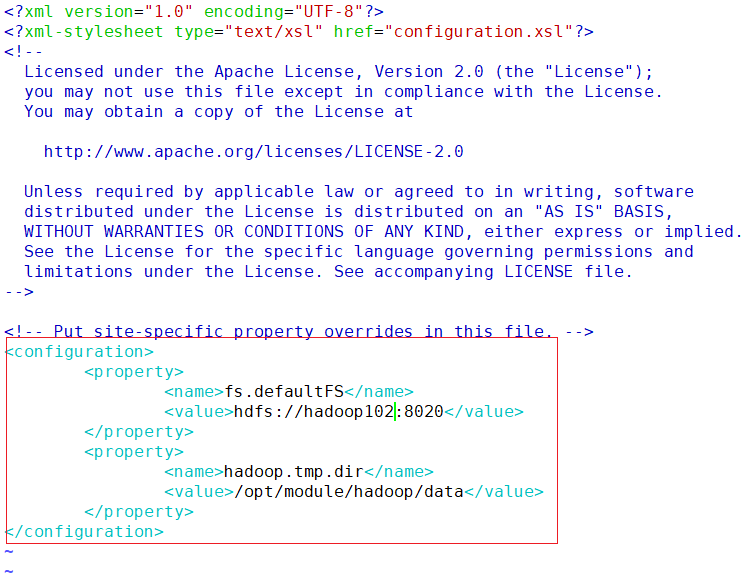
保存退出
- hdfs-site.xml
vim /opt/module/hadoop/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration>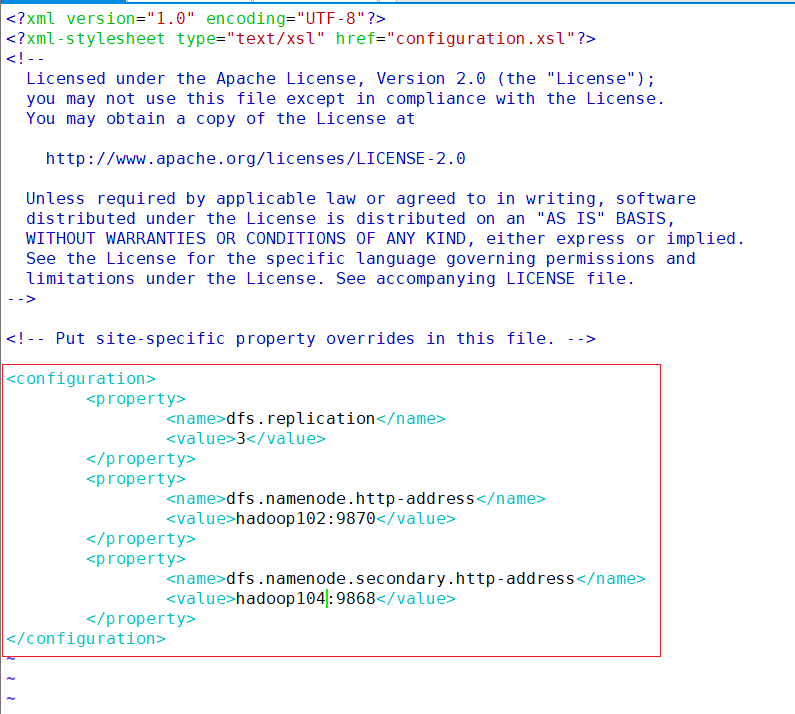
- yarn-site.xml
vim /opt/module/hadoop/etc/hadoop/yarn-site.xml<configuration> <!-- site specific yarn configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> </configuration>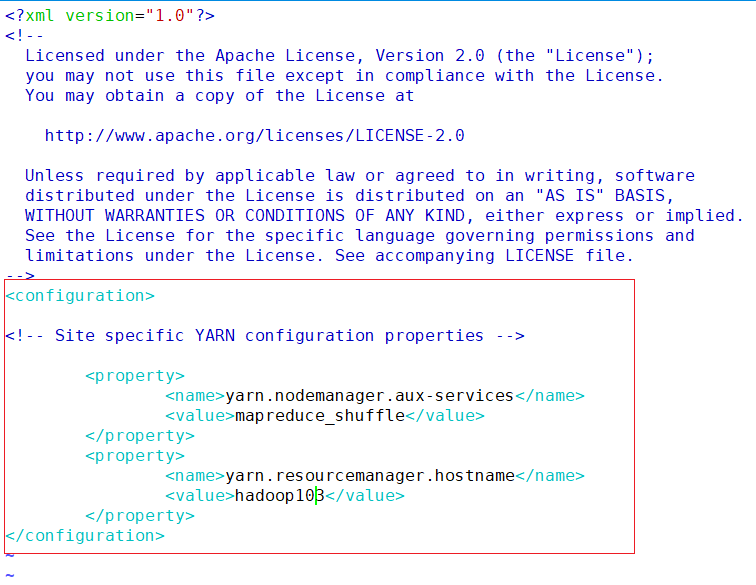
- mapred-site.xml
vim /opt/module/hadoop/etc/hadoop/mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> </configuration>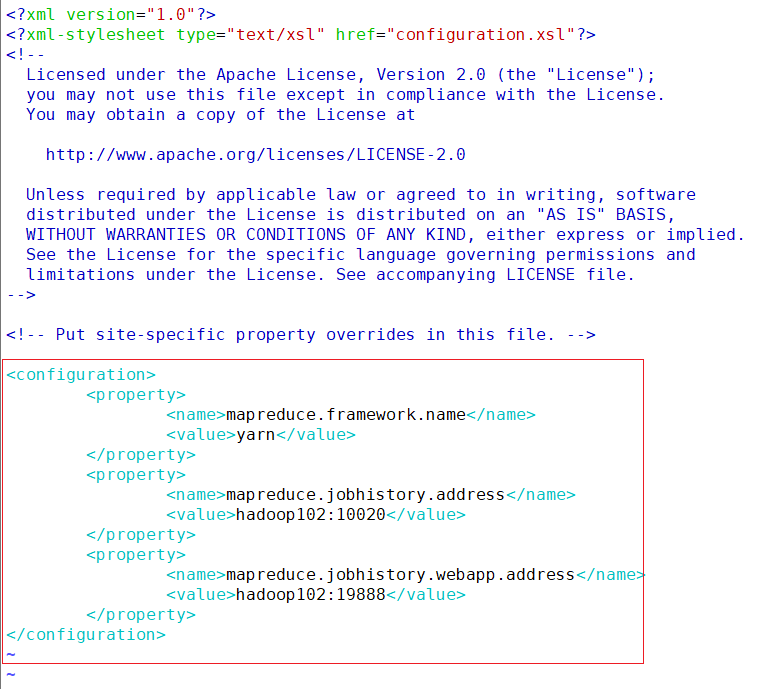
- 在hadoop-env.sh配置java环境变量
vim /opt/module/hadoop/etc/hadoop/hadoop-env.sh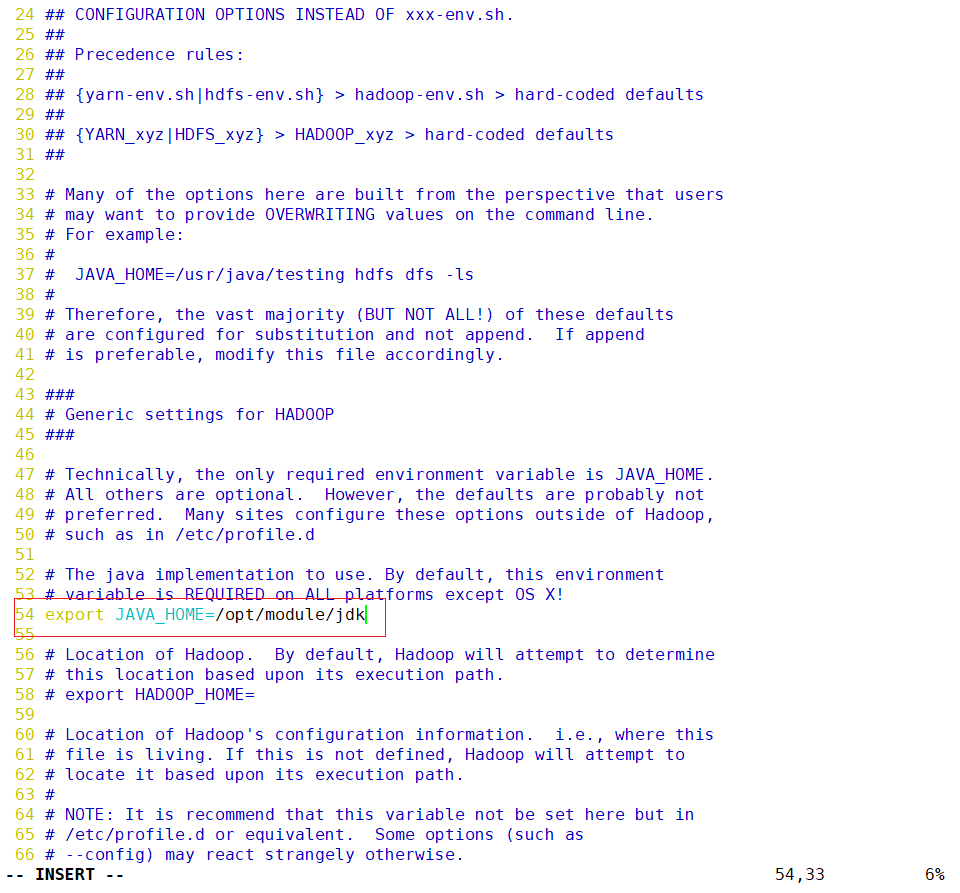
保存退出
- 在sbin/start-dfs.sh , sbin/stop-dfs.sh 两个文件顶部添加以下参数
vim /opt/module/hadoop/sbin/start-dfs.shhdfs\_datanode\_user=root hadoop\_secure\_dn\_user=hdfs hdfs\_namenode\_user=root hdfs\_secondarynamenode\_user=root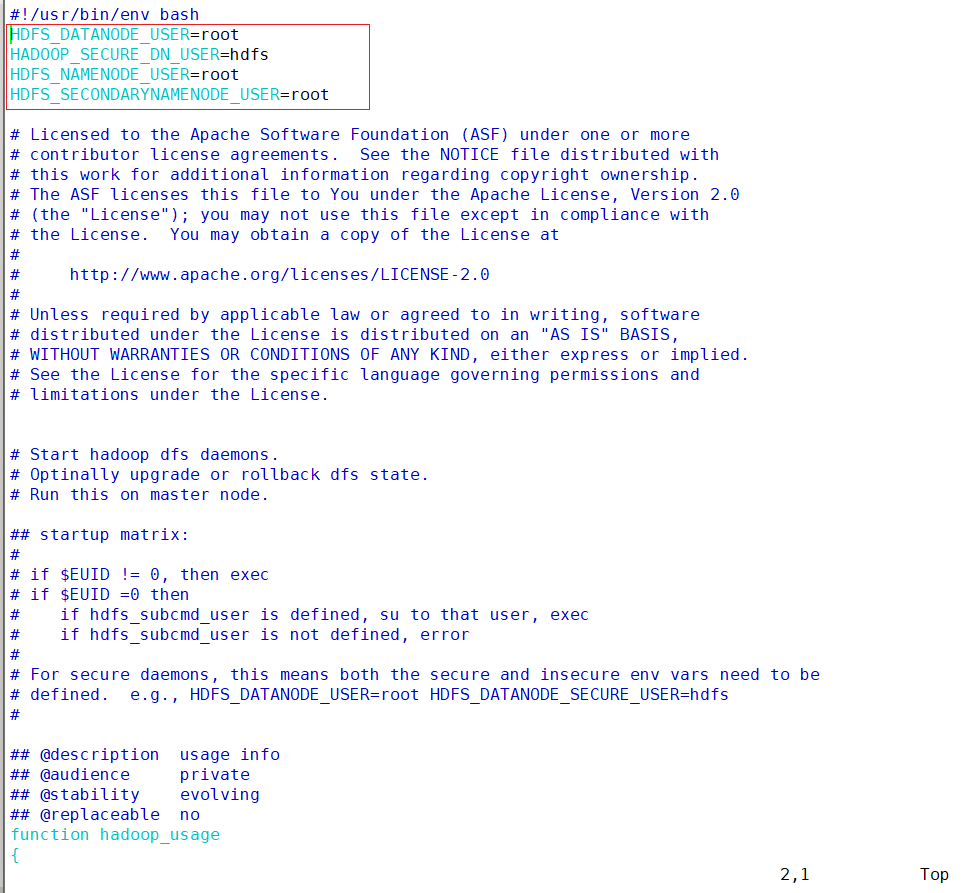
vim /opt/module/hadoop/sbin/stop-dfs.sh#!/usr/bin/env bash hdfs\_datanode\_user=root hadoop\_secure\_dn\_user=hdfs hdfs\_namenode\_user=root hdfs\_secondarynamenode\_user=root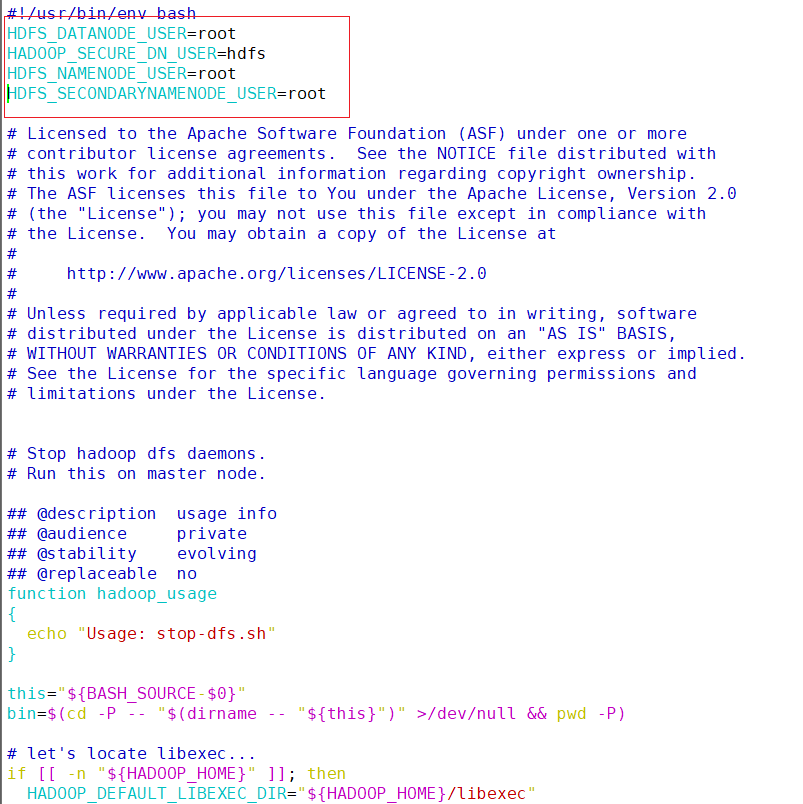
- 在sbin/start-yarn.sh , sbin/stop-yarn.sh两个文件顶部添加以下参数
vim /opt/module/hadoop/sbin/start-yarn.shyarn\_resourcemanager\_user=root hadoop\_secure\_dn\_user=yarn yarn\_nodemanager\_user=root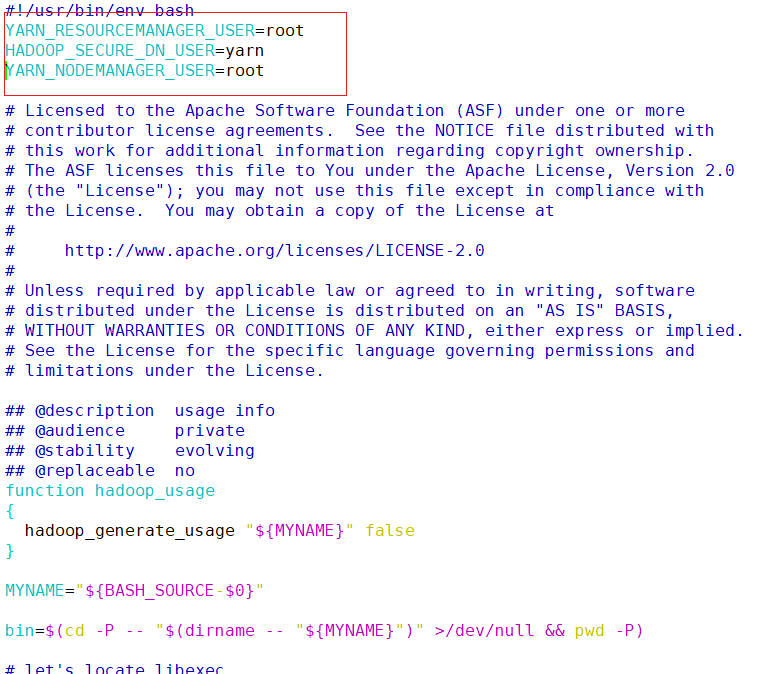
vim /opt/module/hadoop/sbin/stop-yarn.shyarn\_resourcemanager\_user=root
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

```
vim /opt/module/hadoop/sbin/stop-yarn.sh
```
```
yarn\_resourcemanager\_user=root
[外链图片转存中…(img-lvbmujva-1714777291206)]
[外链图片转存中…(img-fjzcnd1z-1714777291206)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!



发表评论